 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Defensive Distillation For Defending Text Processing Neural Networks Against Adversarial Examples
Aug 21, 2019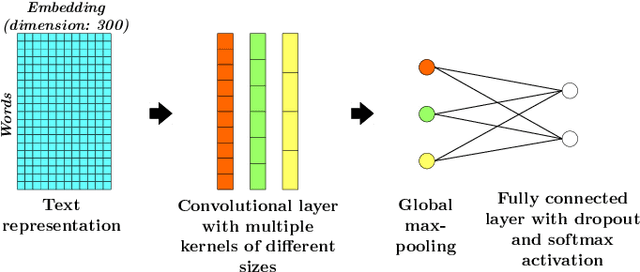


Adversarial examples are artificially modified input samples which lead to misclassifications, while not being detectable by humans. These adversarial examples are a challenge for many tasks such as image and text classification, especially as research shows that many adversarial examples are transferable between different classifiers. In this work, we evaluate the performance of a popular defensive strategy for adversarial examples called defensive distillation, which can be successful in hardening neural networks against adversarial examples in the image domain. However, instead of applying defensive distillation to networks for image classification, we examine, for the first time, its performance on text classification tasks and also evaluate its effect on the transferability of adversarial text examples. Our results indicate that defensive distillation only has a minimal impact on text classifying neural networks and does neither help with increasing their robustness against adversarial examples nor prevent the transferability of adversarial examples between neural networks.
Improving interactive reinforcement learning: What makes a good teacher?
Apr 15, 2019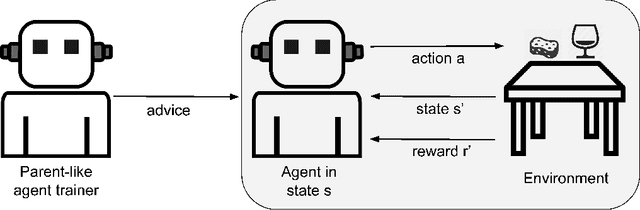
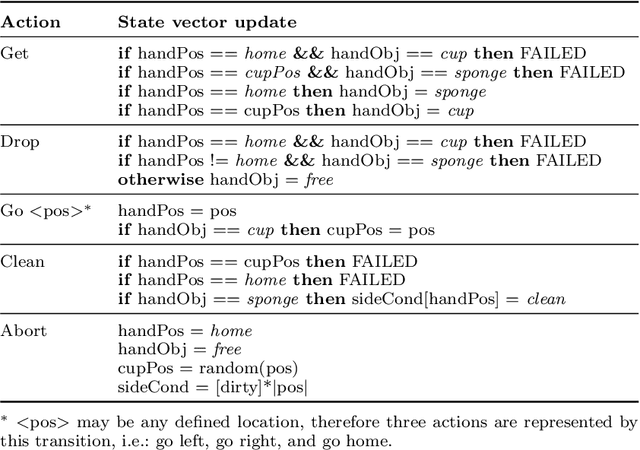

Interactive reinforcement learning has become an important apprenticeship approach to speed up convergence in classic reinforcement learning problems. In this regard, a variant of interactive reinforcement learning is policy shaping which uses a parent-like trainer to propose the next action to be performed and by doing so reduces the search space by advice. On some occasions, the trainer may be another artificial agent which in turn was trained using reinforcement learning methods to afterward becoming an advisor for other learner-agents. In this work, we analyze internal representations and characteristics of artificial agents to determine which agent may outperform others to become a better trainer-agent. Using a polymath agent, as compared to a specialist agent, an advisor leads to a larger reward and faster convergence of the reward signal and also to a more stable behavior in terms of the state visit frequency of the learner-agents. Moreover, we analyze system interaction parameters in order to determine how influential they are in the apprenticeship process, where the consistency of feedback is much more relevant when dealing with different learner obedience parameters.
