 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Challenges in Applying Explainability Methods to Improve the Fairness of NLP Models
Jun 08, 2022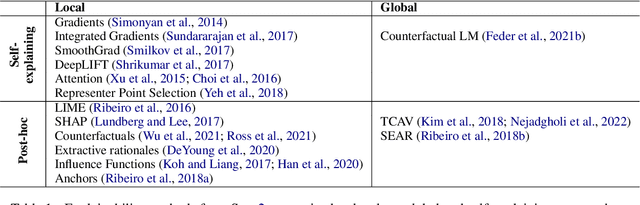
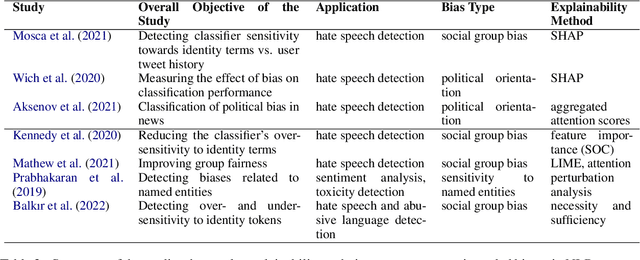
Motivations for methods in explainable artificial intelligence (XAI) often include detecting, quantifying and mitigating bias, and contributing to making machine learning models fairer. However, exactly how an XAI method can help in combating biases is often left unspecified. In this paper, we briefly review trends in explainability and fairness in NLP research, identify the current practices in which explainability methods are applied to detect and mitigate bias, and investigate the barriers preventing XAI methods from being used more widely in tackling fairness issues.
Does Moral Code Have a Moral Code? Probing Delphi's Moral Philosophy
May 25, 2022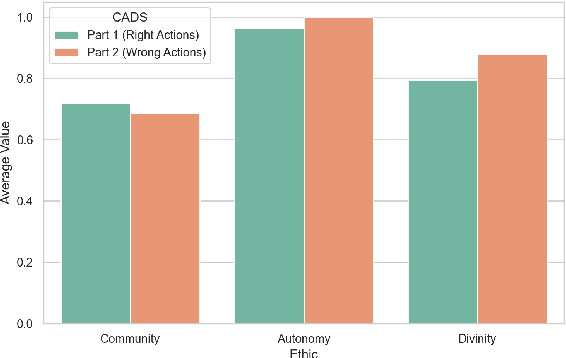
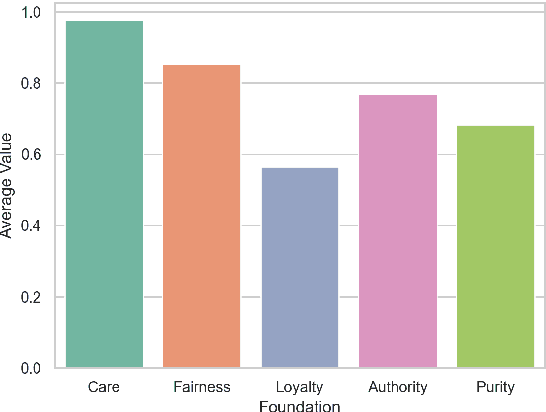
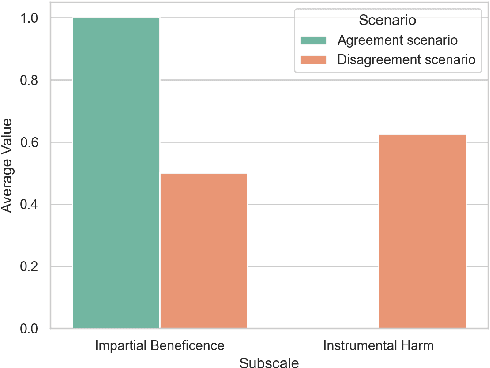

In an effort to guarantee that machine learning model outputs conform with human moral values, recent work has begun exploring the possibility of explicitly training models to learn the difference between right and wrong. This is typically done in a bottom-up fashion, by exposing the model to different scenarios, annotated with human moral judgements. One question, however, is whether the trained models actually learn any consistent, higher-level ethical principles from these datasets -- and if so, what? Here, we probe the Allen AI Delphi model with a set of standardized morality questionnaires, and find that, despite some inconsistencies, Delphi tends to mirror the moral principles associated with the demographic groups involved in the annotation process. We question whether this is desirable and discuss how we might move forward with this knowledge.
