 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Resilience in Sequential Prediction via Abstention
Jun 22, 2023We study the problem of sequential prediction in the stochastic setting with an adversary that is allowed to inject clean-label adversarial (or out-of-distribution) examples. Algorithms designed to handle purely stochastic data tend to fail in the presence of such adversarial examples, often leading to erroneous predictions. This is undesirable in many high-stakes applications such as medical recommendations, where abstaining from predictions on adversarial examples is preferable to misclassification. On the other hand, assuming fully adversarial data leads to very pessimistic bounds that are often vacuous in practice. To capture this motivation, we propose a new model of sequential prediction that sits between the purely stochastic and fully adversarial settings by allowing the learner to abstain from making a prediction at no cost on adversarial examples. Assuming access to the marginal distribution on the non-adversarial examples, we design a learner whose error scales with the VC dimension (mirroring the stochastic setting) of the hypothesis class, as opposed to the Littlestone dimension which characterizes the fully adversarial setting. Furthermore, we design a learner for VC dimension~1 classes, which works even in the absence of access to the marginal distribution. Our key technical contribution is a novel measure for quantifying uncertainty for learning VC classes, which may be of independent interest.
Exposing Attention Glitches with Flip-Flop Language Modeling
Jun 01, 2023



Why do large language models sometimes output factual inaccuracies and exhibit erroneous reasoning? The brittleness of these models, particularly when executing long chains of reasoning, currently seems to be an inevitable price to pay for their advanced capabilities of coherently synthesizing knowledge, pragmatics, and abstract thought. Towards making sense of this fundamentally unsolved problem, this work identifies and analyzes the phenomenon of attention glitches, in which the Transformer architecture's inductive biases intermittently fail to capture robust reasoning. To isolate the issue, we introduce flip-flop language modeling (FFLM), a parametric family of synthetic benchmarks designed to probe the extrapolative behavior of neural language models. This simple generative task requires a model to copy binary symbols over long-range dependencies, ignoring the tokens in between. We find that Transformer FFLMs suffer from a long tail of sporadic reasoning errors, some of which we can eliminate using various regularization techniques. Our preliminary mechanistic analyses show why the remaining errors may be very difficult to diagnose and resolve. We hypothesize that attention glitches account for (some of) the closed-domain hallucinations in natural LLMs.
Learning Narrow One-Hidden-Layer ReLU Networks
Apr 20, 2023

We consider the well-studied problem of learning a linear combination of $k$ ReLU activations with respect to a Gaussian distribution on inputs in $d$ dimensions. We give the first polynomial-time algorithm that succeeds whenever $k$ is a constant. All prior polynomial-time learners require additional assumptions on the network, such as positive combining coefficients or the matrix of hidden weight vectors being well-conditioned. Our approach is based on analyzing random contractions of higher-order moment tensors. We use a multi-scale analysis to argue that sufficiently close neurons can be collapsed together, sidestepping the conditioning issues present in prior work. This allows us to design an iterative procedure to discover individual neurons.
Transformers Learn Shortcuts to Automata
Oct 19, 2022Algorithmic reasoning requires capabilities which are most naturally understood through recurrent models of computation, like the Turing machine. However, Transformer models, while lacking recurrence, are able to perform such reasoning using far fewer layers than the number of reasoning steps. This raises the question: what solutions are these shallow and non-recurrent models finding? We investigate this question in the setting of learning automata, discrete dynamical systems naturally suited to recurrent modeling and expressing algorithmic tasks. Our theoretical results completely characterize shortcut solutions, whereby a shallow Transformer with only $o(T)$ layers can exactly replicate the computation of an automaton on an input sequence of length $T$. By representing automata using the algebraic structure of their underlying transformation semigroups, we obtain $O(\log T)$-depth simulators for all automata and $O(1)$-depth simulators for all automata whose associated groups are solvable. Empirically, we perform synthetic experiments by training Transformers to simulate a wide variety of automata, and show that shortcut solutions can be learned via standard training. We further investigate the brittleness of these solutions and propose potential mitigations.