* 21 pages, 12 figures
KT-Speech-Crawler: Automatic Dataset Construction for Speech Recognition from YouTube Videos
Mar 01, 2019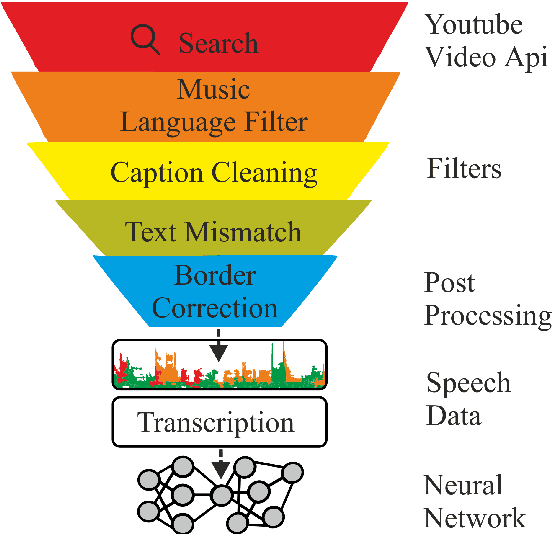
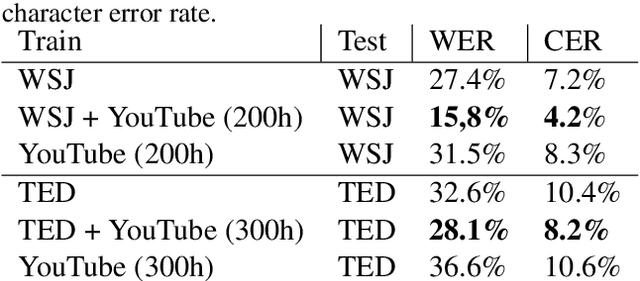
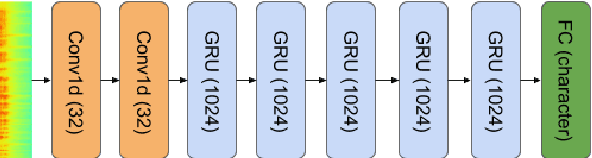
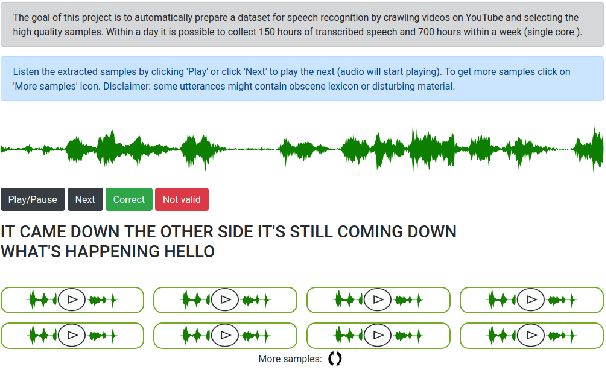
In this paper, we describe KT-Speech-Crawler: an approach for automatic dataset construction for speech recognition by crawling YouTube videos. We outline several filtering and post-processing steps, which extract samples that can be used for training end-to-end neural speech recognition systems. In our experiments, we demonstrate that a single-core version of the crawler can obtain around 150 hours of transcribed speech within a day, containing an estimated 3.5% word error rate in the transcriptions. Automatically collected samples contain reading and spontaneous speech recorded in various conditions including background noise and music, distant microphone recordings, and a variety of accents and reverberation. When training a deep neural network on speech recognition, we observed around 40\% word error rate reduction on the Wall Street Journal dataset by integrating 200 hours of the collected samples into the training set. The demo (http://emnlp-demo.lakomkin.me/) and the crawler code (https://github.com/EgorLakomkin/KTSpeechCrawler) are publicly available.