Necessity and Sufficiency for Explaining Text Classifiers: A Case Study in Hate Speech Detection
May 06, 2022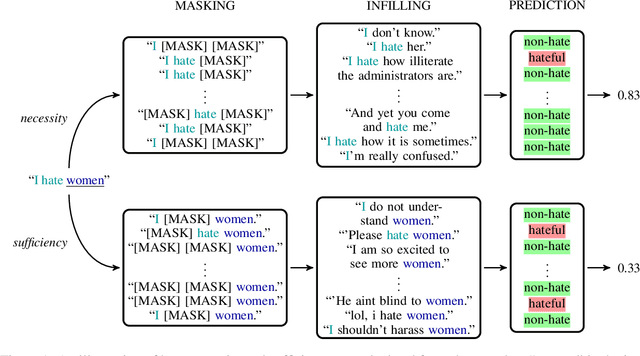

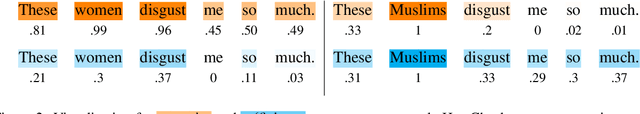
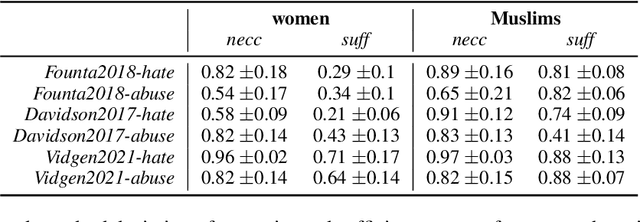
We present a novel feature attribution method for explaining text classifiers, and analyze it in the context of hate speech detection. Although feature attribution models usually provide a single importance score for each token, we instead provide two complementary and theoretically-grounded scores -- necessity and sufficiency -- resulting in more informative explanations. We propose a transparent method that calculates these values by generating explicit perturbations of the input text, allowing the importance scores themselves to be explainable. We employ our method to explain the predictions of different hate speech detection models on the same set of curated examples from a test suite, and show that different values of necessity and sufficiency for identity terms correspond to different kinds of false positive errors, exposing sources of classifier bias against marginalized groups.
Improving Generalizability in Implicitly Abusive Language Detection with Concept Activation Vectors
Apr 05, 2022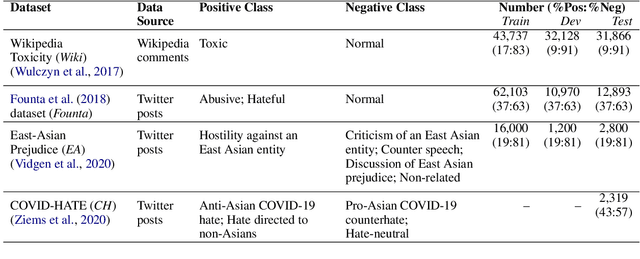
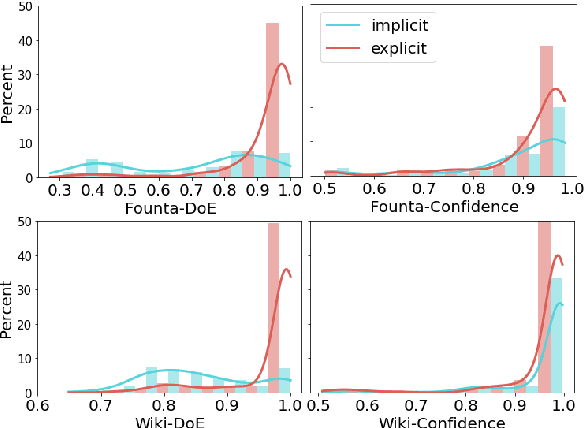
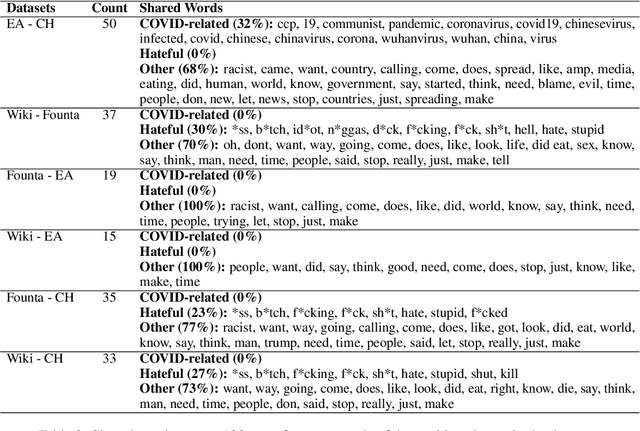
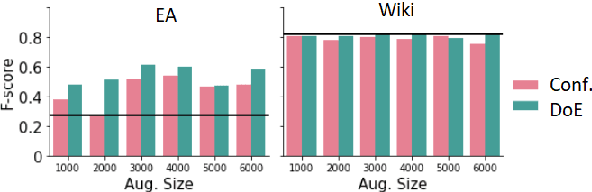
Robustness of machine learning models on ever-changing real-world data is critical, especially for applications affecting human well-being such as content moderation. New kinds of abusive language continually emerge in online discussions in response to current events (e.g., COVID-19), and the deployed abuse detection systems should be updated regularly to remain accurate. In this paper, we show that general abusive language classifiers tend to be fairly reliable in detecting out-of-domain explicitly abusive utterances but fail to detect new types of more subtle, implicit abuse. Next, we propose an interpretability technique, based on the Testing Concept Activation Vector (TCAV) method from computer vision, to quantify the sensitivity of a trained model to the human-defined concepts of explicit and implicit abusive language, and use that to explain the generalizability of the model on new data, in this case, COVID-related anti-Asian hate speech. Extending this technique, we introduce a novel metric, Degree of Explicitness, for a single instance and show that the new metric is beneficial in suggesting out-of-domain unlabeled examples to effectively enrich the training data with informative, implicitly abusive texts.
Understanding and Countering Stereotypes: A Computational Approach to the Stereotype Content Model
Jun 04, 2021
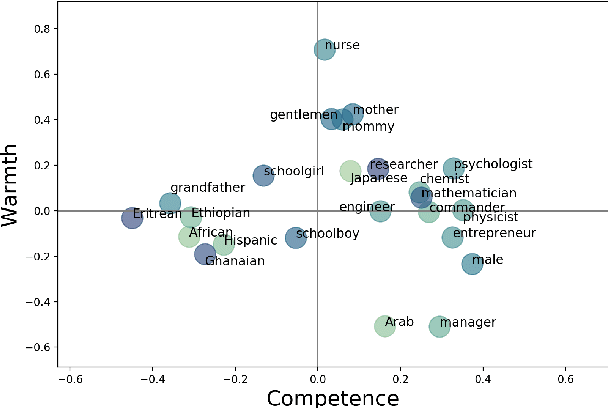

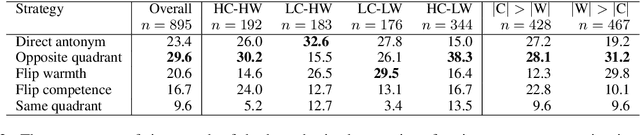
Stereotypical language expresses widely-held beliefs about different social categories. Many stereotypes are overtly negative, while others may appear positive on the surface, but still lead to negative consequences. In this work, we present a computational approach to interpreting stereotypes in text through the Stereotype Content Model (SCM), a comprehensive causal theory from social psychology. The SCM proposes that stereotypes can be understood along two primary dimensions: warmth and competence. We present a method for defining warmth and competence axes in semantic embedding space, and show that the four quadrants defined by this subspace accurately represent the warmth and competence concepts, according to annotated lexicons. We then apply our computational SCM model to textual stereotype data and show that it compares favourably with survey-based studies in the psychological literature. Furthermore, we explore various strategies to counter stereotypical beliefs with anti-stereotypes. It is known that countering stereotypes with anti-stereotypical examples is one of the most effective ways to reduce biased thinking, yet the problem of generating anti-stereotypes has not been previously studied. Thus, a better understanding of how to generate realistic and effective anti-stereotypes can contribute to addressing pressing societal concerns of stereotyping, prejudice, and discrimination.
