 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon Aware Transformers Through Joint Model-Hardware Optimization
May 02, 2025



The rapid growth of machine learning (ML) systems necessitates a more comprehensive evaluation of their environmental impact, particularly their carbon footprint, which comprises operational carbon from training and inference execution and embodied carbon from hardware manufacturing and its entire life-cycle. Despite the increasing importance of embodied emissions, there is a lack of tools and frameworks to holistically quantify and optimize the total carbon footprint of ML systems. To address this, we propose CATransformers, a carbon-aware architecture search framework that enables sustainability-driven co-optimization of ML models and hardware architectures. By incorporating both operational and embodied carbon metrics into early design space exploration of domain-specific hardware accelerators, CATransformers demonstrates that optimizing for carbon yields design choices distinct from those optimized solely for latency or energy efficiency. We apply our framework to multi-modal CLIP-based models, producing CarbonCLIP, a family of CLIP models achieving up to 17% reduction in total carbon emissions while maintaining accuracy and latency compared to state-of-the-art edge small CLIP baselines. This work underscores the need for holistic optimization methods to design high-performance, environmentally sustainable AI systems.
DRESS: Dynamic REal-time Sparse Subnets
Jul 01, 2022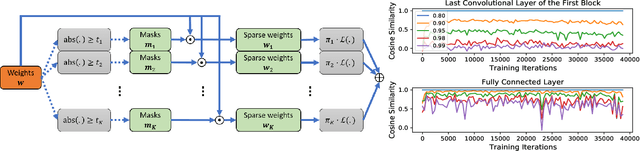
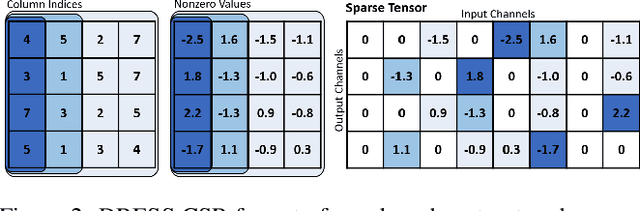
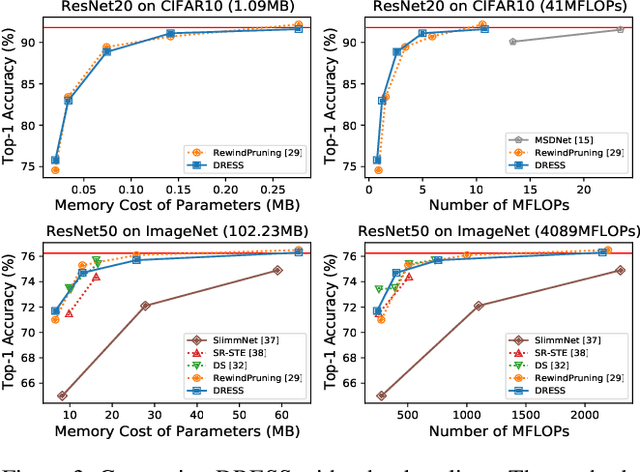
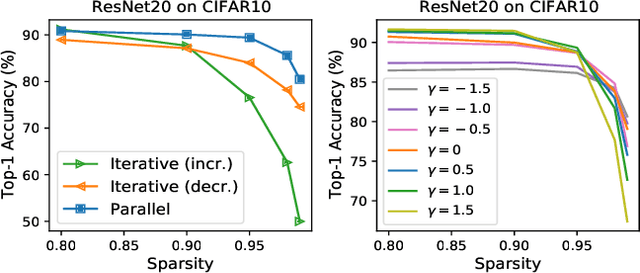
The limited and dynamically varied resources on edge devices motivate us to deploy an optimized deep neural network that can adapt its sub-networks to fit in different resource constraints. However, existing works often build sub-networks through searching different network architectures in a hand-crafted sampling space, which not only can result in a subpar performance but also may cause on-device re-configuration overhead. In this paper, we propose a novel training algorithm, Dynamic REal-time Sparse Subnets (DRESS). DRESS samples multiple sub-networks from the same backbone network through row-based unstructured sparsity, and jointly trains these sub-networks in parallel with weighted loss. DRESS also exploits strategies including parameter reusing and row-based fine-grained sampling for efficient storage consumption and efficient on-device adaptation. Extensive experiments on public vision datasets show that DRESS yields significantly higher accuracy than state-of-the-art sub-networks.