 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraZoom: Generating Gigapixel Images from Regular Photos
Jun 16, 2025We present UltraZoom, a system for generating gigapixel-resolution images of objects from casually captured inputs, such as handheld phone photos. Given a full-shot image (global, low-detail) and one or more close-ups (local, high-detail), UltraZoom upscales the full image to match the fine detail and scale of the close-up examples. To achieve this, we construct a per-instance paired dataset from the close-ups and adapt a pretrained generative model to learn object-specific low-to-high resolution mappings. At inference, we apply the model in a sliding window fashion over the full image. Constructing these pairs is non-trivial: it requires registering the close-ups within the full image for scale estimation and degradation alignment. We introduce a simple, robust method for getting registration on arbitrary materials in casual, in-the-wild captures. Together, these components form a system that enables seamless pan and zoom across the entire object, producing consistent, photorealistic gigapixel imagery from minimal input.
Generating Fit Check Videos with a Handheld Camera
May 29, 2025Self-captured full-body videos are popular, but most deployments require mounted cameras, carefully-framed shots, and repeated practice. We propose a more convenient solution that enables full-body video capture using handheld mobile devices. Our approach takes as input two static photos (front and back) of you in a mirror, along with an IMU motion reference that you perform while holding your mobile phone, and synthesizes a realistic video of you performing a similar target motion. We enable rendering into a new scene, with consistent illumination and shadows. We propose a novel video diffusion-based model to achieve this. Specifically, we propose a parameter-free frame generation strategy, as well as a multi-reference attention mechanism, that effectively integrate appearance information from both the front and back selfies into the video diffusion model. Additionally, we introduce an image-based fine-tuning strategy to enhance frame sharpness and improve the generation of shadows and reflections, achieving a more realistic human-scene composition.
MusicInfuser: Making Video Diffusion Listen and Dance
Mar 18, 2025We introduce MusicInfuser, an approach for generating high-quality dance videos that are synchronized to a specified music track. Rather than attempting to design and train a new multimodal audio-video model, we show how existing video diffusion models can be adapted to align with musical inputs by introducing lightweight music-video cross-attention and a low-rank adapter. Unlike prior work requiring motion capture data, our approach fine-tunes only on dance videos. MusicInfuser achieves high-quality music-driven video generation while preserving the flexibility and generative capabilities of the underlying models. We introduce an evaluation framework using Video-LLMs to assess multiple dimensions of dance generation quality. The project page and code are available at https://susunghong.github.io/MusicInfuser.
Constrained Diffusion Implicit Models
Nov 01, 2024



This paper describes an efficient algorithm for solving noisy linear inverse problems using pretrained diffusion models. Extending the paradigm of denoising diffusion implicit models (DDIM), we propose constrained diffusion implicit models (CDIM) that modify the diffusion updates to enforce a constraint upon the final output. For noiseless inverse problems, CDIM exactly satisfies the constraints; in the noisy case, we generalize CDIM to satisfy an exact constraint on the residual distribution of the noise. Experiments across a variety of tasks and metrics show strong performance of CDIM, with analogous inference acceleration to unconstrained DDIM: 10 to 50 times faster than previous conditional diffusion methods. We demonstrate the versatility of our approach on many problems including super-resolution, denoising, inpainting, deblurring, and 3D point cloud reconstruction.
Inverse Painting: Reconstructing The Painting Process
Sep 30, 2024



Given an input painting, we reconstruct a time-lapse video of how it may have been painted. We formulate this as an autoregressive image generation problem, in which an initially blank "canvas" is iteratively updated. The model learns from real artists by training on many painting videos. Our approach incorporates text and region understanding to define a set of painting "instructions" and updates the canvas with a novel diffusion-based renderer. The method extrapolates beyond the limited, acrylic style paintings on which it has been trained, showing plausible results for a wide range of artistic styles and genres.
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Aug 27, 2024



We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments show that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.
Infinite Texture: Text-guided High Resolution Diffusion Texture Synthesis
May 13, 2024



