 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccumulating Risk Capital Through Investing in Cooperation
Jan 25, 2021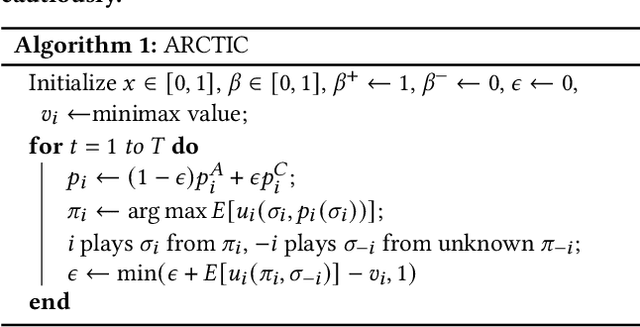
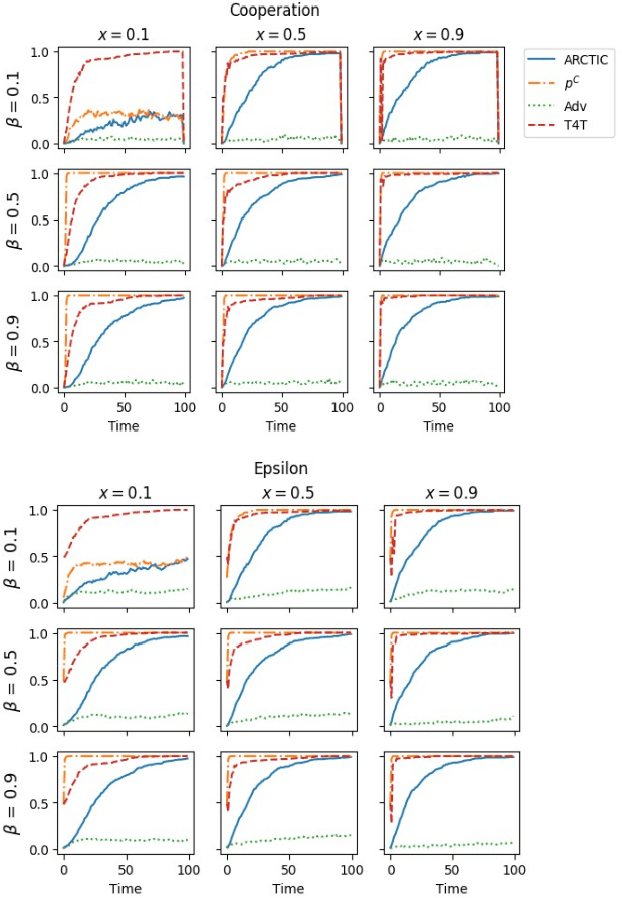
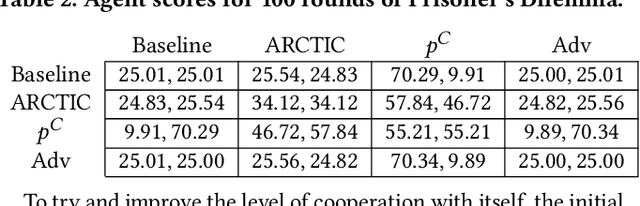
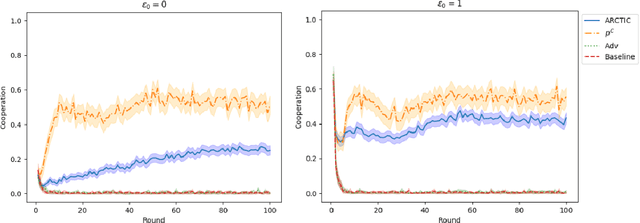
Recent work on promoting cooperation in multi-agent learning has resulted in many methods which successfully promote cooperation at the cost of becoming more vulnerable to exploitation by malicious actors. We show that this is an unavoidable trade-off and propose an objective which balances these concerns, promoting both safety and long-term cooperation. Moreover, the trade-off between safety and cooperation is not severe, and you can receive exponentially large returns through cooperation from a small amount of risk. We study both an exact solution method and propose a method for training policies that targets this objective, Accumulating Risk Capital Through Investing in Cooperation (ARCTIC), and evaluate them in iterated Prisoner's Dilemma and Stag Hunt.