Confronting Abusive Language Online: A Survey from the Ethical and Human Rights Perspective
Dec 22, 2020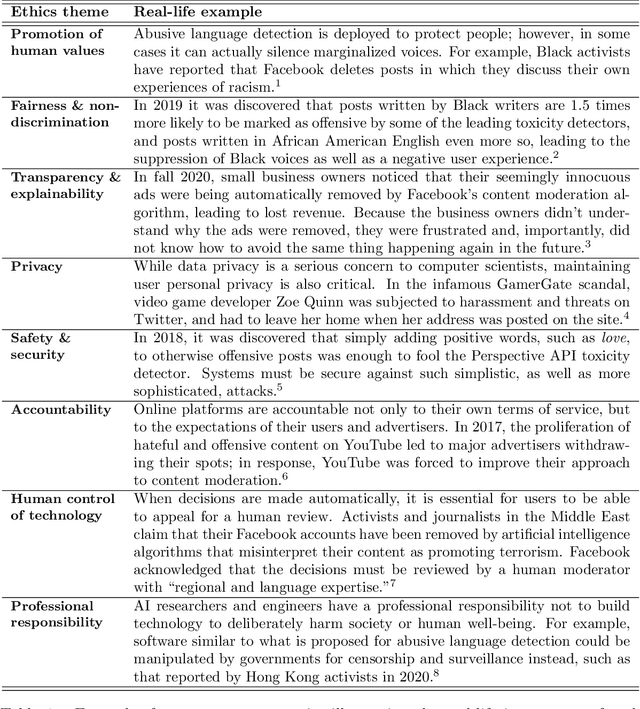
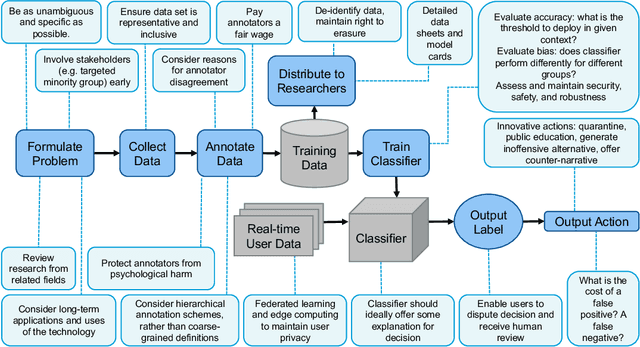
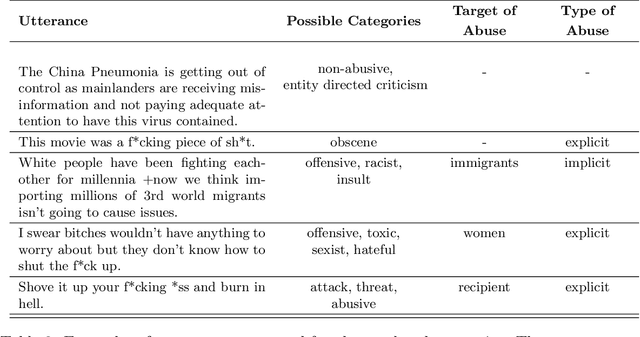
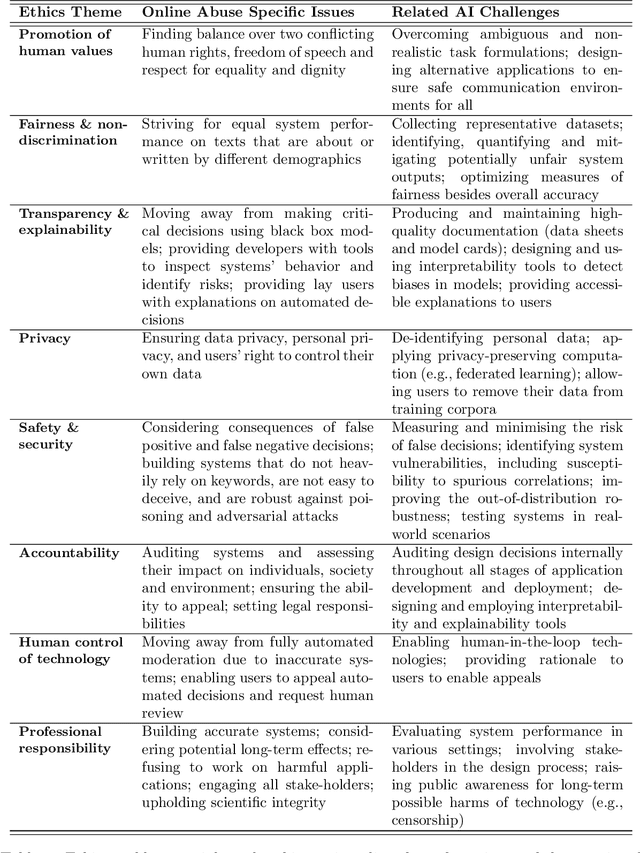
The pervasiveness of abusive content on the internet can lead to severe psychological and physical harm. Significant effort in Natural Language Processing (NLP) research has been devoted to addressing this problem through abusive content detection and related sub-areas, such as the detection of hate speech, toxicity, cyberbullying, etc. Although current technologies achieve high classification performance in research studies, it has been observed that the real-life application of this technology can cause unintended harms, such as the silencing of under-represented groups. We review a large body of NLP research on automatic abuse detection with a new focus on ethical challenges, organized around eight established ethical principles: privacy, accountability, safety and security, transparency and explainability, fairness and non-discrimination, human control of technology, professional responsibility, and promotion of human values. In many cases, these principles relate not only to situational ethical codes, which may be context-dependent, but are in fact connected to universal human rights, such as the right to privacy, freedom from discrimination, and freedom of expression. We highlight the need to examine the broad social impacts of this technology, and to bring ethical and human rights considerations to every stage of the application life-cycle, from task formulation and dataset design, to model training and evaluation, to application deployment. Guided by these principles, we identify several opportunities for rights-respecting, socio-technical solutions to detect and confront online abuse, including 'nudging', 'quarantining', value sensitive design, counter-narratives, style transfer, and AI-driven public education applications.
On Cross-Dataset Generalization in Automatic Detection of Online Abuse
Nov 03, 2020
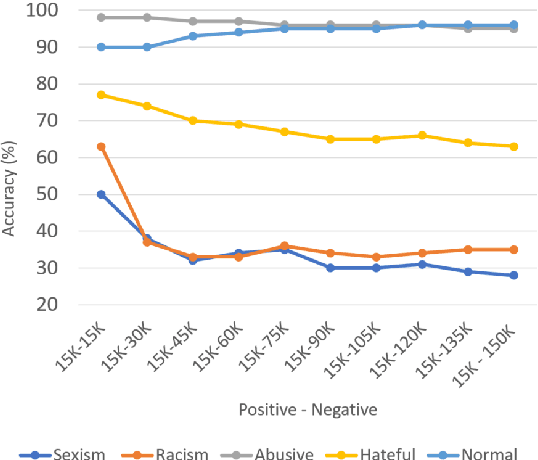
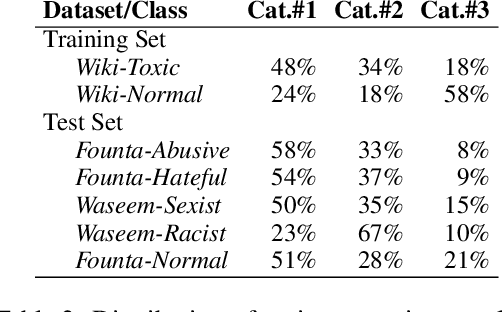
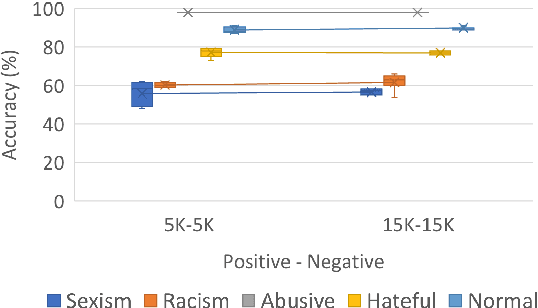
NLP research has attained high performances in abusive language detection as a supervised classification task. While in research settings, training and test datasets are usually obtained from similar data samples, in practice systems are often applied on data that are different from the training set in topic and class distributions. Also, the ambiguity in class definitions inherited in this task aggravates the discrepancies between source and target datasets. We explore the topic bias and the task formulation bias in cross-dataset generalization. We show that the benign examples in the Wikipedia Detox dataset are biased towards platform-specific topics. We identify these examples using unsupervised topic modeling and manual inspection