 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Spectral Kernels
Oct 09, 2015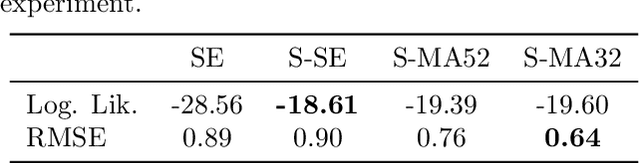
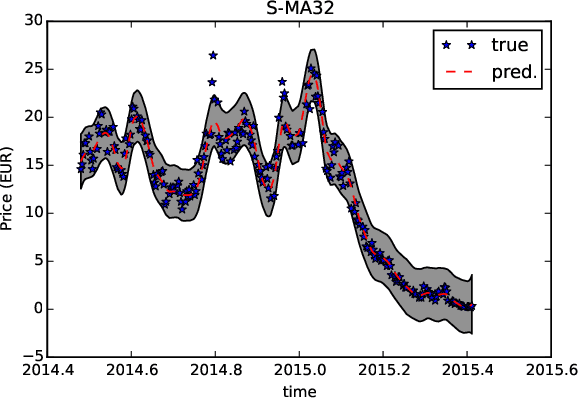
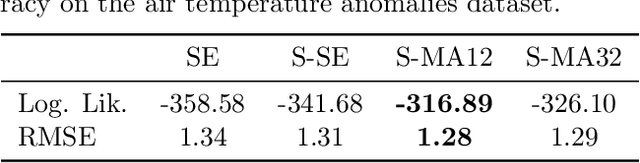
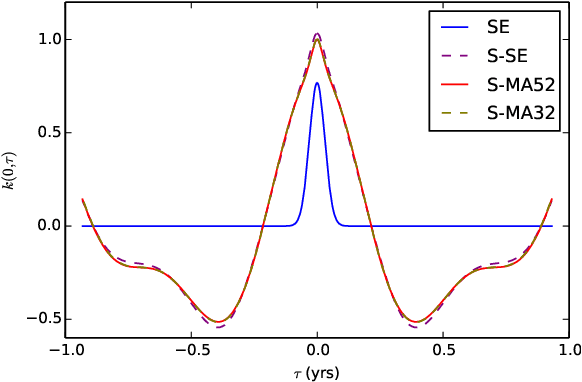
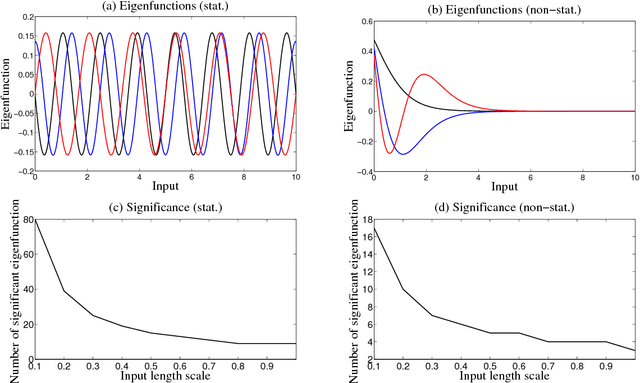
In this paper we propose a family of tractable kernels that is dense in the family of bounded positive semi-definite functions (i.e. can approximate any bounded kernel with arbitrary precision). We start by discussing the case of stationary kernels, and propose a family of spectral kernels that extends existing approaches such as spectral mixture kernels and sparse spectrum kernels. Our extension has two primary advantages. Firstly, unlike existing spectral approaches that yield infinite differentiability, the kernels we introduce allow learning the degree of differentiability of the latent function in Gaussian process (GP) models and functions in the reproducing kernel Hilbert space (RKHS) in other kernel methods. Secondly, we show that some of the kernels we propose require fewer parameters than existing spectral kernels for the same accuracy, thereby leading to faster and more robust inference. Finally, we generalize our approach and propose a flexible and tractable family of spectral kernels that we prove can approximate any continuous bounded nonstationary kernel.
Anomaly Detection and Removal Using Non-Stationary Gaussian Processes
Jul 02, 2015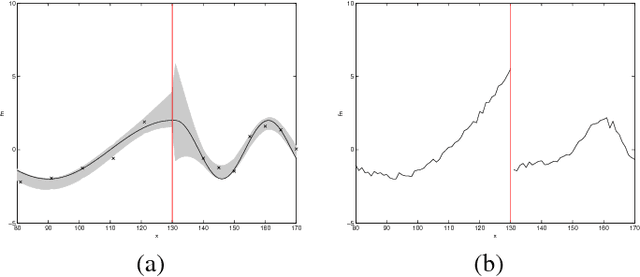
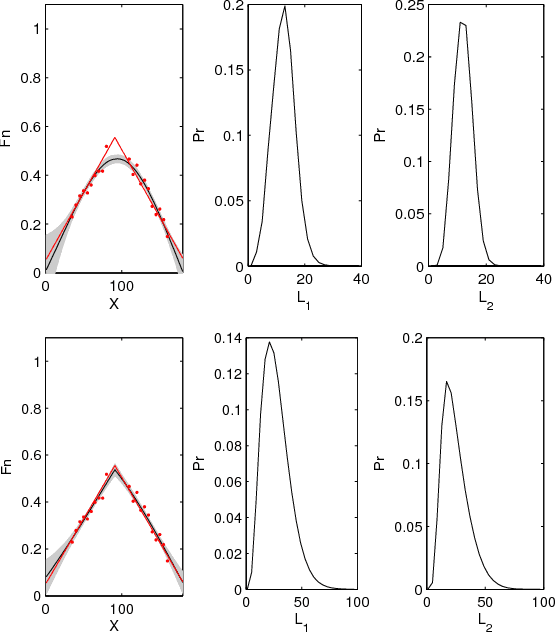
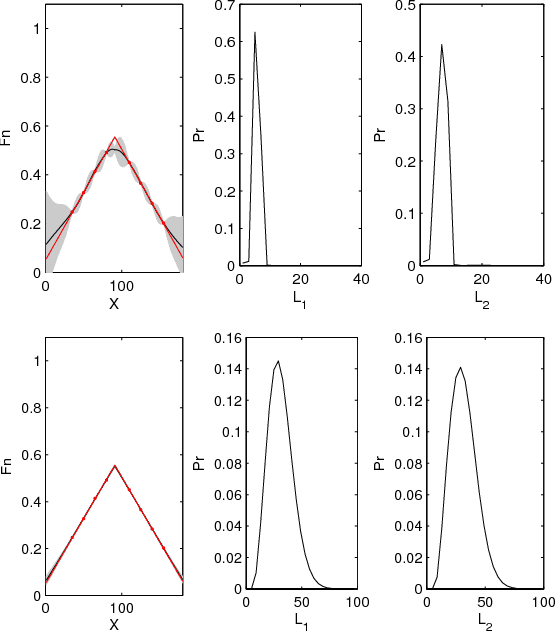
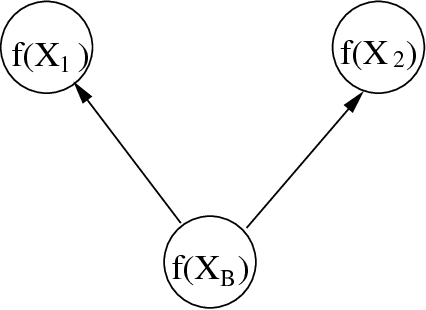
This paper proposes a novel Gaussian process approach to fault removal in time-series data. Fault removal does not delete the faulty signal data but, instead, massages the fault from the data. We assume that only one fault occurs at any one time and model the signal by two separate non-parametric Gaussian process models for both the physical phenomenon and the fault. In order to facilitate fault removal we introduce the Markov Region Link kernel for handling non-stationary Gaussian processes. This kernel is piece-wise stationary but guarantees that functions generated by it and their derivatives (when required) are everywhere continuous. We apply this kernel to the removal of drift and bias errors in faulty sensor data and also to the recovery of EOG artifact corrupted EEG signals.
String Gaussian Process Kernels
Jun 07, 2015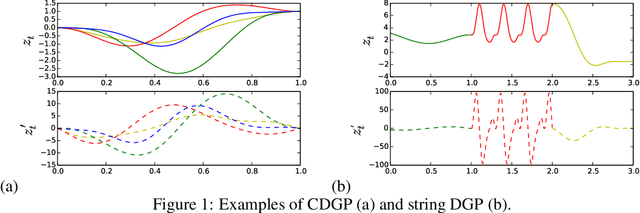
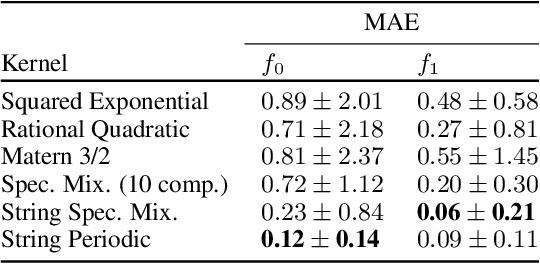
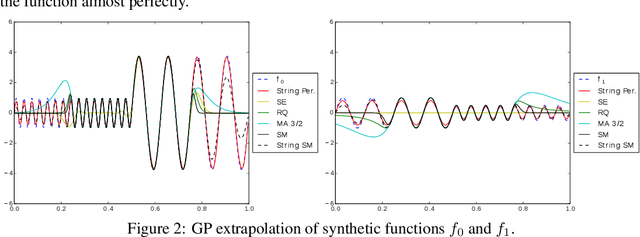
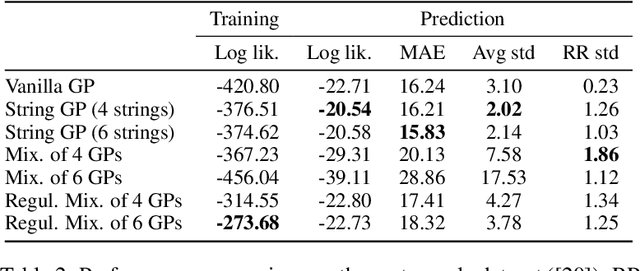
We introduce a new class of nonstationary kernels, which we derive as covariance functions of a novel family of stochastic processes we refer to as string Gaussian processes (string GPs). We construct string GPs to allow for multiple types of local patterns in the data, while ensuring a mild global regularity condition. In this paper, we illustrate the efficacy of the approach using synthetic data and demonstrate that the model outperforms competing approaches on well studied, real-life datasets that exhibit nonstationary features.
Detecting bird sound in unknown acoustic background using crowdsourced training data
May 24, 2015
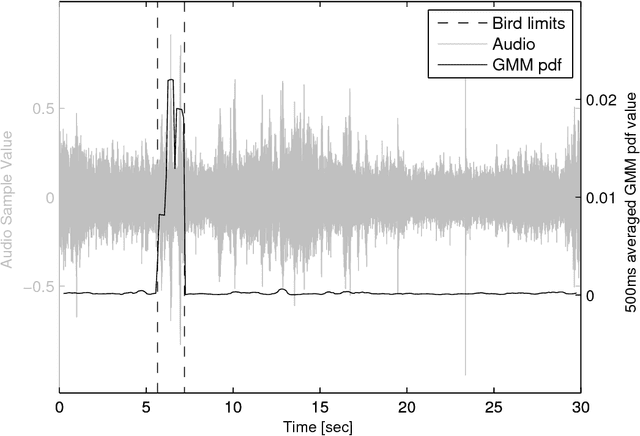
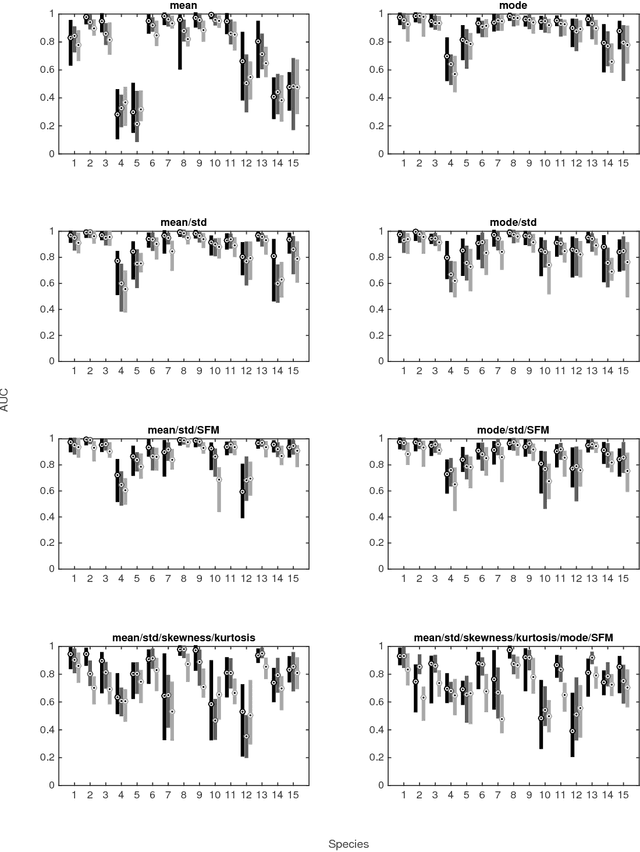
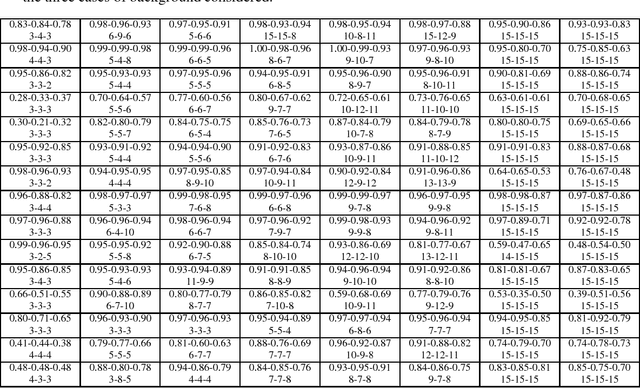
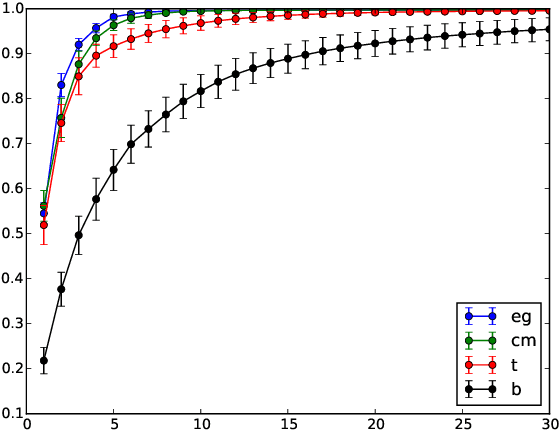
Biodiversity monitoring using audio recordings is achievable at a truly global scale via large-scale deployment of inexpensive, unattended recording stations or by large-scale crowdsourcing using recording and species recognition on mobile devices. The ability, however, to reliably identify vocalising animal species is limited by the fact that acoustic signatures of interest in such recordings are typically embedded in a diverse and complex acoustic background. To avoid the problems associated with modelling such backgrounds, we build generative