Multi-Principal Assistance Games: Definition and Collegial Mechanisms
Dec 29, 2020We introduce the concept of a multi-principal assistance game (MPAG), and circumvent an obstacle in social choice theory, Gibbard's theorem, by using a sufficiently collegial preference inference mechanism. In an MPAG, a single agent assists N human principals who may have widely different preferences. MPAGs generalize assistance games, also known as cooperative inverse reinforcement learning games. We analyze in particular a generalization of apprenticeship learning in which the humans first perform some work to obtain utility and demonstrate their preferences, and then the robot acts to further maximize the sum of human payoffs. We show in this setting that if the game is sufficiently collegial, i.e. if the humans are responsible for obtaining a sufficient fraction of the rewards through their own actions, then their preferences are straightforwardly revealed through their work. This revelation mechanism is non-dictatorial, does not limit the possible outcomes to two alternatives, and is dominant-strategy incentive-compatible.
Understanding Learned Reward Functions
Dec 10, 2020

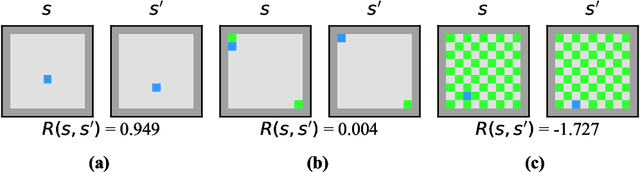
In many real-world tasks, it is not possible to procedurally specify an RL agent's reward function. In such cases, a reward function must instead be learned from interacting with and observing humans. However, current techniques for reward learning may fail to produce reward functions which accurately reflect user preferences. Absent significant advances in reward learning, it is thus important to be able to audit learned reward functions to verify whether they truly capture user preferences. In this paper, we investigate techniques for interpreting learned reward functions. In particular, we apply saliency methods to identify failure modes and predict the robustness of reward functions. We find that learned reward functions often implement surprising algorithms that rely on contingent aspects of the environment. We also discover that existing interpretability techniques often attend to irrelevant changes in reward output, suggesting that reward interpretability may need significantly different methods from policy interpretability.
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design
Dec 03, 2020

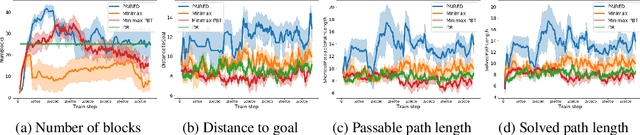
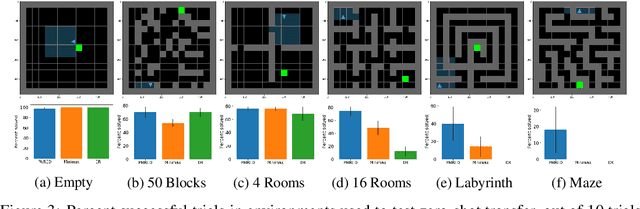
A wide range of reinforcement learning (RL) problems - including robustness, transfer learning, unsupervised RL, and emergent complexity - require specifying a distribution of tasks or environments in which a policy will be trained. However, creating a useful distribution of environments is error prone, and takes a significant amount of developer time and effort. We propose Unsupervised Environment Design (UED) as an alternative paradigm, where developers provide environments with unknown parameters, and these parameters are used to automatically produce a distribution over valid, solvable environments. Existing approaches to automatically generating environments suffer from common failure modes: domain randomization cannot generate structure or adapt the difficulty of the environment to the agent's learning progress, and minimax adversarial training leads to worst-case environments that are often unsolvable. To generate structured, solvable environments for our protagonist agent, we introduce a second, antagonist agent that is allied with the environment-generating adversary. The adversary is motivated to generate environments which maximize regret, defined as the difference between the protagonist and antagonist agent's return. We call our technique Protagonist Antagonist Induced Regret Environment Design (PAIRED). Our experiments demonstrate that PAIRED produces a natural curriculum of increasingly complex environments, and PAIRED agents achieve higher zero-shot transfer performance when tested in highly novel environments.