Recurrent Convolutional Neural Networks Learn Succinct Learning Algorithms
Sep 01, 2022
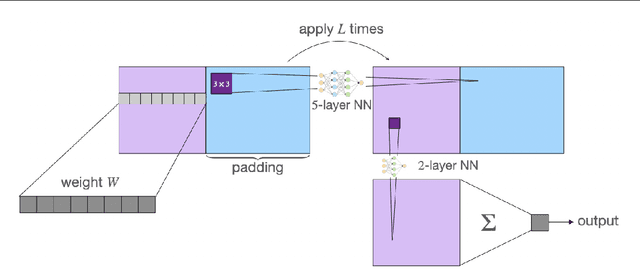
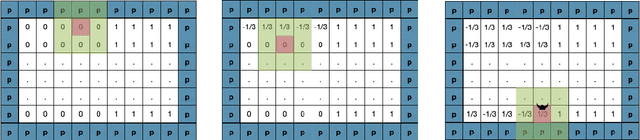
Neural Networks (NNs) struggle to efficiently learn certain problems, such as parity problems, even when there are simple learning algorithms for those problems. Can NNs discover learning algorithms on their own? We exhibit a NN architecture that, in polynomial time, learns as well as any efficient learning algorithm describable by a constant-sized learning algorithm. For example, on parity problems, the NN learns as well as row reduction, an efficient algorithm that can be succinctly described. Our architecture combines both recurrent weight-sharing between layers and convolutional weight-sharing to reduce the number of parameters down to a constant, even though the network itself may have trillions of nodes. While in practice the constants in our analysis are too large to be directly meaningful, our work suggests that the synergy of Recurrent and Convolutional NNs (RCNNs) may be more powerful than either alone.
Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit
Jul 18, 2022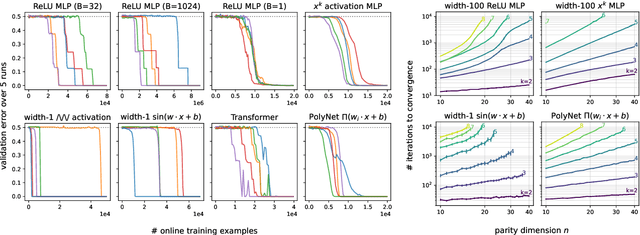
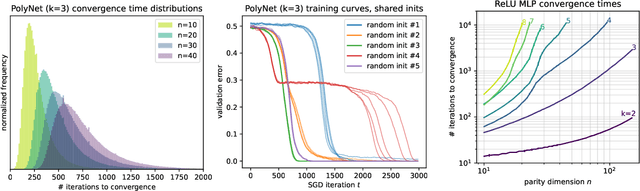
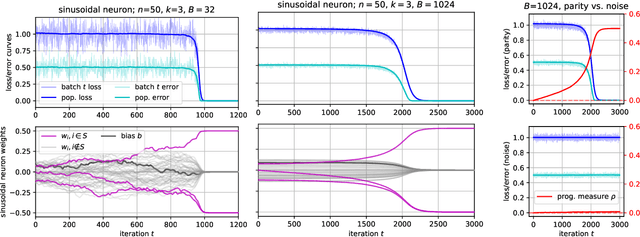
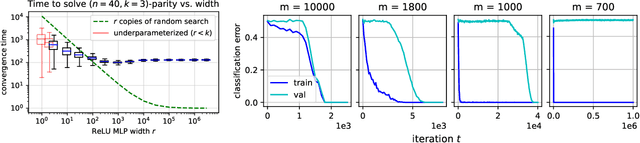
There is mounting empirical evidence of emergent phenomena in the capabilities of deep learning methods as we scale up datasets, model sizes, and training times. While there are some accounts of how these resources modulate statistical capacity, far less is known about their effect on the computational problem of model training. This work conducts such an exploration through the lens of learning $k$-sparse parities of $n$ bits, a canonical family of problems which pose theoretical computational barriers. In this setting, we find that neural networks exhibit surprising phase transitions when scaling up dataset size and running time. In particular, we demonstrate empirically that with standard training, a variety of architectures learn sparse parities with $n^{O(k)}$ examples, with loss (and error) curves abruptly dropping after $n^{O(k)}$ iterations. These positive results nearly match known SQ lower bounds, even without an explicit sparsity-promoting prior. We elucidate the mechanisms of these phenomena with a theoretical analysis: we find that the phase transition in performance is not due to SGD "stumbling in the dark" until it finds the hidden set of features (a natural algorithm which also runs in $n^{O(k)}$ time); instead, we show that SGD gradually amplifies a Fourier gap in the population gradient.