We present Infinite Texture, a method for generating arbitrarily large texture images from a text prompt. Our approach fine-tunes a diffusion model on a single texture, and learns to embed that statistical distribution in the output domain of the model. We seed this fine-tuning process with a sample texture patch, which can be optionally generated from a text-to-image model like DALL-E 2. At generation time, our fine-tuned diffusion model is used through a score aggregation strategy to generate output texture images of arbitrary resolution on a single GPU. We compare synthesized textures from our method to existing work in patch-based and deep learning texture synthesis methods. We also showcase two applications of our generated textures in 3D rendering and texture transfer.
Don't Look at the Camera: Achieving Perceived Eye Contact
Apr 26, 2024



We consider the question of how to best achieve the perception of eye contact when a person is captured by camera and then rendered on a 2D display. For single subjects photographed by a camera, conventional wisdom tells us that looking directly into the camera achieves eye contact. Through empirical user studies, we show that it is instead preferable to {\em look just below the camera lens}. We quantitatively assess where subjects should direct their gaze relative to a camera lens to optimize the perception that they are making eye contact.
HRTF Estimation in the Wild
Nov 06, 2023



Head Related Transfer Functions (HRTFs) play a crucial role in creating immersive spatial audio experiences. However, HRTFs differ significantly from person to person, and traditional methods for estimating personalized HRTFs are expensive, time-consuming, and require specialized equipment. We imagine a world where your personalized HRTF can be determined by capturing data through earbuds in everyday environments. In this paper, we propose a novel approach for deriving personalized HRTFs that only relies on in-the-wild binaural recordings and head tracking data. By analyzing how sounds change as the user rotates their head through different environments with different noise sources, we can accurately estimate their personalized HRTF. Our results show that our predicted HRTFs closely match ground-truth HRTFs measured in an anechoic chamber. Furthermore, listening studies demonstrate that our personalized HRTFs significantly improve sound localization and reduce front-back confusion in virtual environments. Our approach offers an efficient and accessible method for deriving personalized HRTFs and has the potential to greatly improve spatial audio experiences.
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022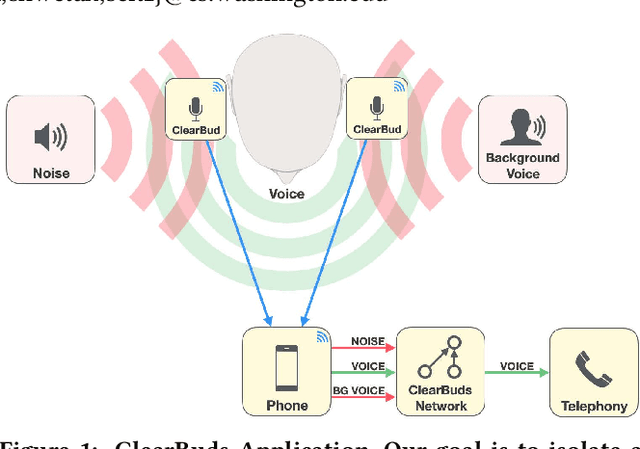

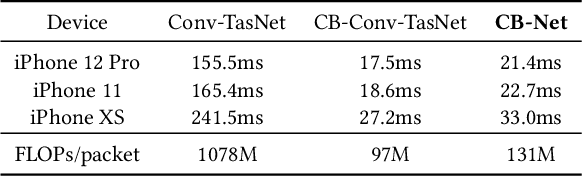
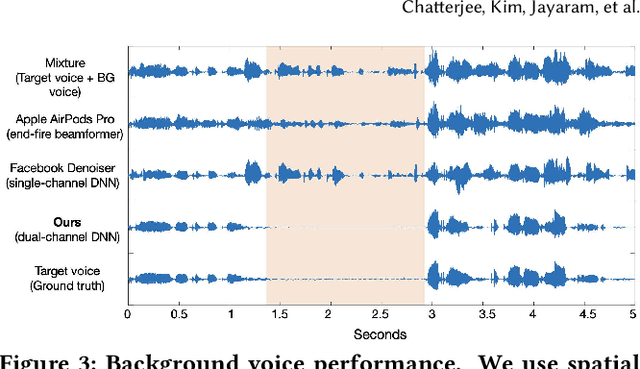
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu