 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterrogating Design Homogenization in Web Vibe Coding
Mar 13, 2026Generative AI is known for its tendency to homogenize, often reproducing dominant style conventions found in training data. However, it remains unclear how these homogenizing effects extend to complex structural tasks like web design. As lay creators increasingly turn to LLMs to 'vibe-code' websites -- prompting for aesthetic and functional goals rather than writing code -- they may inadvertently narrow the diversity of their designs, and limit creative expression throughout the internet. In this paper, we interrogate the possibility of design homogenization in web vibe coding. We first characterize the vibe coding lifecycle, pinpointing stages where homogenization risks may arise. We then conduct a sociotechnical risk analysis unpacking the potential harms of web vibe coding and their interaction with design homogenization. We identify that the push for frictionless generation can exacerbate homogenization and its harms. Finally, we propose a mitigation framework centered on the idea of productive friction. Through case studies at the micro, meso, and macro levels, we show how centering productive friction can empower creators to challenge default outputs and preserve diverse expression in AI-mediated web design.
Risks and NLP Design: A Case Study on Procedural Document QA
Aug 16, 2024As NLP systems are increasingly deployed at scale, concerns about their potential negative impacts have attracted the attention of the research community, yet discussions of risk have mostly been at an abstract level and focused on generic AI or NLP applications. We argue that clearer assessments of risks and harms to users--and concrete strategies to mitigate them--will be possible when we specialize the analysis to more concrete applications and their plausible users. As an illustration, this paper is grounded in cooking recipe procedural document question answering (ProcDocQA), where there are well-defined risks to users such as injuries or allergic reactions. Our case study shows that an existing language model, applied in "zero-shot" mode, quantitatively answers real-world questions about recipes as well or better than the humans who have answered the questions on the web. Using a novel questionnaire informed by theoretical work on AI risk, we conduct a risk-oriented error analysis that could then inform the design of a future system to be deployed with lower risk of harm and better performance.
Don't Look at the Camera: Achieving Perceived Eye Contact
Apr 26, 2024



We consider the question of how to best achieve the perception of eye contact when a person is captured by camera and then rendered on a 2D display. For single subjects photographed by a camera, conventional wisdom tells us that looking directly into the camera achieves eye contact. Through empirical user studies, we show that it is instead preferable to {\em look just below the camera lens}. We quantitatively assess where subjects should direct their gaze relative to a camera lens to optimize the perception that they are making eye contact.
COVID-VIT: Classification of COVID-19 from CT chest images based on vision transformer models
Jul 04, 2021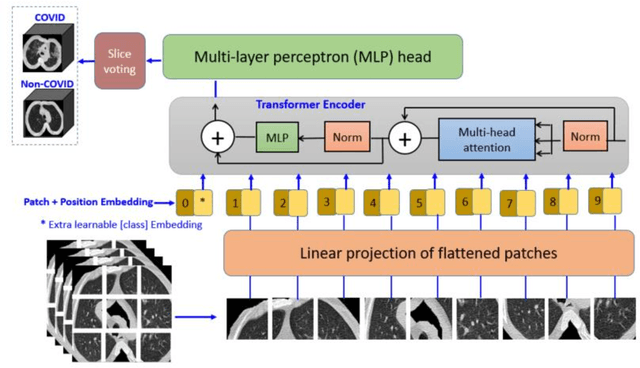

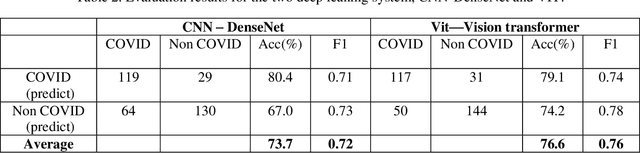
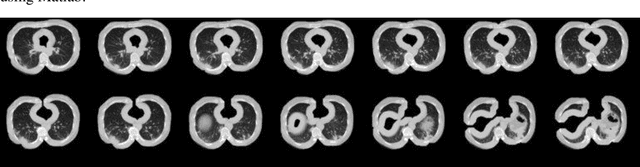
This paper is responding to the MIA-COV19 challenge to classify COVID from non-COVID based on CT lung images. The COVID-19 virus has devastated the world in the last eighteen months by infecting more than 182 million people and causing over 3.9 million deaths. The overarching aim is to predict the diagnosis of the COVID-19 virus from chest radiographs, through the development of explainable vision transformer deep learning techniques, leading to population screening in a more rapid, accurate and transparent way. In this competition, there are 5381 three-dimensional (3D) datasets in total, including 1552 for training, 374 for evaluation and 3455 for testing. While most of the data volumes are in axial view, there are a number of subjects' data are in coronal or sagittal views with 1 or 2 slices are in axial view. Hence, while 3D data based classification is investigated, in this competition, 2D images remains the main focus. Two deep learning methods are studied, which are vision transformer (ViT) based on attention models and DenseNet that is built upon conventional convolutional neural network (CNN). Initial evaluation results based on validation datasets whereby the ground truth is known indicate that ViT performs better than DenseNet with F1 scores being 0.76 and 0.72 respectively. Codes are available at GitHub at <https://github/xiaohong1/COVID-ViT>.