Incorporating End-to-End Speech Recognition Models for Sentiment Analysis
Feb 28, 2019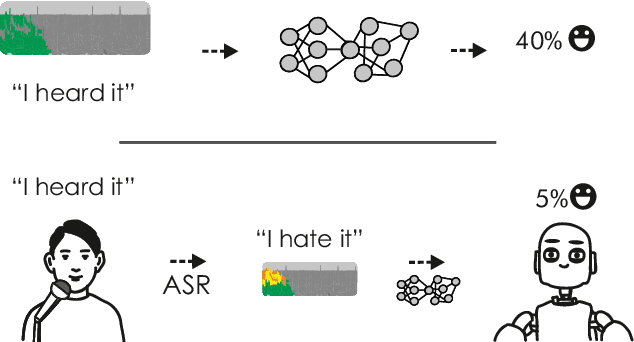
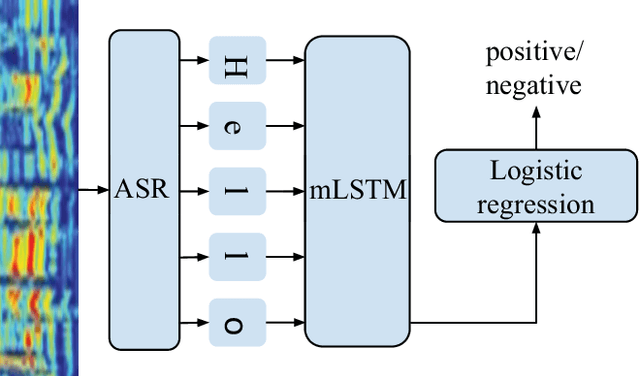
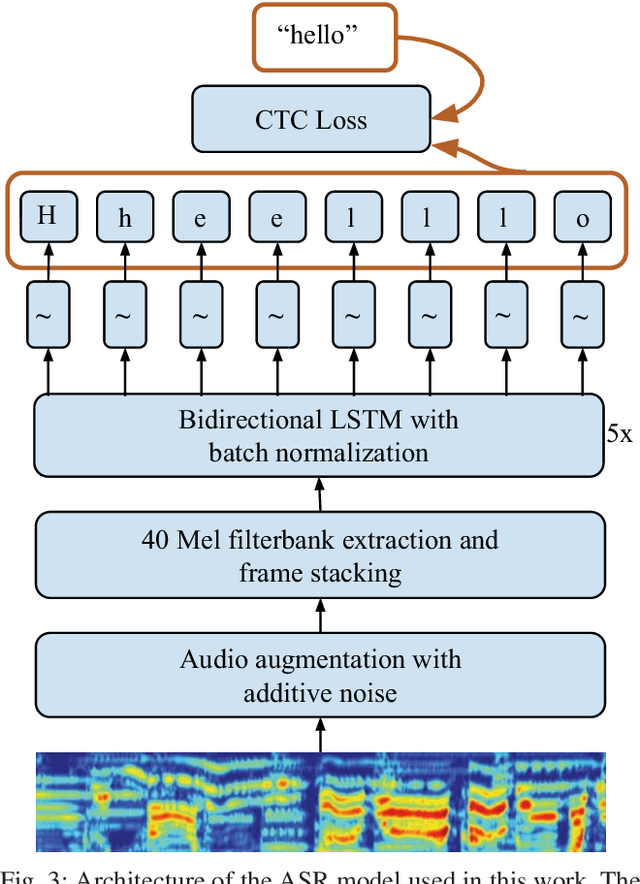
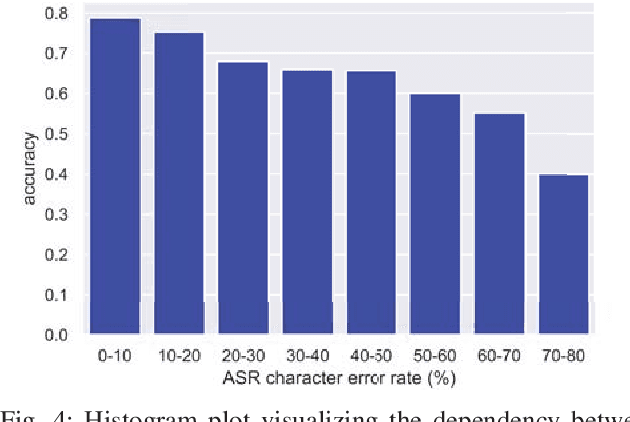
Previous work on emotion recognition demonstrated a synergistic effect of combining several modalities such as auditory, visual, and transcribed text to estimate the affective state of a speaker. Among these, the linguistic modality is crucial for the evaluation of an expressed emotion. However, manually transcribed spoken text cannot be given as input to a system practically. We argue that using ground-truth transcriptions during training and evaluation phases leads to a significant discrepancy in performance compared to real-world conditions, as the spoken text has to be recognized on the fly and can contain speech recognition mistakes. In this paper, we propose a method of integrating an automatic speech recognition (ASR) output with a character-level recurrent neural network for sentiment recognition. In addition, we conduct several experiments investigating sentiment recognition for human-robot interaction in a noise-realistic scenario which is challenging for the ASR systems. We quantify the improvement compared to using only the acoustic modality in sentiment recognition. We demonstrate the effectiveness of this approach on the Multimodal Corpus of Sentiment Intensity (MOSI) by achieving 73,6% accuracy in a binary sentiment classification task, exceeding previously reported results that use only acoustic input. In addition, we set a new state-of-the-art performance on the MOSI dataset (80.4% accuracy, 2% absolute improvement).
Assessing the Contribution of Semantic Congruency to Multisensory Integration and Conflict Resolution
Oct 15, 2018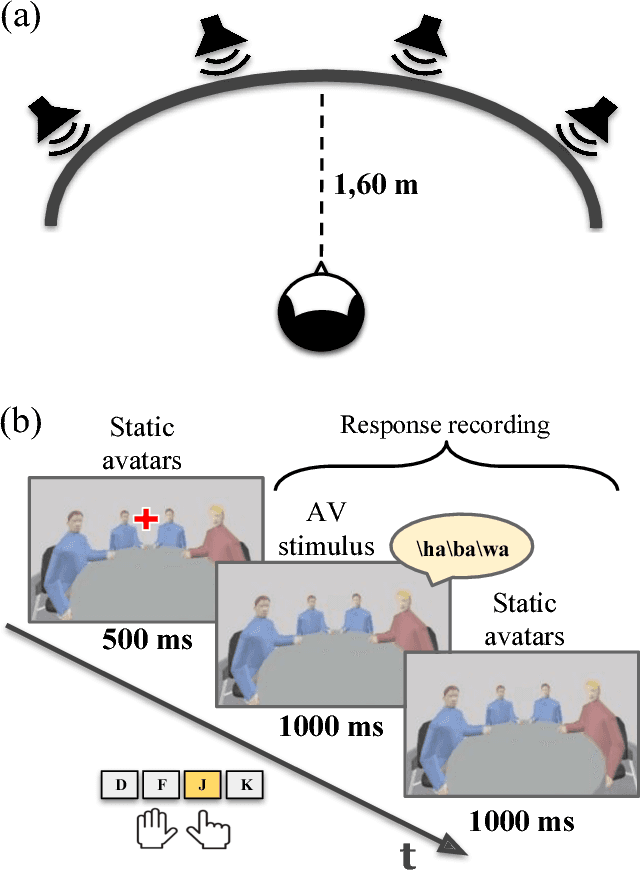
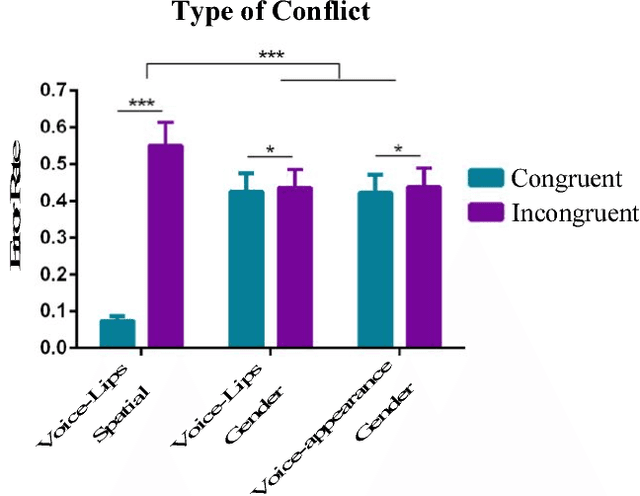
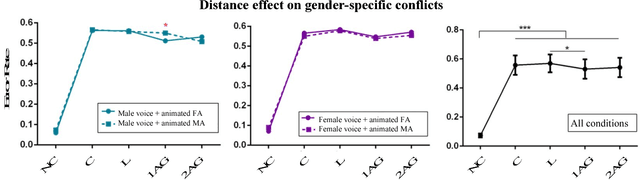
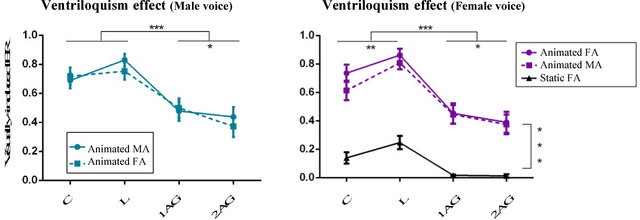
The efficient integration of multisensory observations is a key property of the brain that yields the robust interaction with the environment. However, artificial multisensory perception remains an open issue especially in situations of sensory uncertainty and conflicts. In this work, we extend previous studies on audio-visual (AV) conflict resolution in complex environments. In particular, we focus on quantitatively assessing the contribution of semantic congruency during an AV spatial localization task. In addition to conflicts in the spatial domain (i.e. spatially misaligned stimuli), we consider gender-specific conflicts with male and female avatars. Our results suggest that while semantically related stimuli affect the magnitude of the visual bias (perceptually shifting the location of the sound towards a semantically congruent visual cue), humans still strongly rely on environmental statistics to solve AV conflicts. Together with previously reported results, this work contributes to a better understanding of how multisensory integration and conflict resolution can be modelled in artificial agents and robots operating in real-world environments.
A Neurorobotic Experiment for Crossmodal Conflict Resolution in Complex Environments
Sep 24, 2018
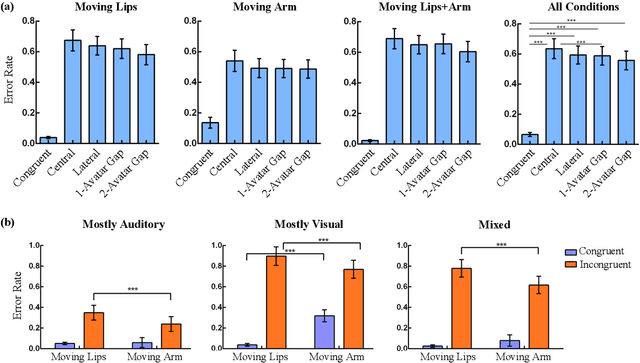
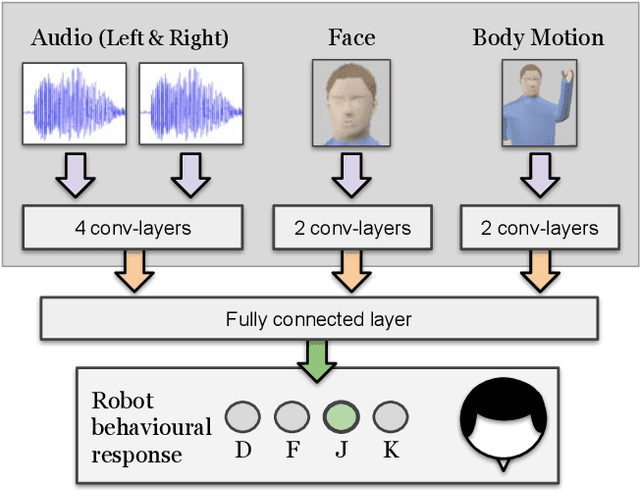
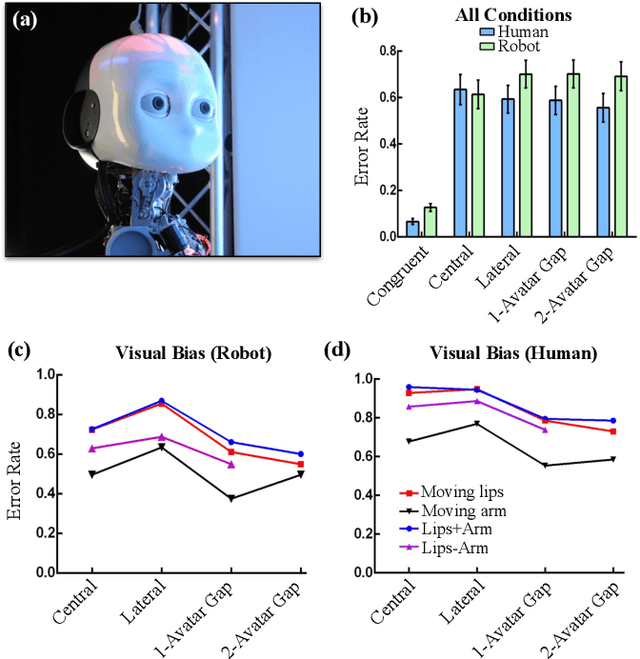
Crossmodal conflict resolution is crucial for robot sensorimotor coupling through the interaction with the environment, yielding swift and robust behaviour also in noisy conditions. In this paper, we propose a neurorobotic experiment in which an iCub robot exhibits human-like responses in a complex crossmodal environment. To better understand how humans deal with multisensory conflicts, we conducted a behavioural study exposing 33 subjects to congruent and incongruent dynamic audio-visual cues. In contrast to previous studies using simplified stimuli, we designed a scenario with four animated avatars and observed that the magnitude and extension of the visual bias are related to the semantics embedded in the scene, i.e., visual cues that are congruent with environmental statistics (moving lips and vocalization) induce the strongest bias. We implement a deep learning model that processes stereophonic sound, facial features, and body motion to trigger a discrete behavioural response. After training the model, we exposed the iCub to the same experimental conditions as the human subjects, showing that the robot can replicate similar responses in real time. Our interdisciplinary work provides important insights into how crossmodal conflict resolution can be modelled in robots and introduces future research directions for the efficient combination of sensory observations with internally generated knowledge and expectations.