Understanding Contrastive Learning Requires Incorporating Inductive Biases
Feb 28, 2022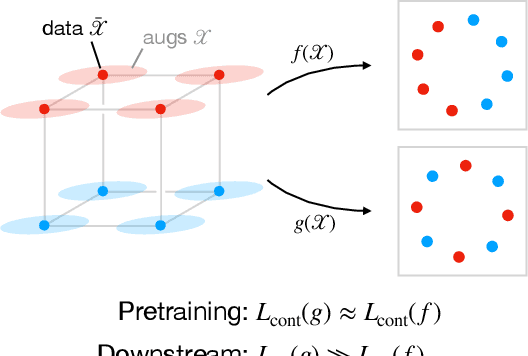
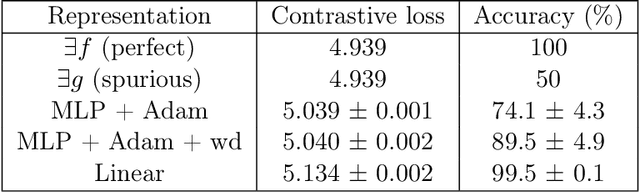
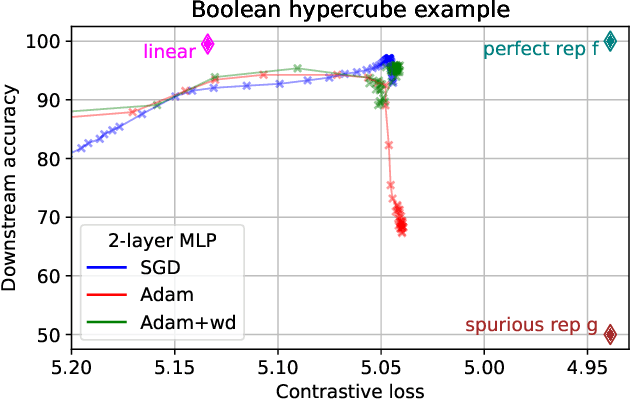
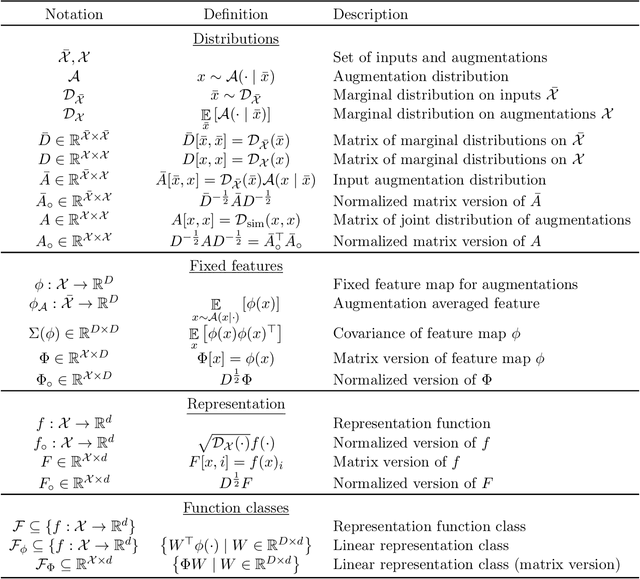
Contrastive learning is a popular form of self-supervised learning that encourages augmentations (views) of the same input to have more similar representations compared to augmentations of different inputs. Recent attempts to theoretically explain the success of contrastive learning on downstream classification tasks prove guarantees depending on properties of {\em augmentations} and the value of {\em contrastive loss} of representations. We demonstrate that such analyses, that ignore {\em inductive biases} of the function class and training algorithm, cannot adequately explain the success of contrastive learning, even {\em provably} leading to vacuous guarantees in some settings. Extensive experiments on image and text domains highlight the ubiquity of this problem -- different function classes and algorithms behave very differently on downstream tasks, despite having the same augmentations and contrastive losses. Theoretical analysis is presented for the class of linear representations, where incorporating inductive biases of the function class allows contrastive learning to work with less stringent conditions compared to prior analyses.