DERAIL: Diagnostic Environments for Reward And Imitation Learning
Dec 02, 2020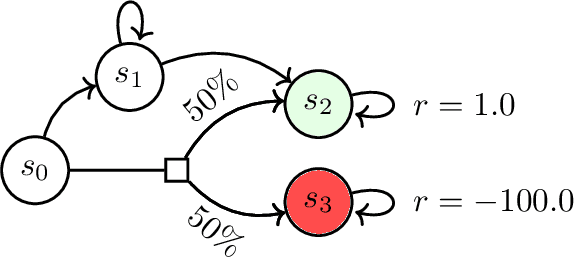
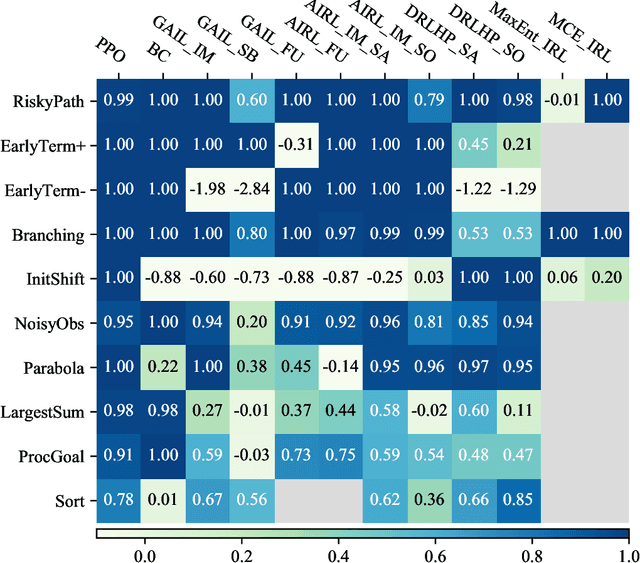
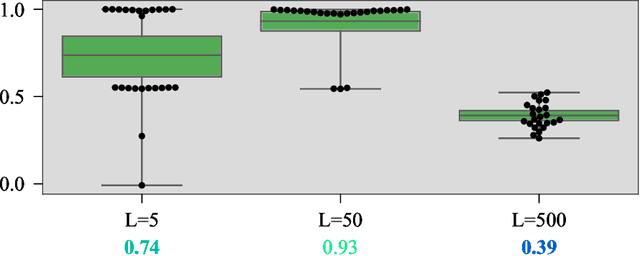
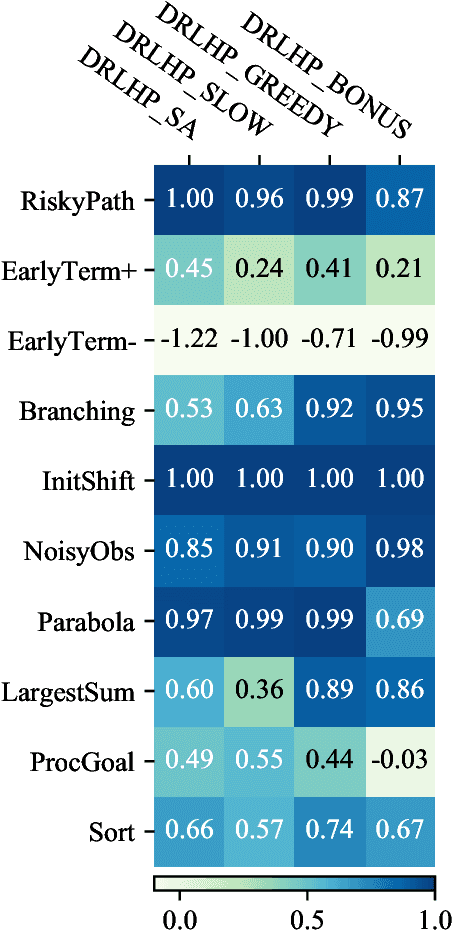
The objective of many real-world tasks is complex and difficult to procedurally specify. This makes it necessary to use reward or imitation learning algorithms to infer a reward or policy directly from human data. Existing benchmarks for these algorithms focus on realism, testing in complex environments. Unfortunately, these benchmarks are slow, unreliable and cannot isolate failures. As a complementary approach, we develop a suite of simple diagnostic tasks that test individual facets of algorithm performance in isolation. We evaluate a range of common reward and imitation learning algorithms on our tasks. Our results confirm that algorithm performance is highly sensitive to implementation details. Moreover, in a case-study into a popular preference-based reward learning implementation, we illustrate how the suite can pinpoint design flaws and rapidly evaluate candidate solutions. The environments are available at https://github.com/HumanCompatibleAI/seals .
The MAGICAL Benchmark for Robust Imitation
Nov 01, 2020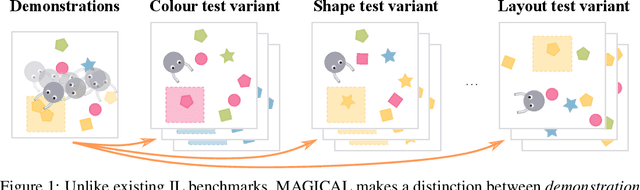
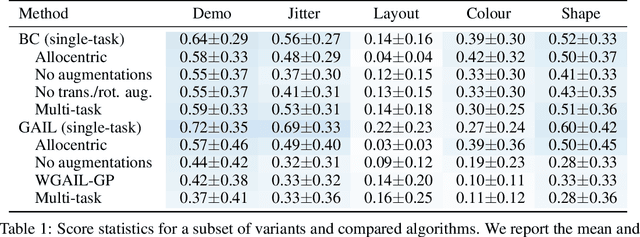

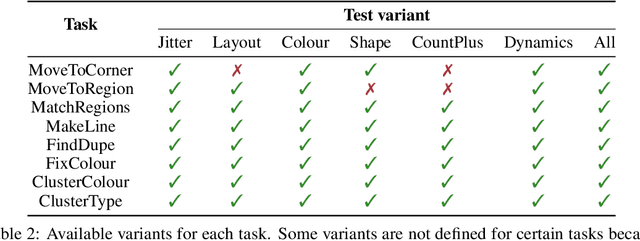
Imitation Learning (IL) algorithms are typically evaluated in the same environment that was used to create demonstrations. This rewards precise reproduction of demonstrations in one particular environment, but provides little information about how robustly an algorithm can generalise the demonstrator's intent to substantially different deployment settings. This paper presents the MAGICAL benchmark suite, which permits systematic evaluation of generalisation by quantifying robustness to different kinds of distribution shift that an IL algorithm is likely to encounter in practice. Using the MAGICAL suite, we confirm that existing IL algorithms overfit significantly to the context in which demonstrations are provided. We also show that standard methods for reducing overfitting are effective at creating narrow perceptual invariances, but are not sufficient to enable transfer to contexts that require substantially different behaviour, which suggests that new approaches will be needed in order to robustly generalise demonstrator intent. Code and data for the MAGICAL suite is available at https://github.com/qxcv/magical/.