of topics' keywords. Removing these topics increases cross-dataset generalization, without reducing in-domain classification performance. For a robust dataset design, we suggest applying inexpensive unsupervised methods to inspect the collected data and downsize the non-generalizable content before manually annotating for class labels.
Towards Ethics by Design in Online Abusive Content Detection
Oct 28, 2020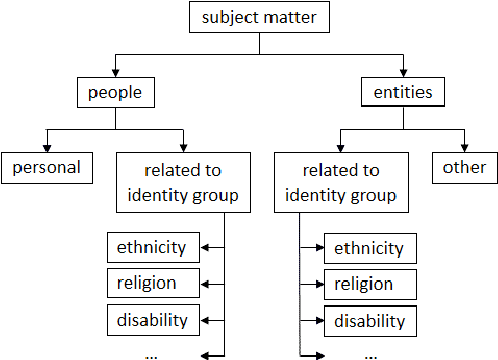


To support safety and inclusion in online communications, significant efforts in NLP research have been put towards addressing the problem of abusive content detection, commonly defined as a supervised classification task. The research effort has spread out across several closely related sub-areas, such as detection of hate speech, toxicity, cyberbullying, etc. There is a pressing need to consolidate the field under a common framework for task formulation, dataset design and performance evaluation. Further, despite current technologies achieving high classification accuracies, several ethical issues have been revealed. We bring ethical issues to forefront and propose a unified framework as a two-step process. First, online content is categorized around personal and identity-related subject matters. Second, severity of abuse is identified through comparative annotation within each category. The novel framework is guided by the Ethics by Design principle and is a step towards building more accurate and trusted models.