Anti-Concentrated Confidence Bonuses for Scalable Exploration
Oct 21, 2021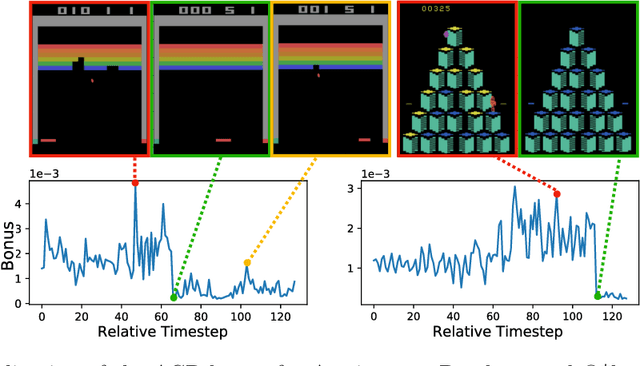
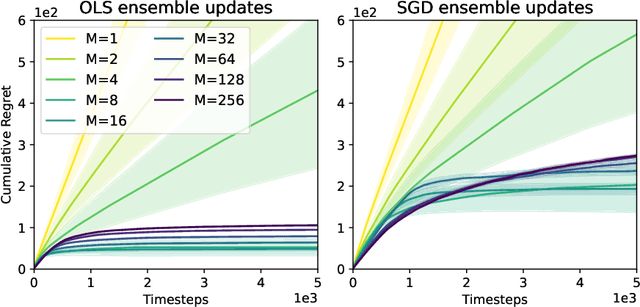


Intrinsic rewards play a central role in handling the exploration-exploitation trade-off when designing sequential decision-making algorithms, in both foundational theory and state-of-the-art deep reinforcement learning. The LinUCB algorithm, a centerpiece of the stochastic linear bandits literature, prescribes an elliptical bonus which addresses the challenge of leveraging shared information in large action spaces. This bonus scheme cannot be directly transferred to high-dimensional exploration problems, however, due to the computational cost of maintaining the inverse covariance matrix of action features. We introduce \emph{anti-concentrated confidence bounds} for efficiently approximating the elliptical bonus, using an ensemble of regressors trained to predict random noise from policy network-derived features. Using this approximation, we obtain stochastic linear bandit algorithms which obtain $\tilde O(d \sqrt{T})$ regret bounds for $\mathrm{poly}(d)$ fixed actions. We develop a practical variant for deep reinforcement learning that is competitive with contemporary intrinsic reward heuristics on Atari benchmarks.
Inductive Biases and Variable Creation in Self-Attention Mechanisms
Oct 19, 2021
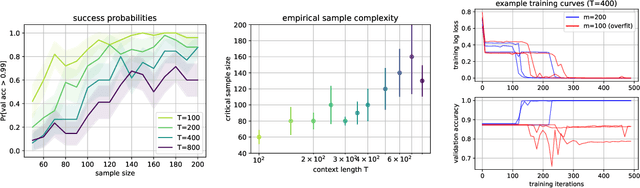
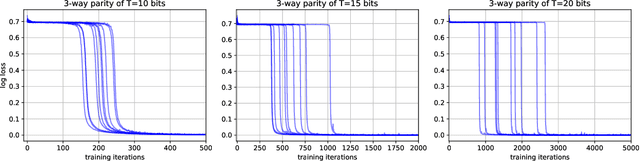
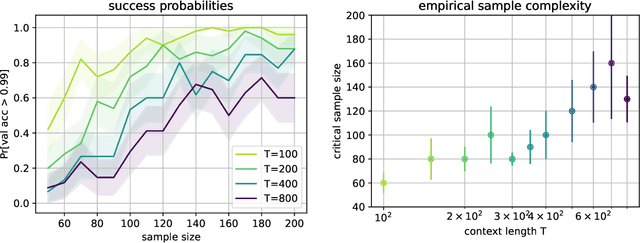
Self-attention, an architectural motif designed to model long-range interactions in sequential data, has driven numerous recent breakthroughs in natural language processing and beyond. This work provides a theoretical analysis of the inductive biases of self-attention modules, where our focus is to rigorously establish which functions and long-range dependencies self-attention blocks prefer to represent. Our main result shows that bounded-norm Transformer layers create sparse variables: they can represent sparse functions of the input sequence, with sample complexity scaling only logarithmically with the context length. Furthermore, we propose new experimental protocols to support this analysis and to guide the practice of training Transformers, built around the large body of work on provably learning sparse Boolean functions.
Statistical Estimation from Dependent Data
Jul 20, 2021
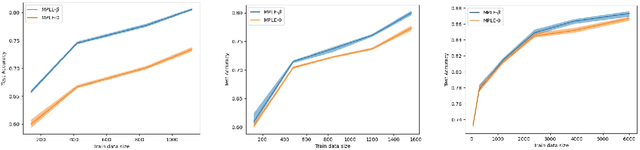

We consider a general statistical estimation problem wherein binary labels across different observations are not independent conditioned on their feature vectors, but dependent, capturing settings where e.g. these observations are collected on a spatial domain, a temporal domain, or a social network, which induce dependencies. We model these dependencies in the language of Markov Random Fields and, importantly, allow these dependencies to be substantial, i.e do not assume that the Markov Random Field capturing these dependencies is in high temperature. As our main contribution we provide algorithms and statistically efficient estimation rates for this model, giving several instantiations of our bounds in logistic regression, sparse logistic regression, and neural network settings with dependent data. Our estimation guarantees follow from novel results for estimating the parameters (i.e. external fields and interaction strengths) of Ising models from a {\em single} sample. {We evaluate our estimation approach on real networked data, showing that it outperforms standard regression approaches that ignore dependencies, across three text classification datasets: Cora, Citeseer and Pubmed.}