 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Self Modulation for Generative Adversarial Networks
Oct 02, 2018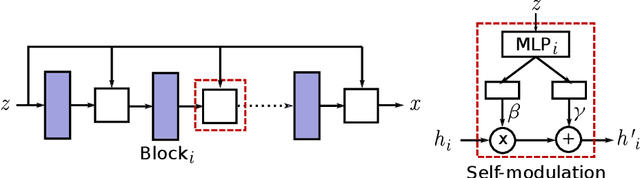

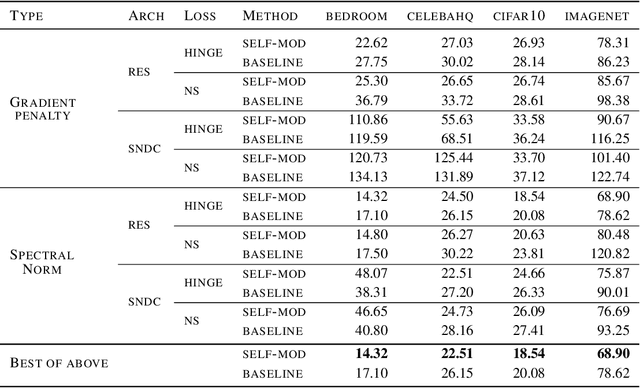
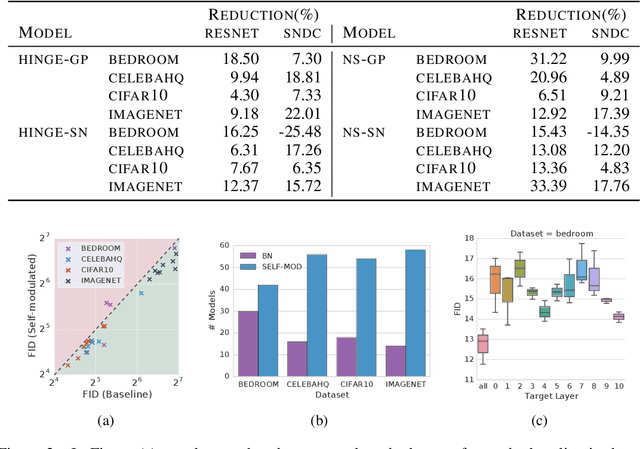
Training Generative Adversarial Networks (GANs) is notoriously challenging. We propose and study an architectural modification, self-modulation, which improves GAN performance across different data sets, architectures, losses, regularizers, and hyperparameter settings. Intuitively, self-modulation allows the intermediate feature maps of a generator to change as a function of the input noise vector. While reminiscent of other conditioning techniques, it requires no labeled data. In a large-scale empirical study we observe a relative decrease of $5\%-35\%$ in FID. Furthermore, all else being equal, adding this modification to the generator leads to improved performance in $124/144$ ($86\%$) of the studied settings. Self-modulation is a simple architectural change that requires no additional parameter tuning, which suggests that it can be applied readily to any GAN.
Clustering Meets Implicit Generative Models
Aug 02, 2018
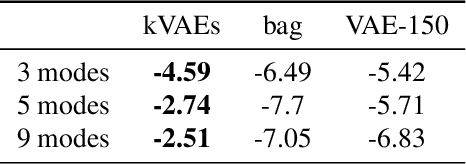
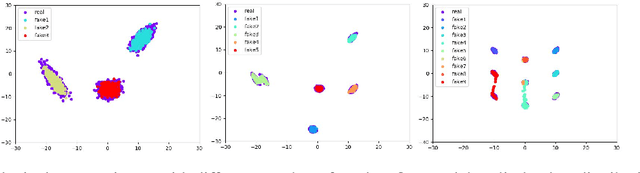
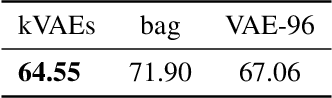
Clustering is a cornerstone of unsupervised learning which can be thought as disentangling the multiple generative mechanisms underlying the data. In this paper we introduce an algorithmic framework to train mixtures of implicit generative models which we instantiate for variational autoencoders. Relying on an additional set of discriminators, we propose a competitive procedure in which the models only need to approximate the portion of the data distribution from which they can produce realistic samples. As a byproduct, each model is simpler to train, and a clustering interpretation arises naturally from the partitioning of the training points among the models. We empirically show that our approach splits the training distribution in a reasonable way and increases the quality of the generated samples.