SLIP: Learning to Predict in Unknown Dynamical Systems with Long-Term Memory
Oct 12, 2020
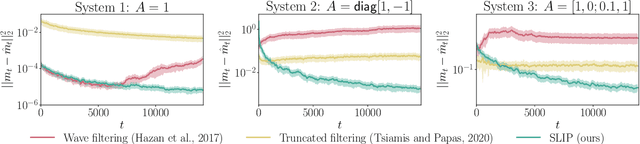
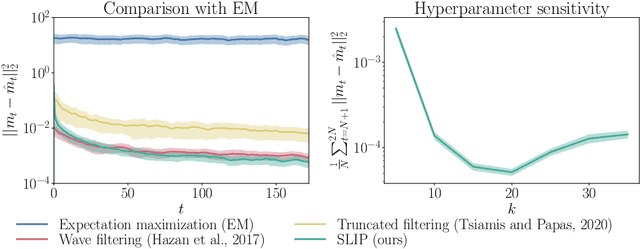
We present an efficient and practical (polynomial time) algorithm for online prediction in unknown and partially observed linear dynamical systems (LDS) under stochastic noise. When the system parameters are known, the optimal linear predictor is the Kalman filter. However, the performance of existing predictive models is poor in important classes of LDS that are only marginally stable and exhibit long-term forecast memory. We tackle this problem through bounding the generalized Kolmogorov width of the Kalman filter model by spectral methods and conducting tight convex relaxation. We provide a finite-sample analysis, showing that our algorithm competes with Kalman filter in hindsight with only logarithmic regret. Our regret analysis relies on Mendelson's small-ball method, providing sharp error bounds without concentration, boundedness, or exponential forgetting assumptions. We also give experimental results demonstrating that our algorithm outperforms state-of-the-art methods. Our theoretical and experimental results shed light on the conditions required for efficient probably approximately correct (PAC) learning of the Kalman filter from partially observed data.
Multi-Principal Assistance Games
Jul 19, 2020
Assistance games (also known as cooperative inverse reinforcement learning games) have been proposed as a model for beneficial AI, wherein a robotic agent must act on behalf of a human principal but is initially uncertain about the humans payoff function. This paper studies multi-principal assistance games, which cover the more general case in which the robot acts on behalf of N humans who may have widely differing payoffs. Impossibility theorems in social choice theory and voting theory can be applied to such games, suggesting that strategic behavior by the human principals may complicate the robots task in learning their payoffs. We analyze in particular a bandit apprentice game in which the humans act first to demonstrate their individual preferences for the arms and then the robot acts to maximize the sum of human payoffs. We explore the extent to which the cost of choosing suboptimal arms reduces the incentive to mislead, a form of natural mechanism design. In this context we propose a social choice method that uses shared control of a system to combine preference inference with social welfare optimization.
Quantifying Differences in Reward Functions
Jun 24, 2020