Curriculum goal masking for continuous deep reinforcement learning
Sep 17, 2018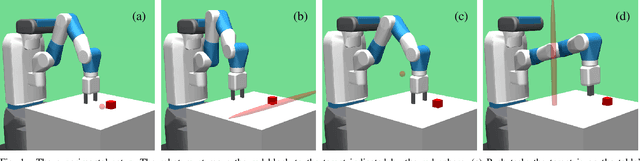
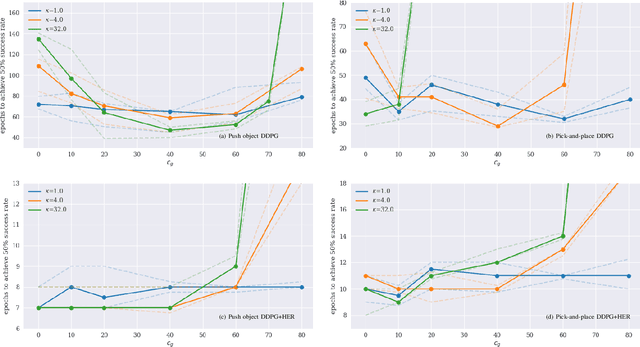
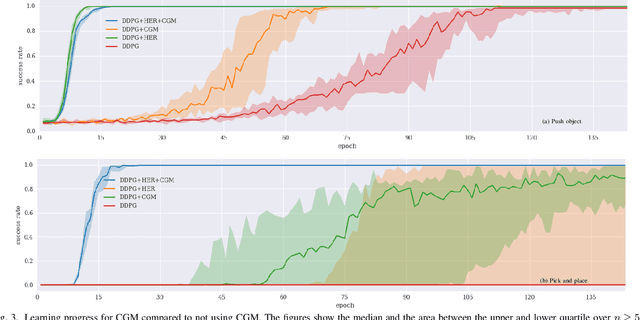
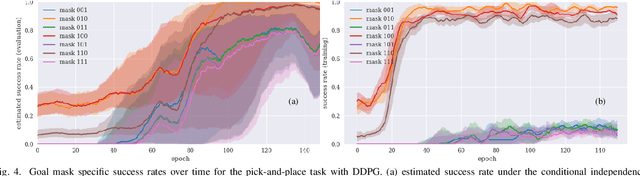
Deep reinforcement learning has recently gained a focus on problems where policy or value functions are independent of goals. Evidence exists that the sampling of goals has a strong effect on the learning performance, but there is a lack of general mechanisms that focus on optimizing the goal sampling process. In this work, we present a simple and general goal masking method that also allows us to estimate a goal's difficulty level and thus realize a curriculum learning approach for deep RL. Our results indicate that focusing on goals with a medium difficulty level is appropriate for deep deterministic policy gradient (DDPG) methods, while an "aim for the stars and reach the moon-strategy", where hard goals are sampled much more often than simple goals, leads to the best learning performance in cases where DDPG is combined with for hindsight experience replay (HER). We demonstrate that the approach significantly outperforms standard goal sampling for different robotic object manipulation problems.
