 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Model-Based Control for Industrial box-packing of Multiple Objects using NewtonianVAE
Aug 04, 2023



The process of industrial box-packing, which involves the accurate placement of multiple objects, requires high-accuracy positioning and sequential actions. When a robot is tasked with placing an object at a specific location with high accuracy, it is important not only to have information about the location of the object to be placed, but also the posture of the object grasped by the robotic hand. Often, industrial box-packing requires the sequential placement of identically shaped objects into a single box. The robot's action should be determined by the same learned model. In factories, new kinds of products often appear and there is a need for a model that can easily adapt to them. Therefore, it should be easy to collect data to train the model. In this study, we designed a robotic system to automate real-world industrial tasks, employing a vision-based learning control model. We propose in-hand-view-sensitive Newtonian variational autoencoder (ihVS-NVAE), which employs an RGB camera to obtain in-hand postures of objects. We demonstrate that our model, trained for a single object-placement task, can handle sequential tasks without additional training. To evaluate efficacy of the proposed model, we employed a real robot to perform sequential industrial box-packing of multiple objects. Results showed that the proposed model achieved a 100% success rate in industrial box-packing tasks, thereby outperforming the state-of-the-art and conventional approaches, underscoring its superior effectiveness and potential in industrial tasks.
Learning Compliant Stiffness by Impedance Control-Aware Task Segmentation and Multi-objective Bayesian Optimization with Priors
Jul 28, 2023



Rather than traditional position control, impedance control is preferred to ensure the safe operation of industrial robots programmed from demonstrations. However, variable stiffness learning studies have focused on task performance rather than safety (or compliance). Thus, this paper proposes a novel stiffness learning method to satisfy both task performance and compliance requirements. The proposed method optimizes the task and compliance objectives (T/C objectives) simultaneously via multi-objective Bayesian optimization. We define the stiffness search space by segmenting a demonstration into task phases, each with constant responsible stiffness. The segmentation is performed by identifying impedance control-aware switching linear dynamics (IC-SLD) from the demonstration. We also utilize the stiffness obtained by proposed IC-SLD as priors for efficient optimization. Experiments on simulated tasks and a real robot demonstrate that IC-SLD-based segmentation and the use of priors improve the optimization efficiency compared to existing baseline methods.
Control as Probabilistic Inference as an Emergent Communication Mechanism in Multi-Agent Reinforcement Learning
Jul 11, 2023



This paper proposes a generative probabilistic model integrating emergent communication and multi-agent reinforcement learning. The agents plan their actions by probabilistic inference, called control as inference, and communicate using messages that are latent variables and estimated based on the planned actions. Through these messages, each agent can send information about its actions and know information about the actions of another agent. Therefore, the agents change their actions according to the estimated messages to achieve cooperative tasks. This inference of messages can be considered as communication, and this procedure can be formulated by the Metropolis-Hasting naming game. Through experiments in the grid world environment, we show that the proposed PGM can infer meaningful messages to achieve the cooperative task.
Symbol emergence as interpersonal cross-situational learning: the emergence of lexical knowledge with combinatoriality
Jun 27, 2023



We present a computational model for a symbol emergence system that enables the emergence of lexical knowledge with combinatoriality among agents through a Metropolis-Hastings naming game and cross-situational learning. Many computational models have been proposed to investigate combinatoriality in emergent communication and symbol emergence in cognitive and developmental robotics. However, existing models do not sufficiently address category formation based on sensory-motor information and semiotic communication through the exchange of word sequences within a single integrated model. Our proposed model facilitates the emergence of lexical knowledge with combinatoriality by performing category formation using multimodal sensory-motor information and enabling semiotic communication through the exchange of word sequences among agents in a unified model. Furthermore, the model enables an agent to predict sensory-motor information for unobserved situations by combining words associated with categories in each modality. We conducted two experiments with two humanoid robots in a simulated environment to evaluate our proposed model. The results demonstrated that the agents can acquire lexical knowledge with combinatoriality through interpersonal cross-situational learning based on the Metropolis-Hastings naming game and cross-situational learning. Furthermore, our results indicate that the lexical knowledge developed using our proposed model exhibits generalization performance for novel situations through interpersonal cross-modal inference.
Metropolis-Hastings algorithm in joint-attention naming game: Experimental semiotics study
May 31, 2023