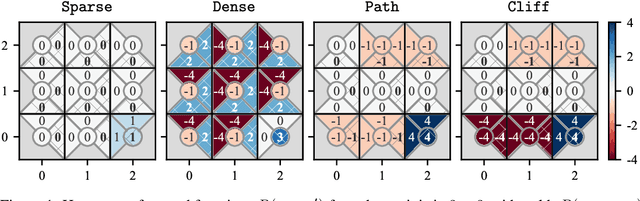

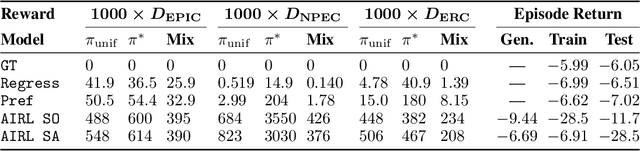
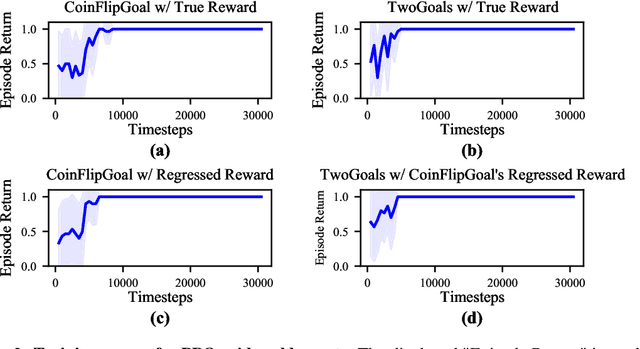
For many tasks, the reward function is too complex to be specified procedurally, and must instead be learned from user data. Prior work has evaluated learned reward functions by examining rollouts from a policy optimized for the learned reward. However, this method cannot distinguish between the learned reward function failing to reflect user preferences, and the reinforcement learning algorithm failing to optimize the learned reward. Moreover, the rollout method is highly sensitive to details of the environment the learned reward is evaluated in, which often differ in the deployment environment. To address these problems, we introduce the Equivalent-Policy Invariant Comparison (EPIC) distance to quantify the difference between two reward functions directly, without training a policy. We prove EPIC is invariant on an equivalence class of reward functions that always induce the same optimal policy. Furthermore, we find EPIC can be precisely approximated and is more robust than baselines to the choice of visitation distribution. Finally, we find that the EPIC distance of learned reward functions to the ground-truth reward is predictive of the success of training a policy, even in different transition dynamics.
Neural Networks are Surprisingly Modular
Mar 11, 2020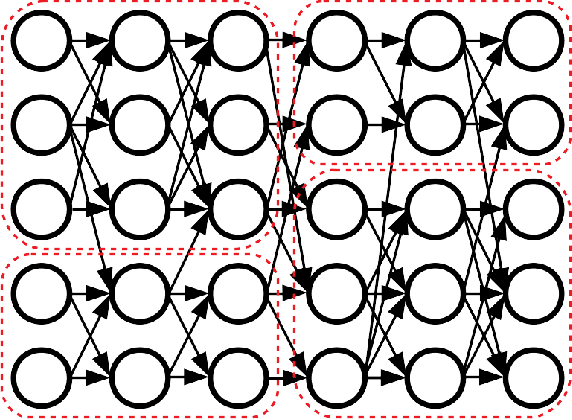

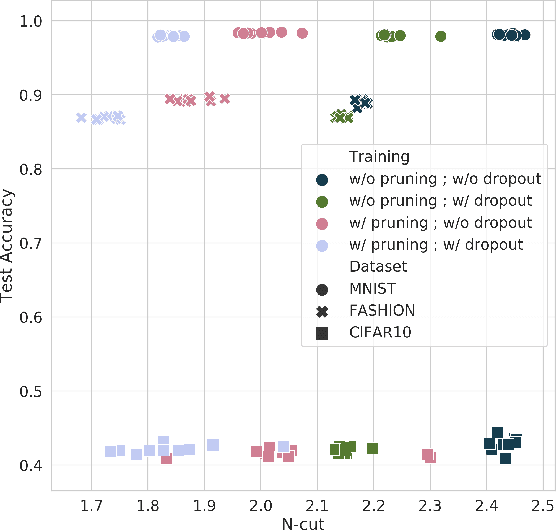

The learned weights of a neural network are often considered devoid of scrutable internal structure. In order to attempt to discern structure in these weights, we introduce a measurable notion of modularity for multi-layer perceptrons (MLPs), and investigate the modular structure of MLPs trained on datasets of small images. Our notion of modularity comes from the graph clustering literature: a "module" is a set of neurons with strong internal connectivity but weak external connectivity. We find that MLPs that undergo training and weight pruning are often significantly more modular than random networks with the same distribution of weights. Interestingly, they are much more modular when trained with dropout. Further analysis shows that this modularity seems to arise mostly for networks trained on learnable datasets. We also present exploratory analyses of the importance of different modules for performance and how modules depend on each other. Understanding the modular structure of neural networks, when such structure exists, will hopefully render their inner workings more interpretable to engineers.