Speeding up the Hyperparameter Optimization of Deep Convolutional Neural Networks
Jul 19, 2018

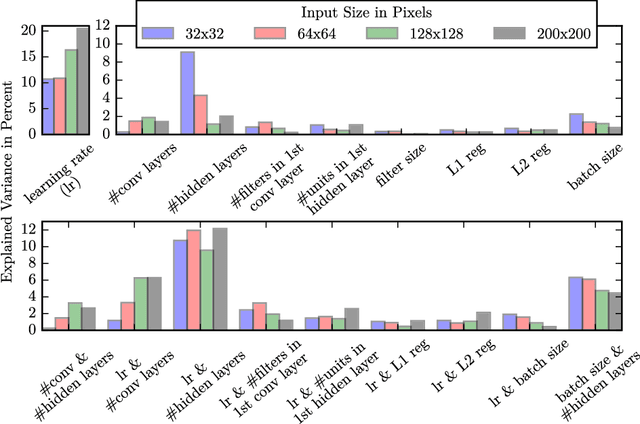
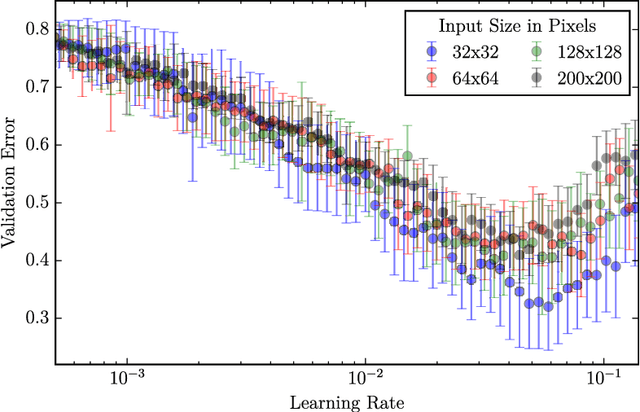
Most learning algorithms require the practitioner to manually set the values of many hyperparameters before the learning process can begin. However, with modern algorithms, the evaluation of a given hyperparameter setting can take a considerable amount of time and the search space is often very high-dimensional. We suggest using a lower-dimensional representation of the original data to quickly identify promising areas in the hyperparameter space. This information can then be used to initialize the optimization algorithm for the original, higher-dimensional data. We compare this approach with the standard procedure of optimizing the hyperparameters only on the original input. We perform experiments with various state-of-the-art hyperparameter optimization algorithms such as random search, the tree of parzen estimators (TPEs), sequential model-based algorithm configuration (SMAC), and a genetic algorithm (GA). Our experiments indicate that it is possible to speed up the optimization process by using lower-dimensional data representations at the beginning, while increasing the dimensionality of the input later in the optimization process. This is independent of the underlying optimization procedure, making the approach promising for many existing hyperparameter optimization algorithms.
* 15 pages, published in the International Journal of Computational Intelligence and Applications
Discourse-Wizard: Discovering Deep Discourse Structure in your Conversation with RNNs
Jun 29, 2018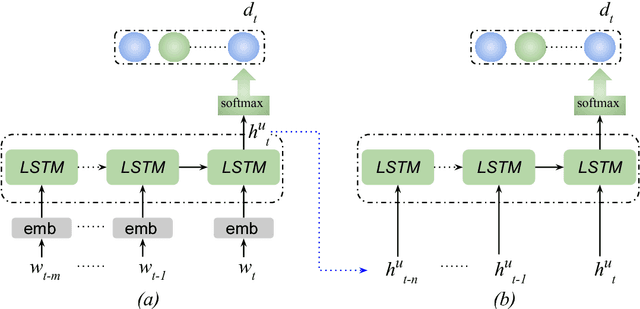

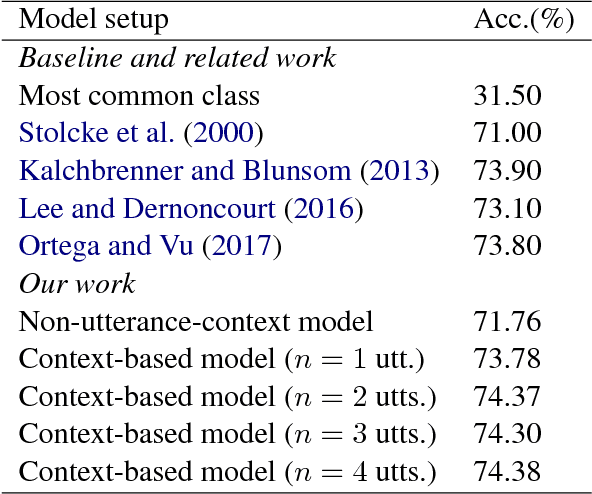
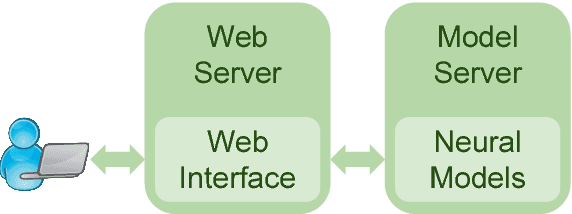
Spoken language understanding is one of the key factors in a dialogue system, and a context in a conversation plays an important role to understand the current utterance. In this work, we demonstrate the importance of context within the dialogue for neural network models through an online web interface live demo. We developed two different neural models: a model that does not use context and a context-based model. The no-context model classifies dialogue acts at an utterance-level whereas the context-based model takes some preceding utterances into account. We make these trained neural models available as a live demo called Discourse-Wizard using a modular server architecture. The live demo provides an easy to use interface for conversational analysis and for discovering deep discourse structures in a conversation.
Conversational Analysis using Utterance-level Attention-based Bidirectional Recurrent Neural Networks
Jun 20, 2018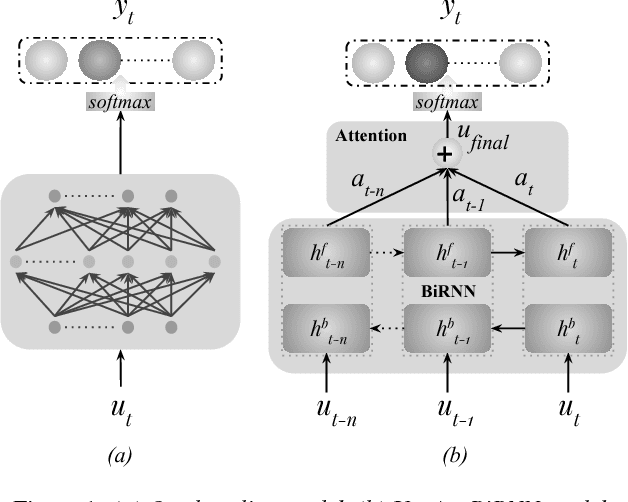
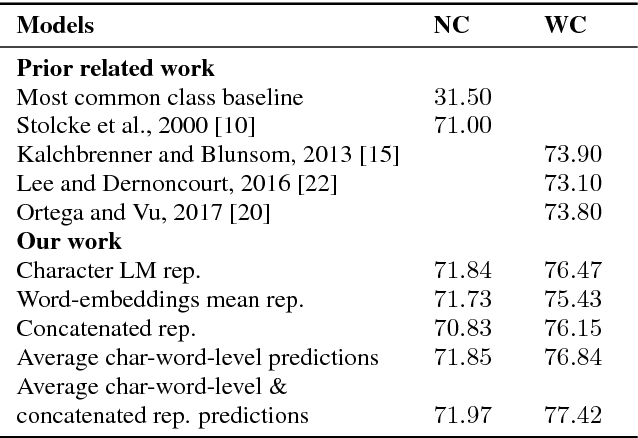
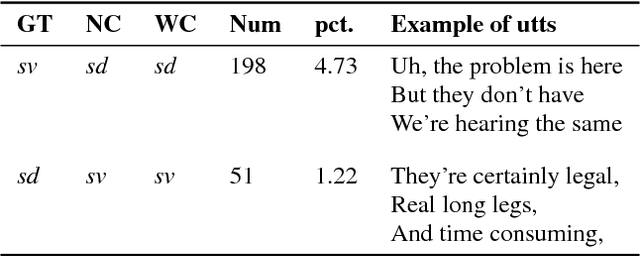
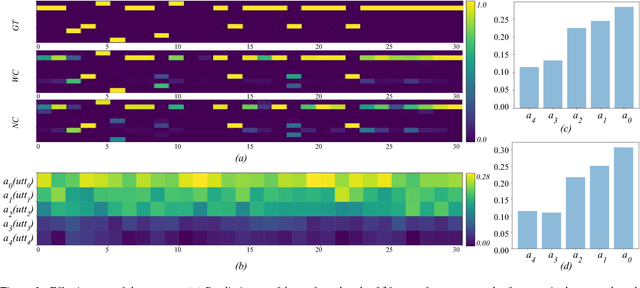
Recent approaches for dialogue act recognition have shown that context from preceding utterances is important to classify the subsequent one. It was shown that the performance improves rapidly when the context is taken into account. We propose an utterance-level attention-based bidirectional recurrent neural network (Utt-Att-BiRNN) model to analyze the importance of preceding utterances to classify the current one. In our setup, the BiRNN is given the input set of current and preceding utterances. Our model outperforms previous models that use only preceding utterances as context on the used corpus. Another contribution of the article is to discover the amount of information in each utterance to classify the subsequent one and to show that context-based learning not only improves the performance but also achieves higher confidence in the classification. We use character- and word-level features to represent the utterances. The results are presented for character and word feature representations and as an ensemble model of both representations. We found that when classifying short utterances, the closest preceding utterances contributes to a higher degree.