In this study, we explore the emergence of symbols during interactions between individuals through an experimental semiotic study. Previous studies investigate how humans organize symbol systems through communication using artificially designed subjective experiments. In this study, we have focused on a joint attention-naming game (JA-NG) in which participants independently categorize objects and assign names while assuming their joint attention. In the theory of the Metropolis-Hastings naming game (MHNG), listeners accept provided names according to the acceptance probability computed using the Metropolis-Hastings (MH) algorithm. The theory of MHNG suggests that symbols emerge as an approximate decentralized Bayesian inference of signs, which is represented as a shared prior variable if the conditions of MHNG are satisfied. This study examines whether human participants exhibit behavior consistent with MHNG theory when playing JA-NG. By comparing human acceptance decisions of a partner's naming with acceptance probabilities computed in the MHNG, we tested whether human behavior is consistent with the MHNG theory. The main contributions of this study are twofold. First, we reject the null hypothesis that humans make acceptance judgments with a constant probability, regardless of the acceptance probability calculated by the MH algorithm. This result suggests that people followed the acceptance probability computed by the MH algorithm to some extent. Second, the MH-based model predicted human acceptance/rejection behavior more accurately than the other four models: Constant, Numerator, Subtraction, and Binary. This result indicates that symbol emergence in JA-NG can be explained using MHNG and is considered an approximate decentralized Bayesian inference.
Recursive Metropolis-Hastings Naming Game: Symbol Emergence in a Multi-agent System based on Probabilistic Generative Models
May 31, 2023



In the studies on symbol emergence and emergent communication in a population of agents, a computational model was employed in which agents participate in various language games. Among these, the Metropolis-Hastings naming game (MHNG) possesses a notable mathematical property: symbol emergence through MHNG is proven to be a decentralized Bayesian inference of representations shared by the agents. However, the previously proposed MHNG is limited to a two-agent scenario. This paper extends MHNG to an N-agent scenario. The main contributions of this paper are twofold: (1) we propose the recursive Metropolis-Hastings naming game (RMHNG) as an N-agent version of MHNG and demonstrate that RMHNG is an approximate Bayesian inference method for the posterior distribution over a latent variable shared by agents, similar to MHNG; and (2) we empirically evaluate the performance of RMHNG on synthetic and real image data, enabling multiple agents to develop and share a symbol system. Furthermore, we introduce two types of approximations -- one-sample and limited-length -- to reduce computational complexity while maintaining the ability to explain communication in a population of agents. The experimental findings showcased the efficacy of RMHNG as a decentralized Bayesian inference for approximating the posterior distribution concerning latent variables, which are jointly shared among agents, akin to MHNG. Moreover, the utilization of RMHNG elucidated the agents' capacity to exchange symbols. Furthermore, the study discovered that even the computationally simplified version of RMHNG could enable symbols to emerge among the agents.
Online Re-Planning and Adaptive Parameter Update for Multi-Agent Path Finding with Stochastic Travel Times
Feb 03, 2023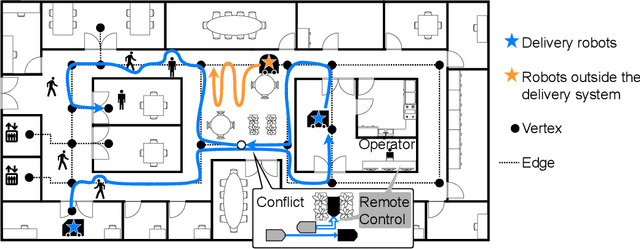
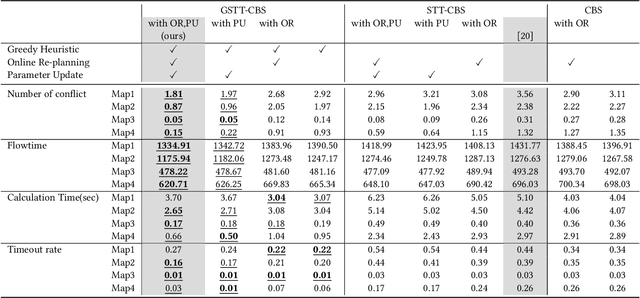
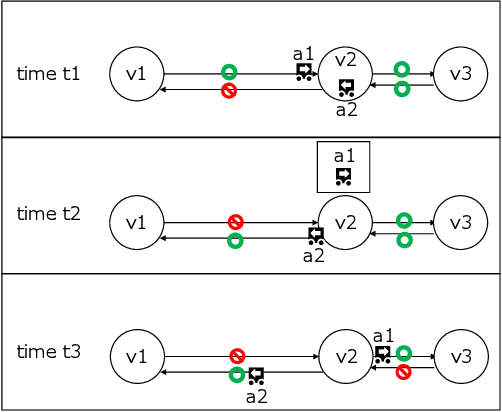
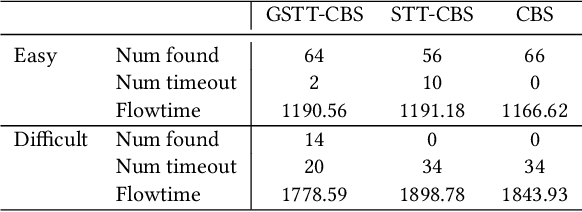
This study explores the problem of Multi-Agent Path Finding with continuous and stochastic travel times whose probability distribution is unknown. Our purpose is to manage a group of automated robots that provide package delivery services in a building where pedestrians and a wide variety of robots coexist, such as delivery services in office buildings, hospitals, and apartments. It is often the case with these real-world applications that the time required for the robots to traverse a corridor takes a continuous value and is randomly distributed, and the prior knowledge of the probability distribution of the travel time is limited. Multi-Agent Path Finding has been widely studied and applied to robot management systems; however, automating the robot operation in such environments remains difficult. We propose 1) online re-planning to update the action plan of robots while it is executed, and 2) parameter update to estimate the probability distribution of travel time using Bayesian inference as the delay is observed. We use a greedy heuristic to obtain solutions in a limited computation time. Through simulations, we empirically compare the performance of our method to those of existing methods in terms of the conflict probability and the actual travel time of robots. The simulation results indicate that the proposed method can find travel paths with at least 50% fewer conflicts and a shorter actual total travel time than existing methods. The proposed method requires a small number of trials to achieve the performance because the parameter update is prioritized on the important edges for path planning, thereby satisfying the requirements of quick implementation of robust planning of automated delivery services.
Goal-Image Conditioned Dynamic Cable Manipulation through Bayesian Inference and Multi-Objective Black-Box Optimization
Jan 27, 2023