Temporal Difference Learning with Neural Networks - Study of the Leakage Propagation Problem
Jul 09, 2018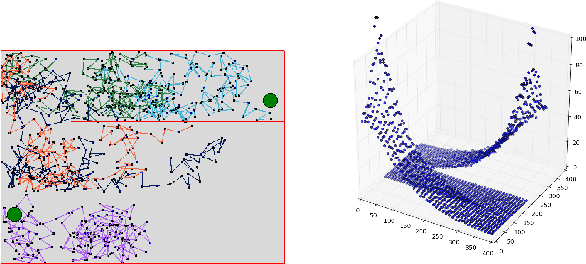
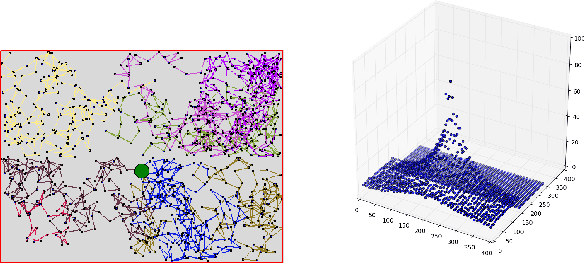
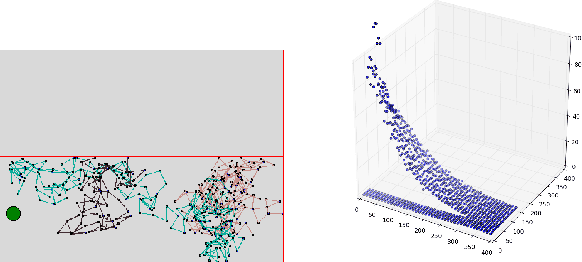
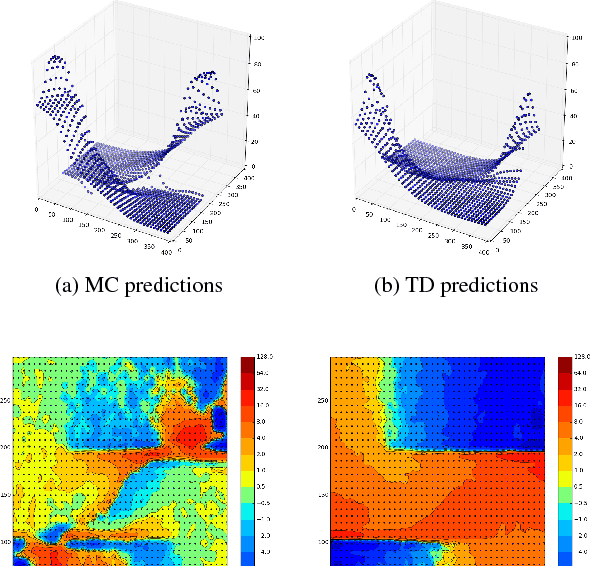
Temporal-Difference learning (TD) [Sutton, 1988] with function approximation can converge to solutions that are worse than those obtained by Monte-Carlo regression, even in the simple case of on-policy evaluation. To increase our understanding of the problem, we investigate the issue of approximation errors in areas of sharp discontinuities of the value function being further propagated by bootstrap updates. We show empirical evidence of this leakage propagation, and show analytically that it must occur, in a simple Markov chain, when function approximation errors are present. For reversible policies, the result can be interpreted as the tension between two terms of the loss function that TD minimises, as recently described by [Ollivier, 2018]. We show that the upper bounds from [Tsitsiklis and Van Roy, 1997] hold, but they do not imply that leakage propagation occurs and under what conditions. Finally, we test whether the problem could be mitigated with a better state representation, and whether it can be learned in an unsupervised manner, without rewards or privileged information.