SOLO: A Corpus of Tweets for Examining the State of Being Alone
Jun 04, 2020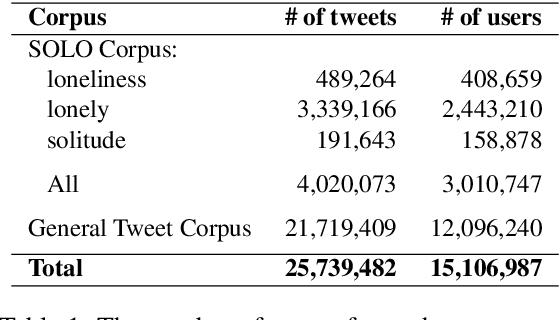
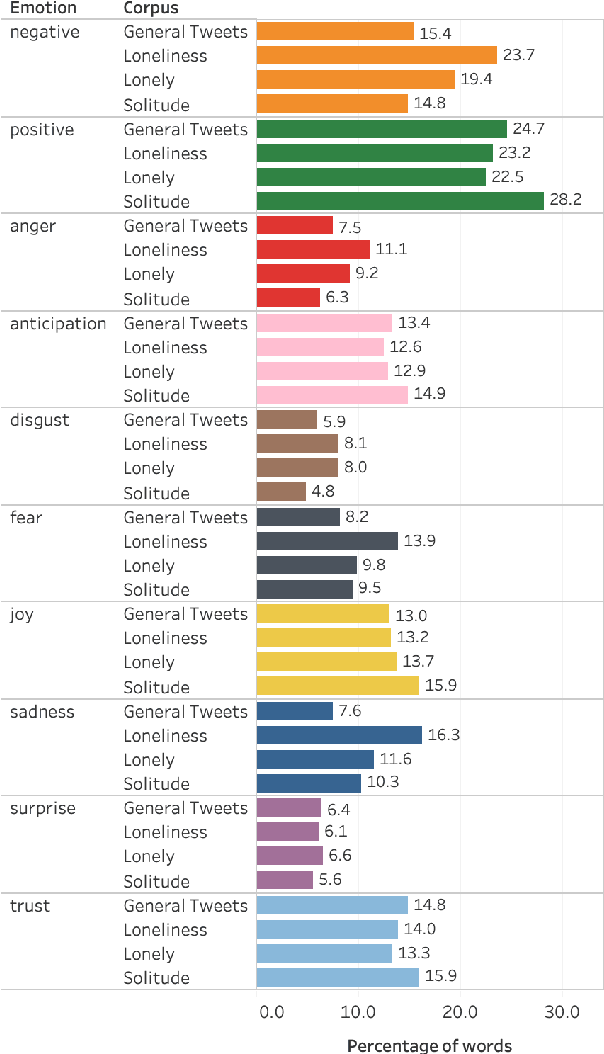

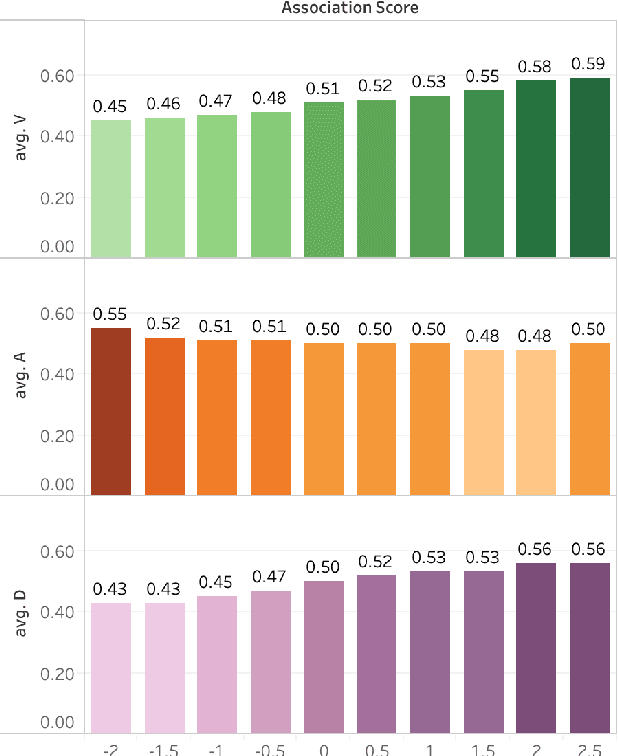
The state of being alone can have a substantial impact on our lives, though experiences with time alone diverge significantly among individuals. Psychologists distinguish between the concept of solitude, a positive state of voluntary aloneness, and the concept of loneliness, a negative state of dissatisfaction with the quality of one's social interactions. Here, for the first time, we conduct a large-scale computational analysis to explore how the terms associated with the state of being alone are used in online language. We present SOLO (State of Being Alone), a corpus of over 4 million tweets collected with query terms 'solitude', 'lonely', and 'loneliness'. We use SOLO to analyze the language and emotions associated with the state of being alone. We show that the term 'solitude' tends to co-occur with more positive, high-dominance words (e.g., enjoy, bliss) while the terms 'lonely' and 'loneliness' frequently co-occur with negative, low-dominance words (e.g., scared, depressed), which confirms the conceptual distinctions made in psychology. We also show that women are more likely to report on negative feelings of being lonely as compared to men, and there are more teenagers among the tweeters that use the word 'lonely' than among the tweeters that use the word 'solitude'.