To perform dynamic cable manipulation to realize the configuration specified by a target image, we formulate dynamic cable manipulation as a stochastic forward model. Then, we propose a method to handle uncertainty by maximizing the expectation, which also considers estimation errors of the trained model. To avoid issues like multiple local minima and requirement of differentiability by gradient-based methods, we propose using a black-box optimization (BBO) to optimize joint angles to realize a goal image. Among BBO, we use the Tree-structured Parzen Estimator (TPE), a type of Bayesian optimization. By incorporating constraints into the TPE, the optimized joint angles are constrained within the range of motion. Since TPE is population-based, it is better able to detect multiple feasible configurations using the estimated inverse model. We evaluated image similarity between the target and cable images captured by executing the robot using optimal transport distance. The results show that the proposed method improves accuracy compared to conventional gradient-based approaches and methods that use deterministic models that do not consider uncertainty.
World Models and Predictive Coding for Cognitive and Developmental Robotics: Frontiers and Challenges
Jan 14, 2023Creating autonomous robots that can actively explore the environment, acquire knowledge and learn skills continuously is the ultimate achievement envisioned in cognitive and developmental robotics. Their learning processes should be based on interactions with their physical and social world in the manner of human learning and cognitive development. Based on this context, in this paper, we focus on the two concepts of world models and predictive coding. Recently, world models have attracted renewed attention as a topic of considerable interest in artificial intelligence. Cognitive systems learn world models to better predict future sensory observations and optimize their policies, i.e., controllers. Alternatively, in neuroscience, predictive coding proposes that the brain continuously predicts its inputs and adapts to model its own dynamics and control behavior in its environment. Both ideas may be considered as underpinning the cognitive development of robots and humans capable of continual or lifelong learning. Although many studies have been conducted on predictive coding in cognitive robotics and neurorobotics, the relationship between world model-based approaches in AI and predictive coding in robotics has rarely been discussed. Therefore, in this paper, we clarify the definitions, relationships, and status of current research on these topics, as well as missing pieces of world models and predictive coding in conjunction with crucially related concepts such as the free-energy principle and active inference in the context of cognitive and developmental robotics. Furthermore, we outline the frontiers and challenges involved in world models and predictive coding toward the further integration of AI and robotics, as well as the creation of robots with real cognitive and developmental capabilities in the future.
Active Exploration based on Information Gain by Particle Filter for Efficient Spatial Concept Formation
Nov 20, 2022Autonomous robots are required to actively and adaptively learn the categories and words of various places by exploring the surrounding environment and interacting with users. In semantic mapping and spatial language acquisition conducted using robots, it is costly and labor-intensive to prepare training datasets that contain linguistic instructions from users. Therefore, we aimed to enable mobile robots to learn spatial concepts through autonomous active exploration. This study is characterized by interpreting the `action' of the robot that asks the user the question `What kind of place is this?' in the context of active inference. We propose an active inference method, spatial concept formation with information gain-based active exploration (SpCoAE), that combines sequential Bayesian inference by particle filters and position determination based on information gain in a probabilistic generative model. Our experiment shows that the proposed method can efficiently determine a position to form appropriate spatial concepts in home environments. In particular, it is important to conduct efficient exploration that leads to appropriate concept formation and quickly covers the environment without adopting a haphazard exploration strategy.