On Accurate Evaluation of GANs for Language Generation
Jun 14, 2018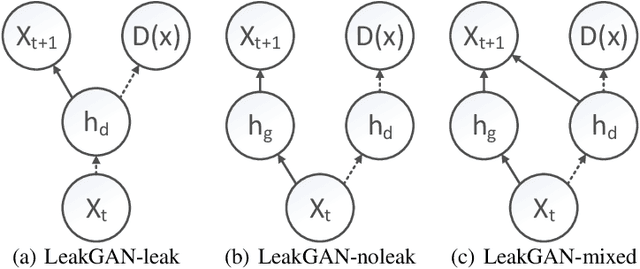
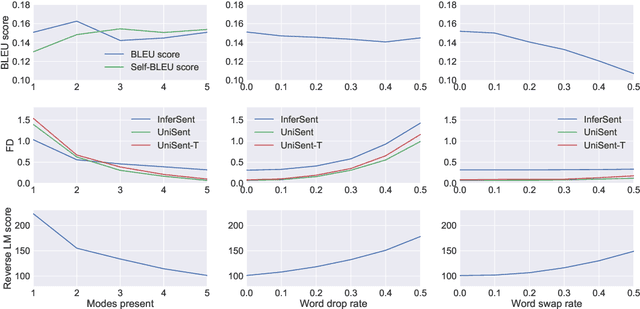
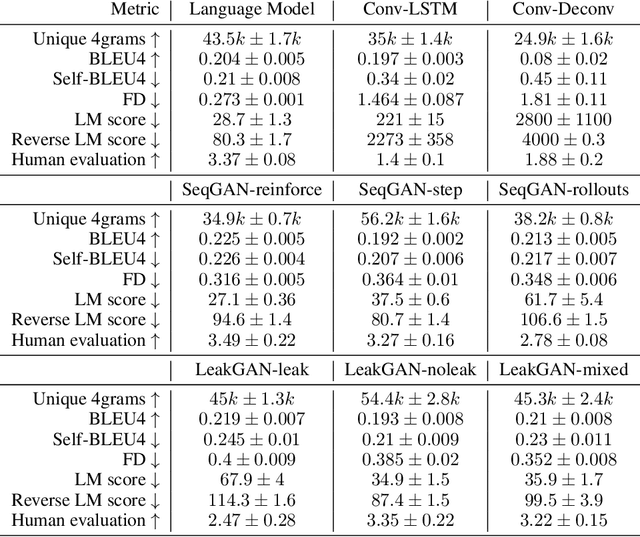
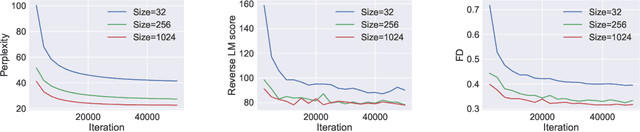
Generative Adversarial Networks (GANs) are a promising approach to language generation. The latest works introducing novel GAN models for language generation use n-gram based metrics for evaluation and only report single scores of the best run. In this paper, we argue that this often misrepresents the true picture and does not tell the full story, as GAN models can be extremely sensitive to the random initialization and small deviations from the best hyperparameter choice. In particular, we demonstrate that the previously used BLEU score is not sensitive to semantic deterioration of generated texts and propose alternative metrics that better capture the quality and diversity of the generated samples. We also conduct a set of experiments comparing a number of GAN models for text with a conventional Language Model (LM) and find that neither of the considered models performs convincingly better than the LM.
MemGEN: Memory is All You Need
Mar 29, 2018

We propose a new learning paradigm called Deep Memory. It has the potential to completely revolutionize the Machine Learning field. Surprisingly, this paradigm has not been reinvented yet, unlike Deep Learning. At the core of this approach is the \textit{Learning By Heart} principle, well studied in primary schools all over the world. Inspired by poem recitation, or by $\pi$ decimal memorization, we propose a concrete algorithm that mimics human behavior. We implement this paradigm on the task of generative modeling, and apply to images, natural language and even the $\pi$ decimals as long as one can print them as text. The proposed algorithm even generated this paper, in a one-shot learning setting. In carefully designed experiments, we show that the generated samples are indistinguishable from the training examples, as measured by any statistical tests or metrics.
