 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudoNeg-MAE: Self-Supervised Point Cloud Learning using Conditional Pseudo-Negative Embeddings
Sep 24, 2024We propose PseudoNeg-MAE, a novel self-supervised learning framework that enhances global feature representation of point cloud mask autoencoder by making them both discriminative and sensitive to transformations. Traditional contrastive learning methods focus on achieving invariance, which can lead to the loss of valuable transformation-related information. In contrast, PseudoNeg-MAE explicitly models the relationship between original and transformed data points using a parametric network COPE, which learns the localized displacements caused by transformations within the latent space. However, jointly training COPE with the MAE leads to undesirable trivial solutions where COPE outputs collapse to an identity. To address this, we introduce a novel loss function incorporating pseudo-negatives, which effectively penalizes these trivial invariant solutions and promotes transformation sensitivity in the embeddings. We validate PseudoNeg-MAE on shape classification and relative pose estimation tasks, where PseudoNeg-MAE achieves state-of-the-art performance on the ModelNet40 and ScanObjectNN datasets under challenging evaluation protocols and demonstrates superior accuracy in estimating relative poses. These results show the effectiveness of PseudoNeg-MAE in learning discriminative and transformation-sensitive representations.
Object Registration in Neural Fields
Apr 29, 2024



Neural fields provide a continuous scene representation of 3D geometry and appearance in a way which has great promise for robotics applications. One functionality that unlocks unique use-cases for neural fields in robotics is object 6-DoF registration. In this paper, we provide an expanded analysis of the recent Reg-NF neural field registration method and its use-cases within a robotics context. We showcase the scenario of determining the 6-DoF pose of known objects within a scene using scene and object neural field models. We show how this may be used to better represent objects within imperfectly modelled scenes and generate new scenes by substituting object neural field models into the scene.
Reg-NF: Efficient Registration of Implicit Surfaces within Neural Fields
Feb 15, 2024



Neural fields, coordinate-based neural networks, have recently gained popularity for implicitly representing a scene. In contrast to classical methods that are based on explicit representations such as point clouds, neural fields provide a continuous scene representation able to represent 3D geometry and appearance in a way which is compact and ideal for robotics applications. However, limited prior methods have investigated registering multiple neural fields by directly utilising these continuous implicit representations. In this paper, we present Reg-NF, a neural fields-based registration that optimises for the relative 6-DoF transformation between two arbitrary neural fields, even if those two fields have different scale factors. Key components of Reg-NF include a bidirectional registration loss, multi-view surface sampling, and utilisation of volumetric signed distance functions (SDFs). We showcase our approach on a new neural field dataset for evaluating registration problems. We provide an exhaustive set of experiments and ablation studies to identify the performance of our approach, while also discussing limitations to provide future direction to the research community on open challenges in utilizing neural fields in unconstrained environments.
Diverse Single Image Generation with Controllable Global Structure through Self-Attention
Feb 15, 2021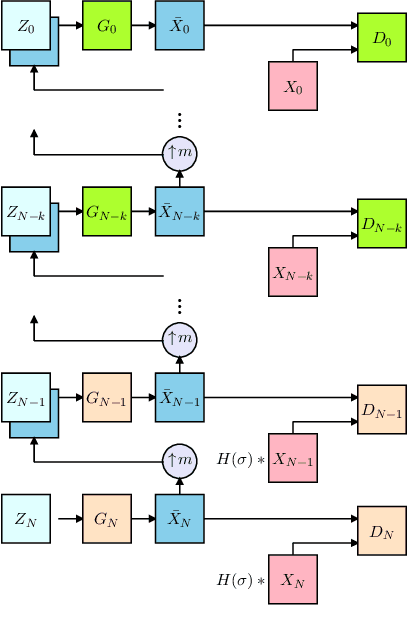

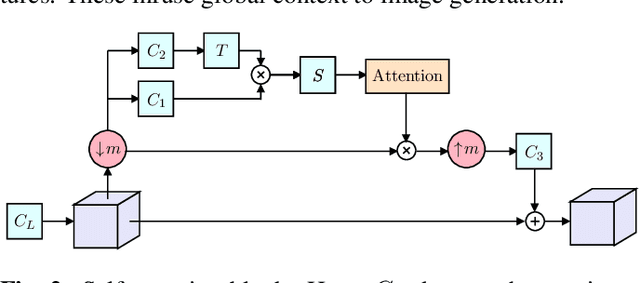
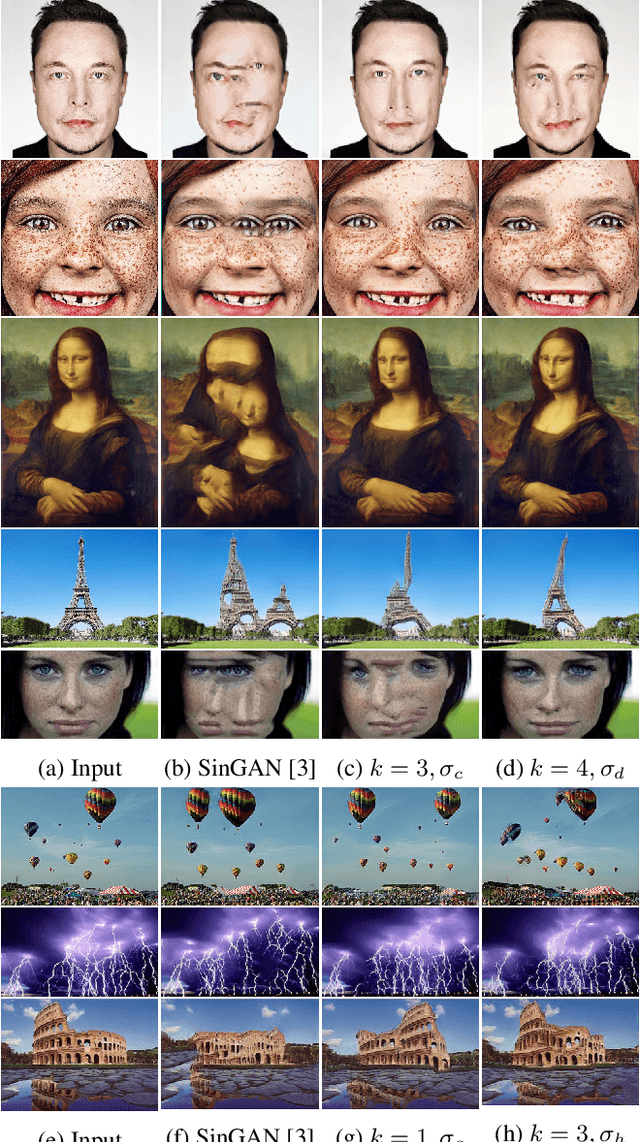
Image generation from a single image using generative adversarial networks is quite interesting due to the realism of generated images. However, recent approaches need improvement for such realistic and diverse image generation, when the global context of the image is important such as in face, animal, and architectural image generation. This is mainly due to the use of fewer convolutional layers for mainly capturing the patch statistics and, thereby, not being able to capture global statistics very well. We solve this problem by using attention blocks at selected scales and feeding a random Gaussian blurred image to the discriminator for training. Our results are visually better than the state-of-the-art particularly in generating images that require global context. The diversity of our image generation, measured using the average standard deviation of pixels, is also better.