 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning of Neural Collision Handler for Complex 3D Mesh Deformations
Oct 08, 2021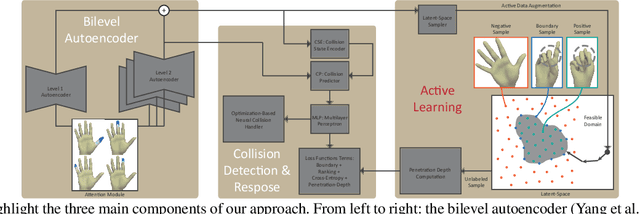
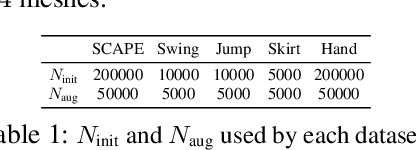
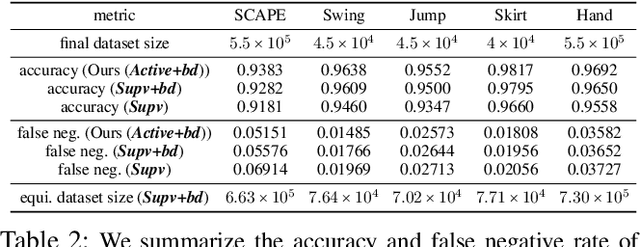
We present a robust learning algorithm to detect and handle collisions in 3D deforming meshes. Our collision detector is represented as a bilevel deep autoencoder with an attention mechanism that identifies colliding mesh sub-parts. We use a numerical optimization algorithm to resolve penetrations guided by the network. Our learned collision handler can resolve collisions for unseen, high-dimensional meshes with thousands of vertices. To obtain stable network performance in such large and unseen spaces, we progressively insert new collision data based on the errors in network inferences. We automatically label these data using an analytical collision detector and progressively fine-tune our detection networks. We evaluate our method for collision handling of complex, 3D meshes coming from several datasets with different shapes and topologies, including datasets corresponding to dressed and undressed human poses, cloth simulations, and human hand poses acquired using multiview capture systems. Our approach outperforms supervised learning methods and achieves $93.8-98.1\%$ accuracy compared to the groundtruth by analytic methods. Compared to prior learning methods, our approach results in a $5.16\%-25.50\%$ lower false negative rate in terms of collision checking and a $9.65\%-58.91\%$ higher success rate in collision handling.
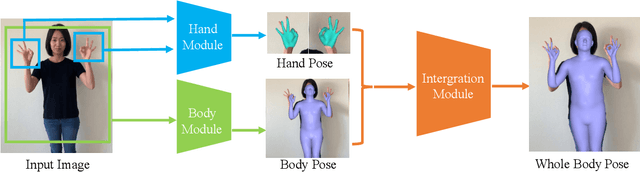
FrankMocap: A Monocular 3D Whole-Body Pose Estimation System via Regression and Integration
Aug 13, 2021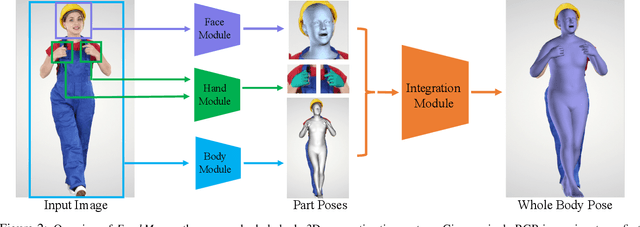
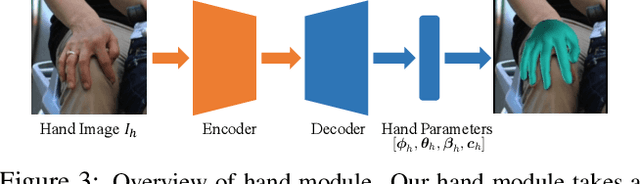
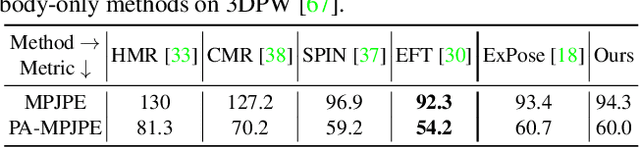

Most existing monocular 3D pose estimation approaches only focus on a single body part, neglecting the fact that the essential nuance of human motion is conveyed through a concert of subtle movements of face, hands, and body. In this paper, we present FrankMocap, a fast and accurate whole-body 3D pose estimation system that can produce 3D face, hands, and body simultaneously from in-the-wild monocular images. The core idea of FrankMocap is its modular design: We first run 3D pose regression methods for face, hands, and body independently, followed by composing the regression outputs via an integration module. The separate regression modules allow us to take full advantage of their state-of-the-art performances without compromising the original accuracy and reliability in practice. We develop three different integration modules that trade off between latency and accuracy. All of them are capable of providing simple yet effective solutions to unify the separate outputs into seamless whole-body pose estimation results. We quantitatively and qualitatively demonstrate that our modularized system outperforms both the optimization-based and end-to-end methods of estimating whole-body pose.
Driving-Signal Aware Full-Body Avatars
May 21, 2021
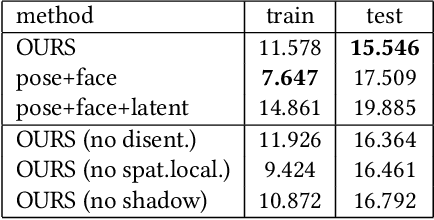
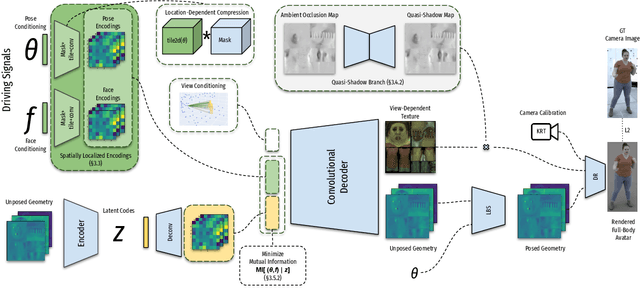
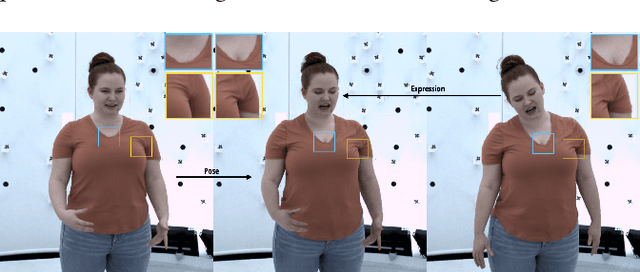
We present a learning-based method for building driving-signal aware full-body avatars. Our model is a conditional variational autoencoder that can be animated with incomplete driving signals, such as human pose and facial keypoints, and produces a high-quality representation of human geometry and view-dependent appearance. The core intuition behind our method is that better drivability and generalization can be achieved by disentangling the driving signals and remaining generative factors, which are not available during animation. To this end, we explicitly account for information deficiency in the driving signal by introducing a latent space that exclusively captures the remaining information, thus enabling the imputation of the missing factors required during full-body animation, while remaining faithful to the driving signal. We also propose a learnable localized compression for the driving signal which promotes better generalization, and helps minimize the influence of global chance-correlations often found in real datasets. For a given driving signal, the resulting variational model produces a compact space of uncertainty for missing factors that allows for an imputation strategy best suited to a particular application. We demonstrate the efficacy of our approach on the challenging problem of full-body animation for virtual telepresence with driving signals acquired from minimal sensors placed in the environment and mounted on a VR-headset.
InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
Aug 21, 2020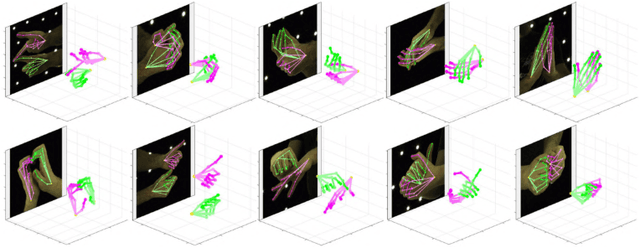
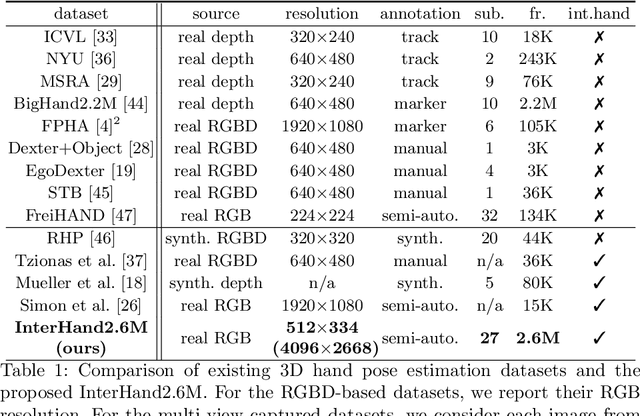

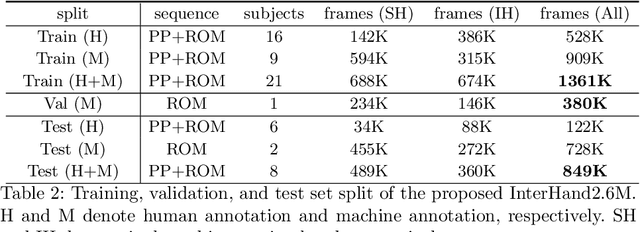
Analysis of hand-hand interactions is a crucial step towards better understanding human behavior. However, most researches in 3D hand pose estimation have focused on the isolated single hand case. Therefore, we firstly propose (1) a large-scale dataset, InterHand2.6M, and (2) a baseline network, InterNet, for 3D interacting hand pose estimation from a single RGB image. The proposed InterHand2.6M consists of \textbf{2.6M labeled single and interacting hand frames} under various poses from multiple subjects. Our InterNet simultaneously performs 3D single and interacting hand pose estimation. In our experiments, we demonstrate big gains in 3D interacting hand pose estimation accuracy when leveraging the interacting hand data in InterHand2.6M. We also report the accuracy of InterNet on InterHand2.6M, which serves as a strong baseline for this new dataset. Finally, we show 3D interacting hand pose estimation results from general images. Our code and dataset are available at https://mks0601.github.io/InterHand2.6M/.
FrankMocap: Fast Monocular 3D Hand and Body Motion Capture by Regression and Integration
Aug 19, 2020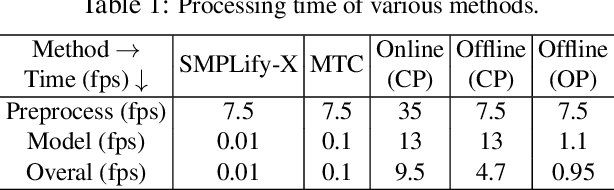
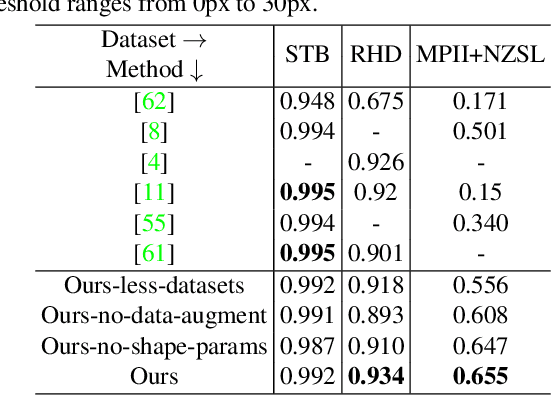
Although the essential nuance of human motion is often conveyed as a combination of body movements and hand gestures, the existing monocular motion capture approaches mostly focus on either body motion capture only ignoring hand parts or hand motion capture only without considering body motion. In this paper, we present FrankMocap, a motion capture system that can estimate both 3D hand and body motion from in-the-wild monocular inputs with faster speed (9.5 fps) and better accuracy than previous work. Our method works in near real-time (9.5 fps) and produces 3D body and hand motion capture outputs as a unified parametric model structure. Our method aims to capture 3D body and hand motion simultaneously from challenging in-the-wild monocular videos. To construct FrankMocap, we build the state-of-the-art monocular 3D "hand" motion capture method by taking the hand part of the whole body parametric model (SMPL-X). Our 3D hand motion capture output can be efficiently integrated to monocular body motion capture output, producing whole body motion results in a unified parrametric model structure. We demonstrate the state-of-the-art performance of our hand motion capture system in public benchmarks, and show the high quality of our whole body motion capture result in various challenging real-world scenes, including a live demo scenario.
DeepHandMesh: A Weakly-supervised Deep Encoder-Decoder Framework for High-fidelity Hand Mesh Modeling
Aug 19, 2020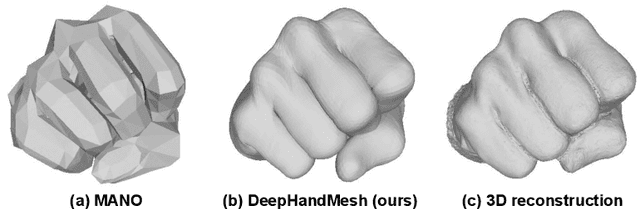

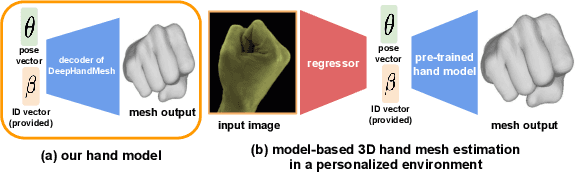
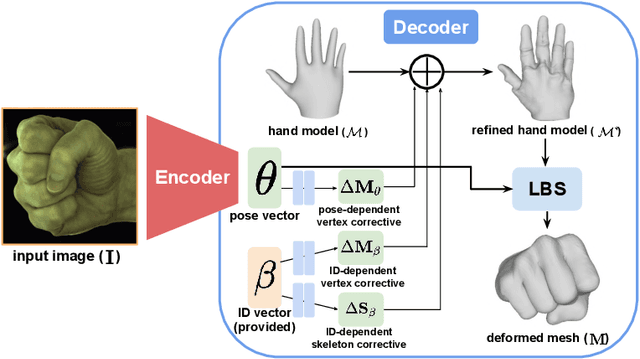
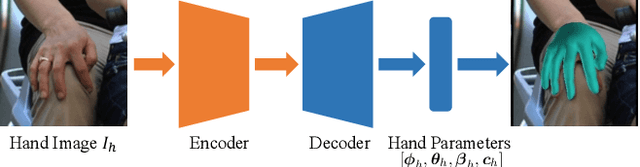
Human hands play a central role in interacting with other people and objects. For realistic replication of such hand motions, high-fidelity hand meshes have to be reconstructed. In this study, we firstly propose DeepHandMesh, a weakly-supervised deep encoder-decoder framework for high-fidelity hand mesh modeling. We design our system to be trained in an end-to-end and weakly-supervised manner; therefore, it does not require groundtruth meshes. Instead, it relies on weaker supervisions such as 3D joint coordinates and multi-view depth maps, which are easier to get than groundtruth meshes and do not dependent on the mesh topology. Although the proposed DeepHandMesh is trained in a weakly-supervised way, it provides significantly more realistic hand mesh than previous fully-supervised hand models. Our newly introduced penetration avoidance loss further improves results by replicating physical interaction between hand parts. Finally, we demonstrate that our system can also be applied successfully to the 3D hand mesh estimation from general images. Our hand model, dataset, and codes are publicly available at https://mks0601.github.io/DeepHandMesh/.
Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking
Jul 25, 2019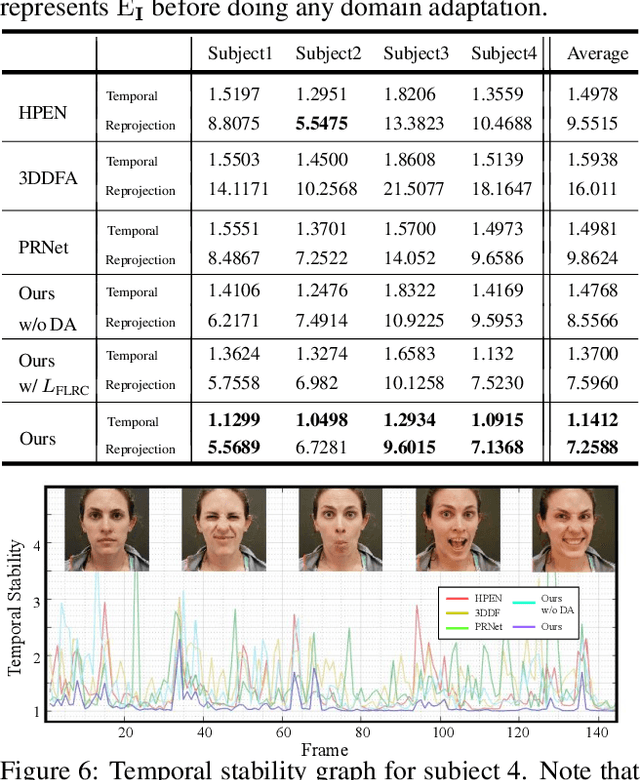
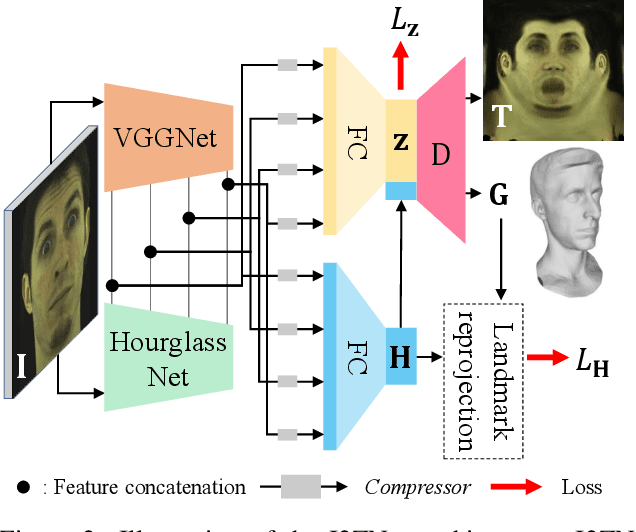
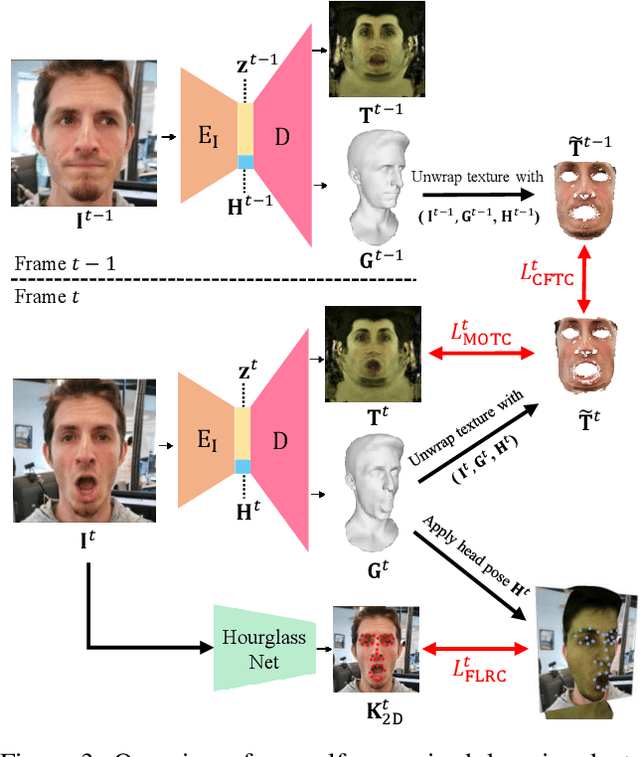
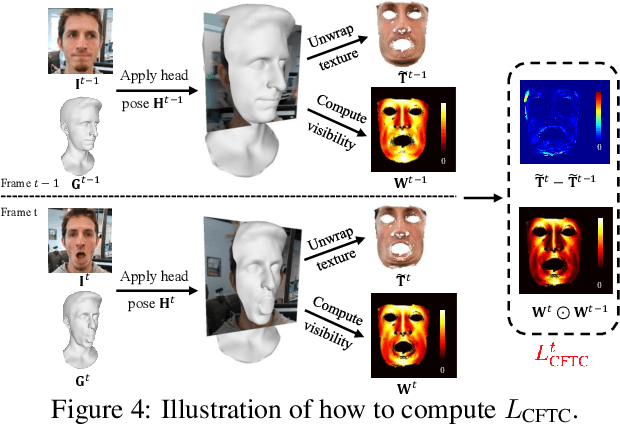
Improvements in data-capture and face modeling techniques have enabled us to create high-fidelity realistic face models. However, driving these realistic face models requires special input data, e.g. 3D meshes and unwrapped textures. Also, these face models expect clean input data taken under controlled lab environments, which is very different from data collected in the wild. All these constraints make it challenging to use the high-fidelity models in tracking for commodity cameras. In this paper, we propose a self-supervised domain adaptation approach to enable the animation of high-fidelity face models from a commodity camera. Our approach first circumvents the requirement for special input data by training a new network that can directly drive a face model just from a single 2D image. Then, we overcome the domain mismatch between lab and uncontrolled environments by performing self-supervised domain adaptation based on "consecutive frame texture consistency" based on the assumption that the appearance of the face is consistent over consecutive frames, avoiding the necessity of modeling the new environment such as lighting or background. Experiments show that we are able to drive a high-fidelity face model to perform complex facial motion from a cellphone camera without requiring any labeled data from the new domain.