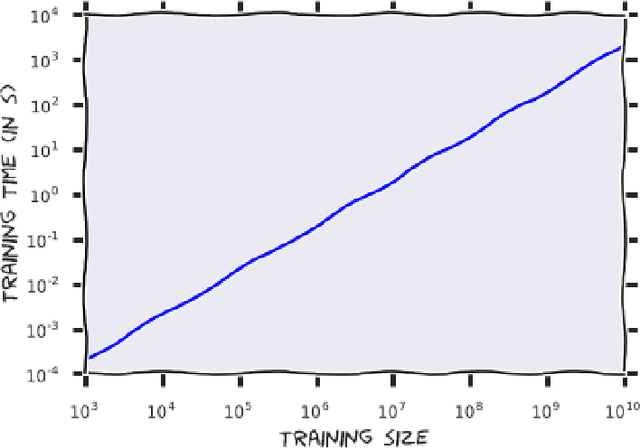
Gradient Descent Quantizes ReLU Network Features
Mar 22, 2018
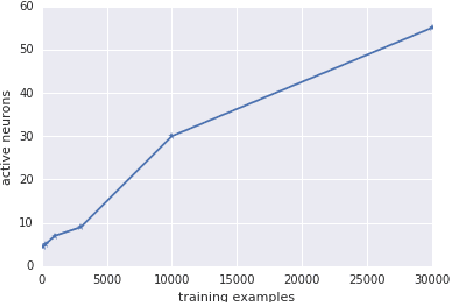
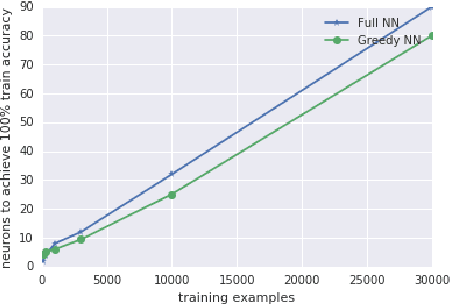
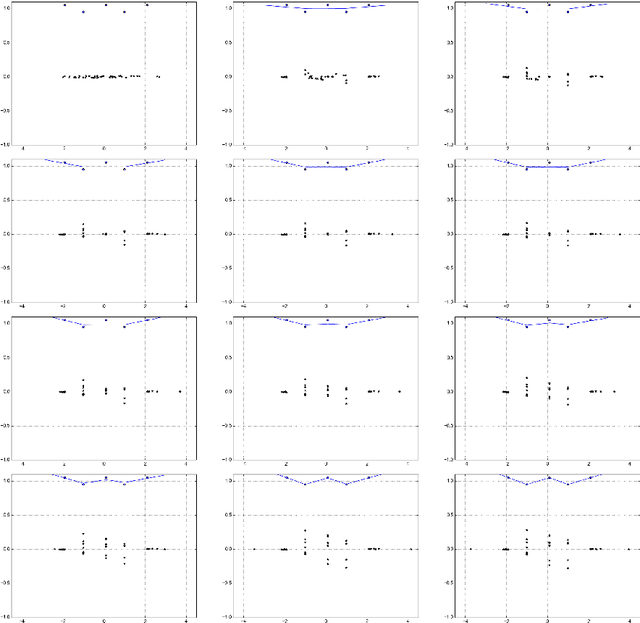
Deep neural networks are often trained in the over-parametrized regime (i.e. with far more parameters than training examples), and understanding why the training converges to solutions that generalize remains an open problem. Several studies have highlighted the fact that the training procedure, i.e. mini-batch Stochastic Gradient Descent (SGD) leads to solutions that have specific properties in the loss landscape. However, even with plain Gradient Descent (GD) the solutions found in the over-parametrized regime are pretty good and this phenomenon is poorly understood. We propose an analysis of this behavior for feedforward networks with a ReLU activation function under the assumption of small initialization and learning rate and uncover a quantization effect: The weight vectors tend to concentrate at a small number of directions determined by the input data. As a consequence, we show that for given input data there are only finitely many, "simple" functions that can be obtained, independent of the network size. This puts these functions in analogy to linear interpolations (for given input data there are finitely many triangulations, which each determine a function by linear interpolation). We ask whether this analogy extends to the generalization properties - while the usual distribution-independent generalization property does not hold, it could be that for e.g. smooth functions with bounded second derivative an approximation property holds which could "explain" generalization of networks (of unbounded size) to unseen inputs.
Wasserstein Auto-Encoders
Mar 12, 2018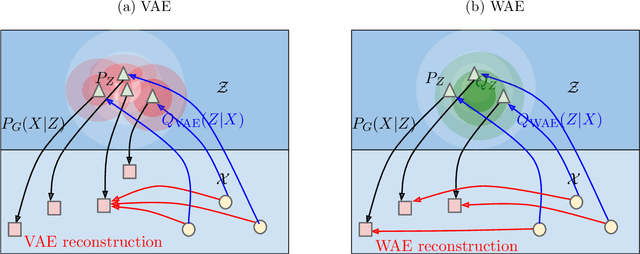
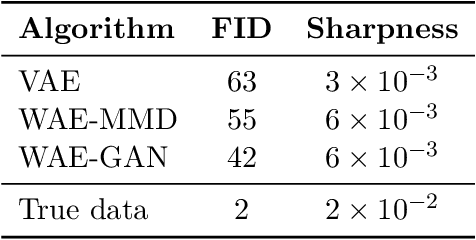


We propose the Wasserstein Auto-Encoder (WAE)---a new algorithm for building a generative model of the data distribution. WAE minimizes a penalized form of the Wasserstein distance between the model distribution and the target distribution, which leads to a different regularizer than the one used by the Variational Auto-Encoder (VAE). This regularizer encourages the encoded training distribution to match the prior. We compare our algorithm with several other techniques and show that it is a generalization of adversarial auto-encoders (AAE). Our experiments show that WAE shares many of the properties of VAEs (stable training, encoder-decoder architecture, nice latent manifold structure) while generating samples of better quality, as measured by the FID score.
