 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgex-RAGE: eXtended Reality -- Action & Gesture Events Dataset
Oct 25, 2024



With the emergence of the Metaverse and focus on wearable devices in the recent years gesture based human-computer interaction has gained significance. To enable gesture recognition for VR/AR headsets and glasses several datasets focusing on egocentric i.e. first-person view have emerged in recent years. However, standard frame-based vision suffers from limitations in data bandwidth requirements as well as ability to capture fast motions. To overcome these limitation bio-inspired approaches such as event-based cameras present an attractive alternative. In this work, we present the first event-camera based egocentric gesture dataset for enabling neuromorphic, low-power solutions for XR-centric gesture recognition. The dataset has been made available publicly at the following URL: https://gitlab.com/NVM_IITD_Research/xrage.
PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers in a resource-limited Context
Oct 23, 2024Following their success in natural language processing (NLP), there has been a shift towards transformer models in computer vision. While transformers perform well and offer promising multi-tasking performance, due to their high compute requirements, many resource-constrained applications still rely on convolutional or hybrid models that combine the benefits of convolution and attention layers and achieve the best results in the sub 100M parameter range. Simultaneously, task adaptation techniques that allow for the use of one shared transformer backbone for multiple downstream tasks, resulting in great storage savings at negligible cost in performance, have not yet been adopted for hybrid transformers. In this work, we investigate how to achieve the best task-adaptation performance and introduce PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers. We further combine PETAH adaptation with pruning to achieve highly performant and storage friendly models for multi-tasking. In our extensive evaluation on classification and other vision tasks, we demonstrate that our PETAH-adapted hybrid models outperform established task-adaptation techniques for ViTs while requiring fewer parameters and being more efficient on mobile hardware.
Neural Architecture Search of Hybrid Models for NPU-CIM Heterogeneous AR/VR Devices
Oct 10, 2024



Low-Latency and Low-Power Edge AI is essential for Virtual Reality and Augmented Reality applications. Recent advances show that hybrid models, combining convolution layers (CNN) and transformers (ViT), often achieve superior accuracy/performance tradeoff on various computer vision and machine learning (ML) tasks. However, hybrid ML models can pose system challenges for latency and energy-efficiency due to their diverse nature in dataflow and memory access patterns. In this work, we leverage the architecture heterogeneity from Neural Processing Units (NPU) and Compute-In-Memory (CIM) and perform diverse execution schemas to efficiently execute these hybrid models. We also introduce H4H-NAS, a Neural Architecture Search framework to design efficient hybrid CNN/ViT models for heterogeneous edge systems with both NPU and CIM. Our H4H-NAS approach is powered by a performance estimator built with NPU performance results measured on real silicon, and CIM performance based on industry IPs. H4H-NAS searches hybrid CNN/ViT models with fine granularity and achieves significant (up to 1.34%) top-1 accuracy improvement on ImageNet dataset. Moreover, results from our Algo/HW co-design reveal up to 56.08% overall latency and 41.72% energy improvements by introducing such heterogeneous computing over baseline solutions. The framework guides the design of hybrid network architectures and system architectures of NPU+CIM heterogeneous systems.
DRESS: Dynamic REal-time Sparse Subnets
Jul 01, 2022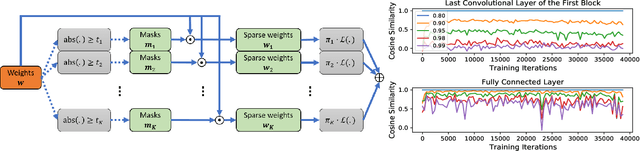
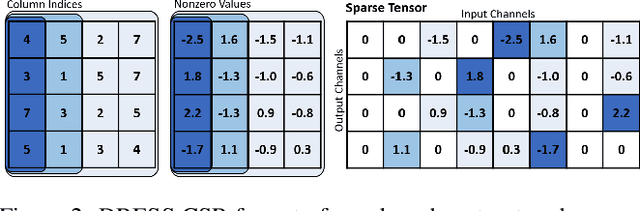
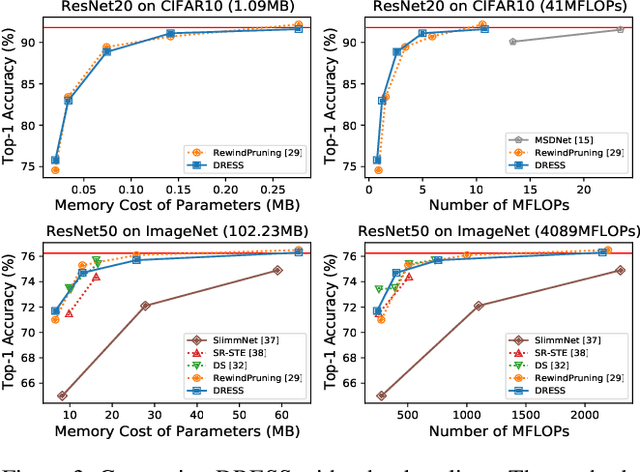
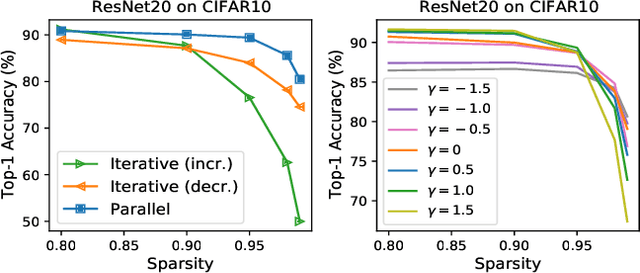
The limited and dynamically varied resources on edge devices motivate us to deploy an optimized deep neural network that can adapt its sub-networks to fit in different resource constraints. However, existing works often build sub-networks through searching different network architectures in a hand-crafted sampling space, which not only can result in a subpar performance but also may cause on-device re-configuration overhead. In this paper, we propose a novel training algorithm, Dynamic REal-time Sparse Subnets (DRESS). DRESS samples multiple sub-networks from the same backbone network through row-based unstructured sparsity, and jointly trains these sub-networks in parallel with weighted loss. DRESS also exploits strategies including parameter reusing and row-based fine-grained sampling for efficient storage consumption and efficient on-device adaptation. Extensive experiments on public vision datasets show that DRESS yields significantly higher accuracy than state-of-the-art sub-networks.
Memory-Oriented Design-Space Exploration of Edge-AI Hardware for XR Applications
Jun 08, 2022
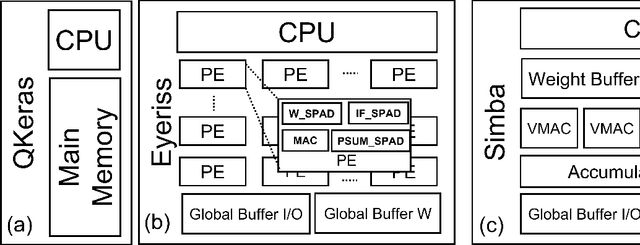
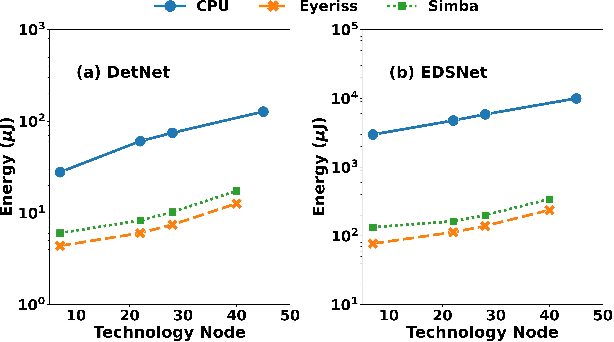
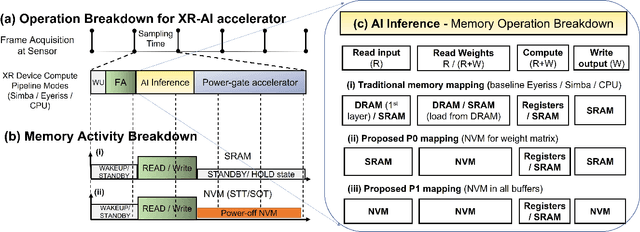
Low-Power Edge-AI capabilities are essential for on-device extended reality (XR) applications to support the vision of Metaverse. In this work, we investigate two representative XR workloads: (i) Hand detection and (ii) Eye segmentation, for hardware design space exploration. For both applications, we train deep neural networks and analyze the impact of quantization and hardware specific bottlenecks. Through simulations, we evaluate a CPU and two systolic inference accelerator implementations. Next, we compare these hardware solutions with advanced technology nodes. The impact of integrating state-of-the-art emerging non-volatile memory technology (STT/SOT/VGSOT MRAM) into the XR-AI inference pipeline is evaluated. We found that significant energy benefits (>=80%) can be achieved for hand detection (IPS=40) and eye segmentation (IPS=6) by introducing non-volatile memory in the memory hierarchy for designs at 7nm node while meeting minimum IPS (inference per second). Moreover, we can realize substantial reduction in area (>=30%) owing to the small form factor of MRAM compared to traditional SRAM.
Distributed On-Sensor Compute System for AR/VR Devices: A Semi-Analytical Simulation Framework for Power Estimation
Mar 14, 2022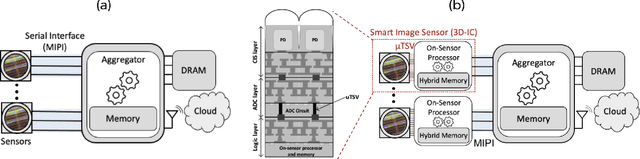
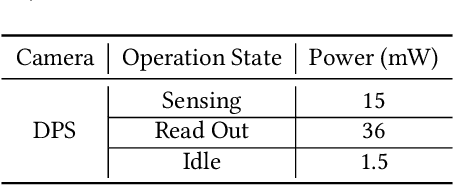


Augmented Reality/Virtual Reality (AR/VR) glasses are widely foreseen as the next generation computing platform. AR/VR glasses are a complex "system of systems" which must satisfy stringent form factor, computing-, power- and thermal- requirements. In this paper, we will show that a novel distributed on-sensor compute architecture, coupled with new semiconductor technologies (such as dense 3D-IC interconnects and Spin-Transfer Torque Magneto Random Access Memory, STT-MRAM) and, most importantly, a full hardware-software co-optimization are the solutions to achieve attractive and socially acceptable AR/VR glasses. To this end, we developed a semi-analytical simulation framework to estimate the power consumption of novel AR/VR distributed on-sensor computing architectures. The model allows the optimization of the main technological features of the system modules, as well as the computer-vision algorithm partition strategy across the distributed compute architecture. We show that, in the case of the compute-intensive machine learning based Hand Tracking algorithm, the distributed on-sensor compute architecture can reduce the system power consumption compared to a centralized system, with the additional benefits in terms of latency and privacy.
Power-of-Two Quantization for Low Bitwidth and Hardware Compliant Neural Networks
Mar 09, 2022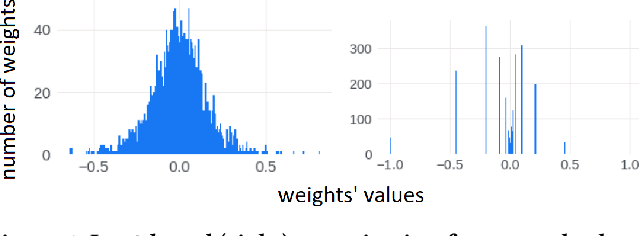
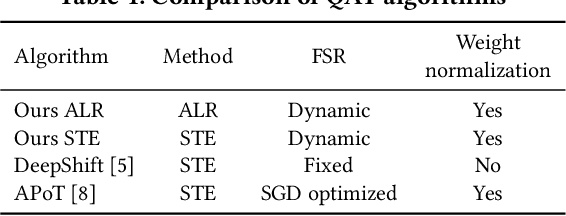
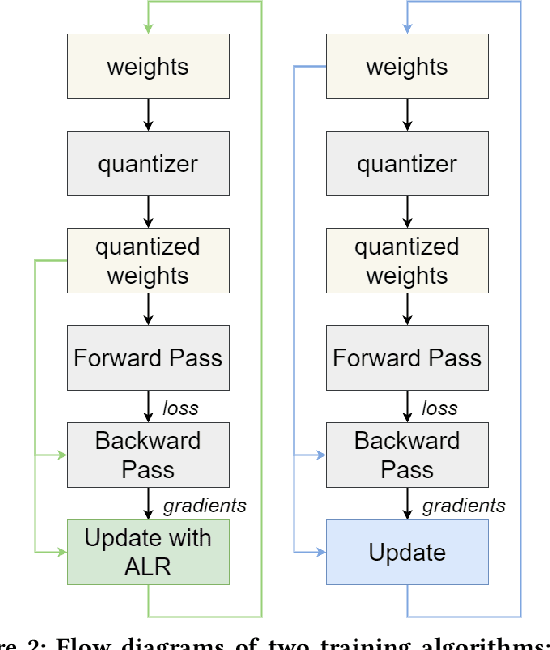
Deploying Deep Neural Networks in low-power embedded devices for real time-constrained applications requires optimization of memory and computational complexity of the networks, usually by quantizing the weights. Most of the existing works employ linear quantization which causes considerable degradation in accuracy for weight bit widths lower than 8. Since the distribution of weights is usually non-uniform (with most weights concentrated around zero), other methods, such as logarithmic quantization, are more suitable as they are able to preserve the shape of the weight distribution more precise. Moreover, using base-2 logarithmic representation allows optimizing the multiplication by replacing it with bit shifting. In this paper, we explore non-linear quantization techniques for exploiting lower bit precision and identify favorable hardware implementation options. We developed the Quantization Aware Training (QAT) algorithm that allowed training of low bit width Power-of-Two (PoT) networks and achieved accuracies on par with state-of-the-art floating point models for different tasks. We explored PoT weight encoding techniques and investigated hardware designs of MAC units for three different quantization schemes - uniform, PoT and Additive-PoT (APoT) - to show the increased efficiency when using the proposed approach. Eventually, the experiments showed that for low bit width precision, non-uniform quantization performs better than uniform, and at the same time, PoT quantization vastly reduces the computational complexity of the neural network.
A Comprehensive Analysis on Adversarial Robustness of Spiking Neural Networks
May 07, 2019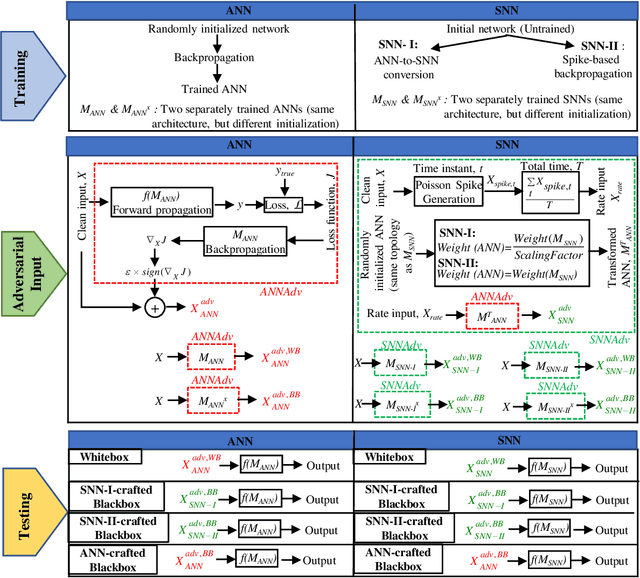
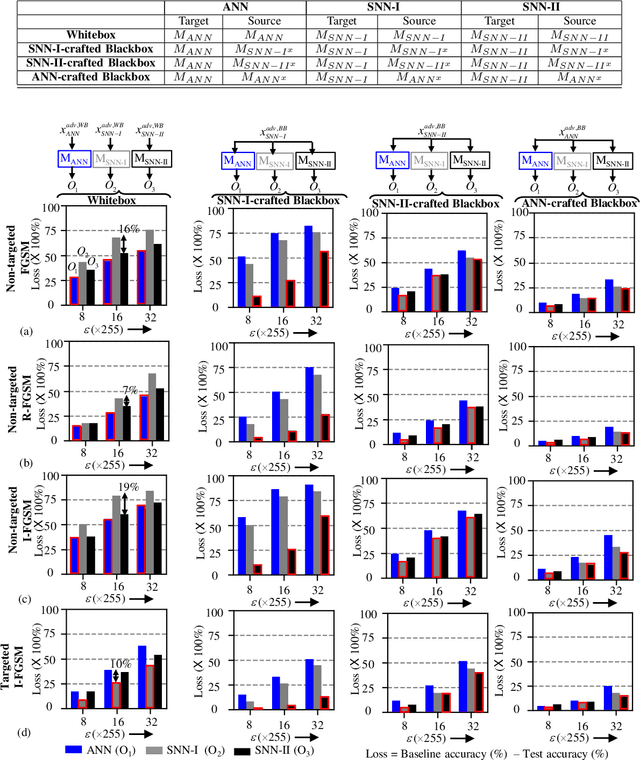
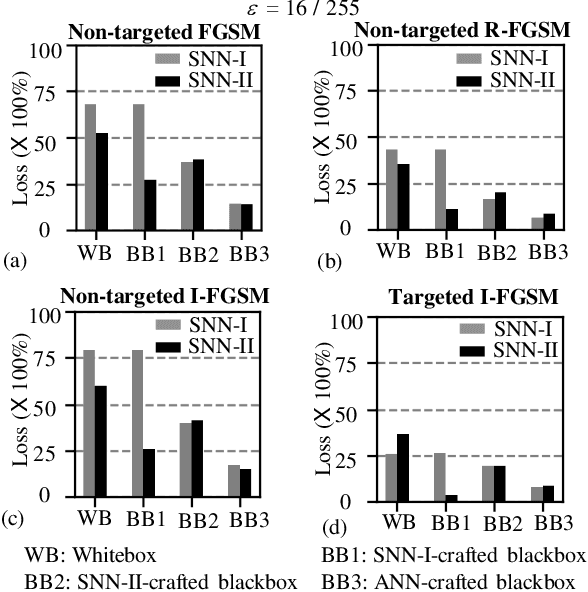
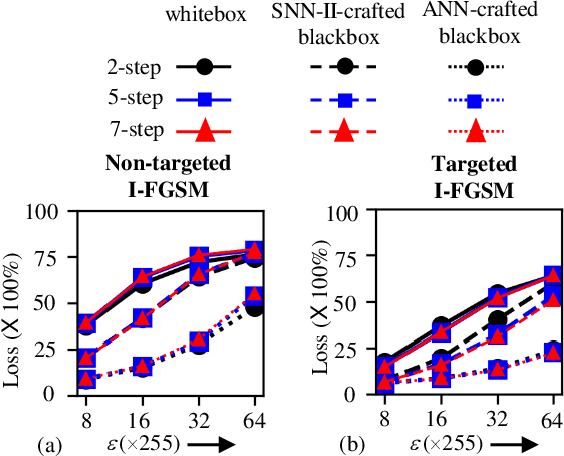
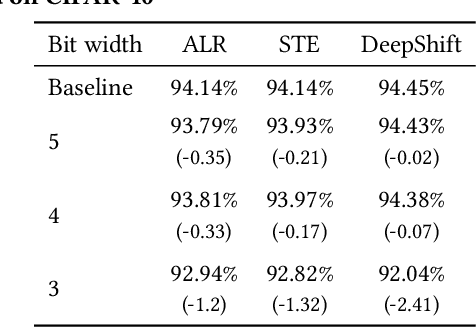
In this era of machine learning models, their functionality is being threatened by adversarial attacks. In the face of this struggle for making artificial neural networks robust, finding a model, resilient to these attacks, is very important. In this work, we present, for the first time, a comprehensive analysis of the behavior of more bio-plausible networks, namely Spiking Neural Network (SNN) under state-of-the-art adversarial tests. We perform a comparative study of the accuracy degradation between conventional VGG-9 Artificial Neural Network (ANN) and equivalent spiking network with CIFAR-10 dataset in both whitebox and blackbox setting for different types of single-step and multi-step FGSM (Fast Gradient Sign Method) attacks. We demonstrate that SNNs tend to show more resiliency compared to ANN under black-box attack scenario. Additionally, we find that SNN robustness is largely dependent on the corresponding training mechanism. We observe that SNNs trained by spike-based backpropagation are more adversarially robust than the ones obtained by ANN-to-SNN conversion rules in several whitebox and blackbox scenarios. Finally, we also propose a simple, yet, effective framework for crafting adversarial attacks from SNNs. Our results suggest that attacks crafted from SNNs following our proposed method are much stronger than those crafted from ANNs.
Enabling Spike-based Backpropagation in State-of-the-art Deep Neural Network Architectures
Mar 25, 2019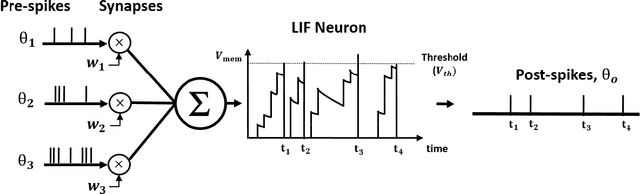
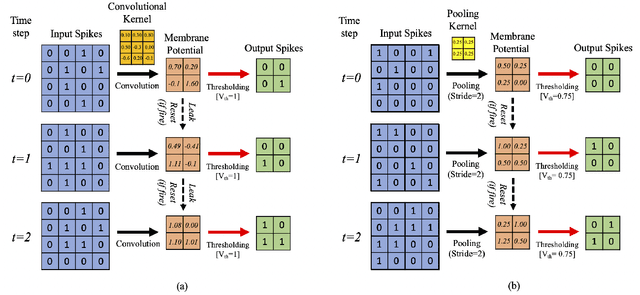
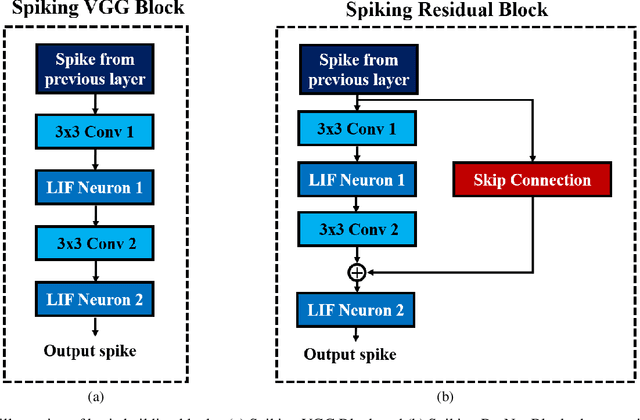
Spiking Neural Networks (SNNs) has recently emerged as a prominent neural computing paradigm. However, the typical shallow spiking network architectures have limited capacity for expressing complex representations, while training a very deep spiking network have not been successful so far. Diverse methods have been proposed to get around this issue such as converting off-line trained deep Artificial Neural Networks (ANNs) to SNNs. However, ANN-to-SNN conversion scheme fails to capture the temporal dynamics of a spiking system. On the other hand, it is still a difficult problem to directly train deep SNNs using input spike events due to the discontinuous and non-differentiable nature of the spike signals. To overcome this problem, we propose using differentiable (but approximate) activation for Leaky Integrate-and-Fire (LIF) spiking neurons to train deep convolutional SNNs with input spike events using spike-based backpropagation algorithm. Our experiments show the effectiveness of the proposed spike-based learning strategy on state-of-the-art deep networks (VGG and Residual architectures) by achieving the best classification accuracies in MNIST, SVHN and CIFAR-10 datasets compared to other SNNs trained with spike-based learning. Moreover, we analyze sparse event-driven computations to demonstrate the efficacy of proposed SNN training method for inference operation in the spiking domain.
Incremental Learning in Deep Convolutional Neural Networks Using Partial Network Sharing
Sep 17, 2018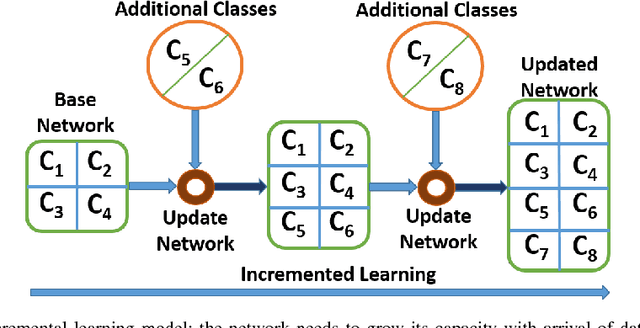
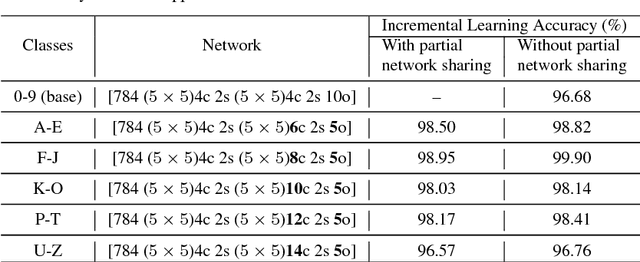
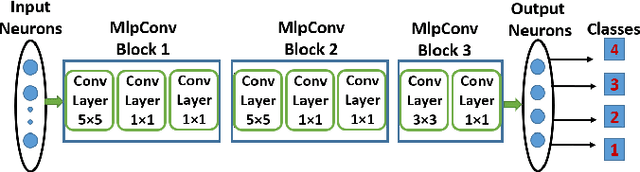

Deep convolutional neural network (DCNN) based supervised learning is a widely practiced approach for large-scale image classification. However, retraining these large networks to accommodate new, previously unseen data demands high computational time and energy requirements. Also, previously seen training samples may not be available at the time of retraining. We propose an efficient training methodology and incrementally growing a DCNN to allow new classes to be learned while sharing part of the base network. Our proposed methodology is inspired by transfer learning techniques, although it does not forget previously learned classes. An updated network for learning new set of classes is formed using previously learned convolutional layers (shared from initial part of base network) with addition of few newly added convolutional kernels included in the later layers of the network. We evaluated the proposed scheme on several recognition applications. The classification accuracy achieved by our approach is comparable to the regular incremental learning approach (where networks are updated with new training samples only, without any network sharing).