Toward Optimal Run Racing: Application to Deep Learning Calibration
Jun 20, 2017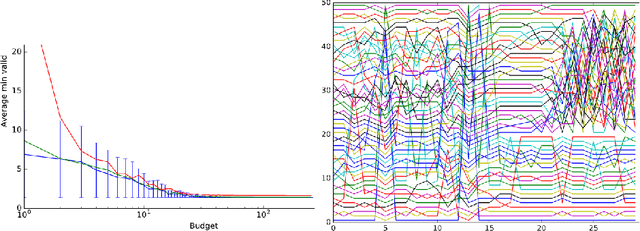
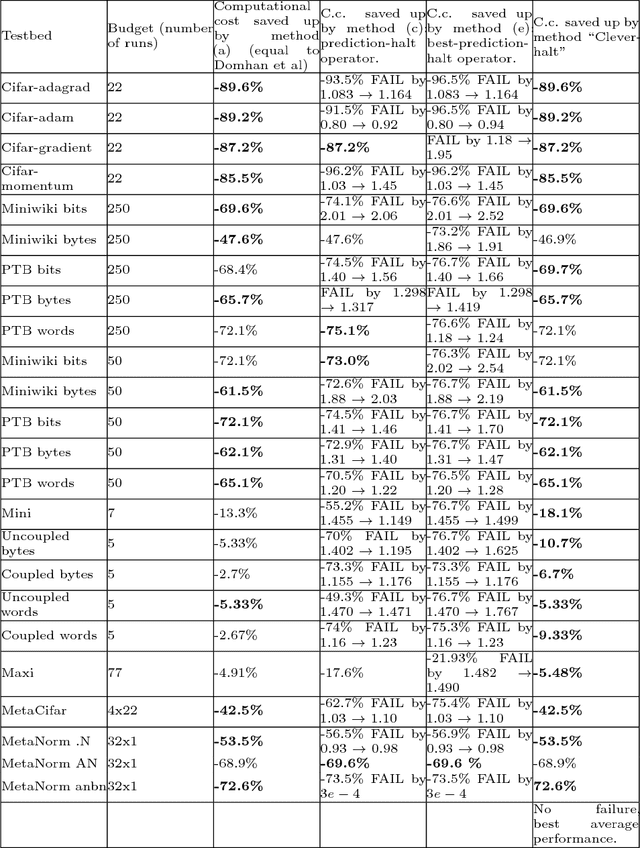
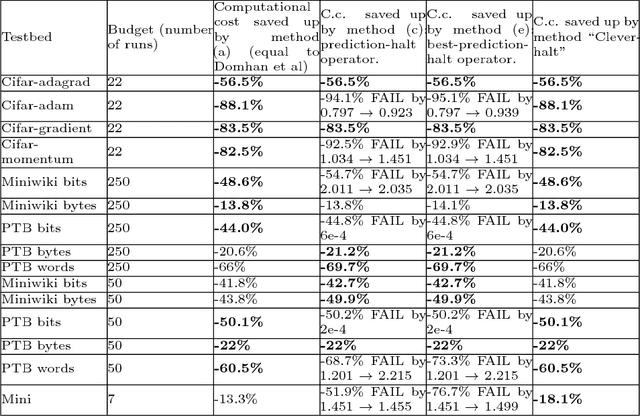
This paper aims at one-shot learning of deep neural nets, where a highly parallel setting is considered to address the algorithm calibration problem - selecting the best neural architecture and learning hyper-parameter values depending on the dataset at hand. The notoriously expensive calibration problem is optimally reduced by detecting and early stopping non-optimal runs. The theoretical contribution regards the optimality guarantees within the multiple hypothesis testing framework. Experimentations on the Cifar10, PTB and Wiki benchmarks demonstrate the relevance of the approach with a principled and consistent improvement on the state of the art with no extra hyper-parameter.
Critical Hyper-Parameters: No Random, No Cry
Jun 10, 2017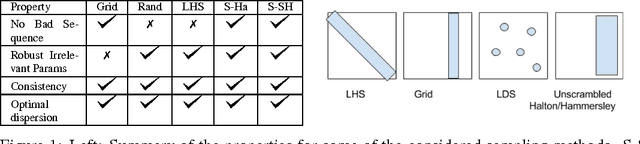
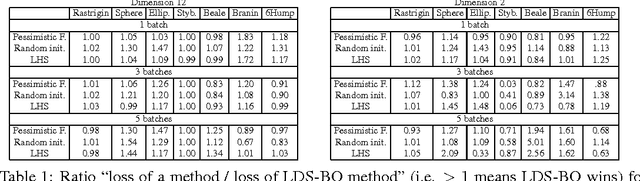

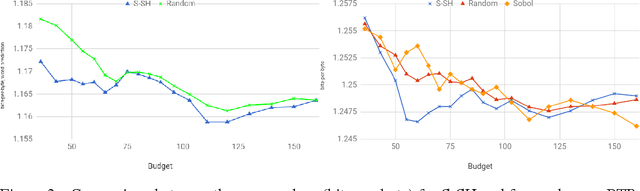
The selection of hyper-parameters is critical in Deep Learning. Because of the long training time of complex models and the availability of compute resources in the cloud, "one-shot" optimization schemes - where the sets of hyper-parameters are selected in advance (e.g. on a grid or in a random manner) and the training is executed in parallel - are commonly used. It is known that grid search is sub-optimal, especially when only a few critical parameters matter, and suggest to use random search instead. Yet, random search can be "unlucky" and produce sets of values that leave some part of the domain unexplored. Quasi-random methods, such as Low Discrepancy Sequences (LDS) avoid these issues. We show that such methods have theoretical properties that make them appealing for performing hyperparameter search, and demonstrate that, when applied to the selection of hyperparameters of complex Deep Learning models (such as state-of-the-art LSTM language models and image classification models), they yield suitable hyperparameters values with much fewer runs than random search. We propose a particularly simple LDS method which can be used as a drop-in replacement for grid or random search in any Deep Learning pipeline, both as a fully one-shot hyperparameter search or as an initializer in iterative batch optimization.
Better Text Understanding Through Image-To-Text Transfer
May 26, 2017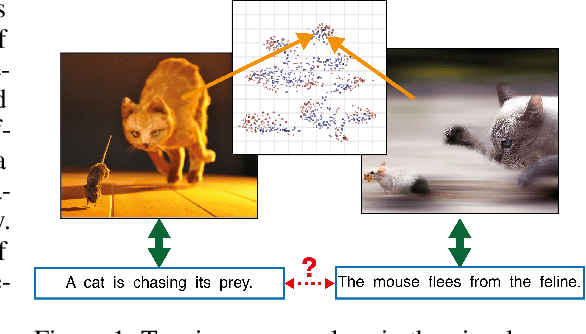
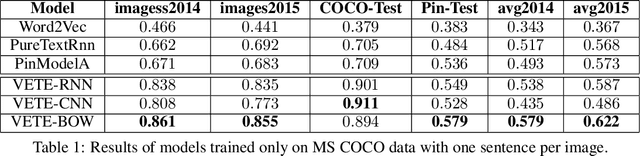
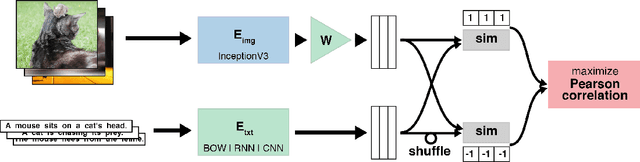
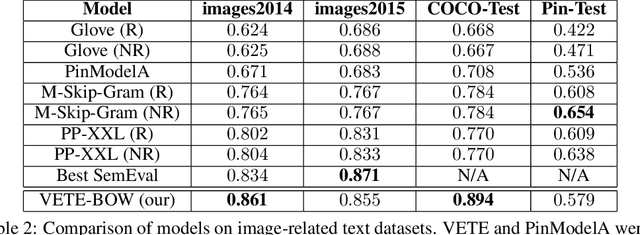
Generic text embeddings are successfully used in a variety of tasks. However, they are often learnt by capturing the co-occurrence structure from pure text corpora, resulting in limitations of their ability to generalize. In this paper, we explore models that incorporate visual information into the text representation. Based on comprehensive ablation studies, we propose a conceptually simple, yet well performing architecture. It outperforms previous multimodal approaches on a set of well established benchmarks. We also improve the state-of-the-art results for image-related text datasets, using orders of magnitude less data.