models of bird sounds and use the concept of novelty detection to screen recordings to detect sections of data which are likely bird vocalisations. We present detection results against various acoustic environments and different signal-to-noise ratios. We discuss the issues related to selecting the cost function and setting detection thresholds in such algorithms. Our methods are designed to be scalable and automatically applicable to arbitrary selections of species depending on the specific geographic region and time period of deployment.
Scalable Nonparametric Bayesian Inference on Point Processes with Gaussian Processes
May 09, 2015
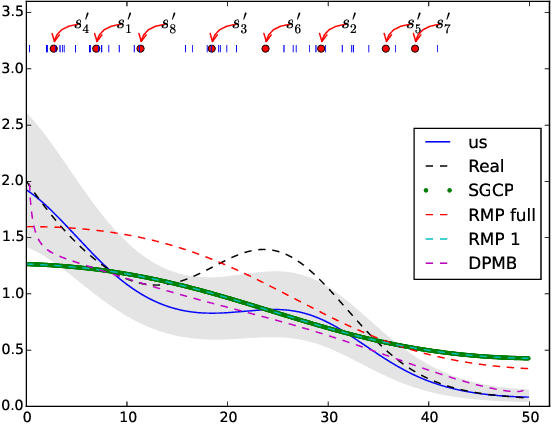
In this paper we propose the first non-parametric Bayesian model using Gaussian Processes to make inference on Poisson Point Processes without resorting to gridding the domain or to introducing latent thinning points. Unlike competing models that scale cubically and have a squared memory requirement in the number of data points, our model has a linear complexity and memory requirement. We propose an MCMC sampler and show that our model is faster, more accurate and generates less correlated samples than competing models on both synthetic and real-life data. Finally, we show that our model easily handles data sizes not considered thus far by alternate approaches.
* To appear at the International Conference on Machine Learning (ICML), 2015
Efficient State-Space Inference of Periodic Latent Force Models
May 29, 2014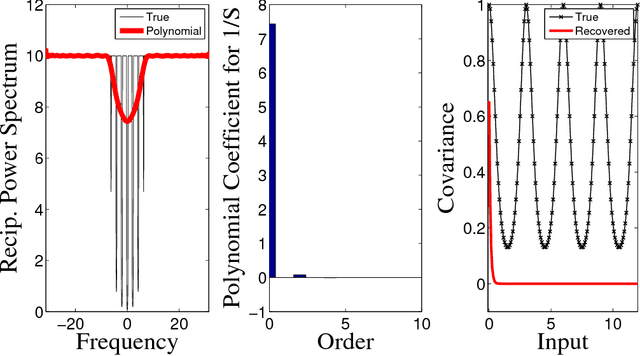


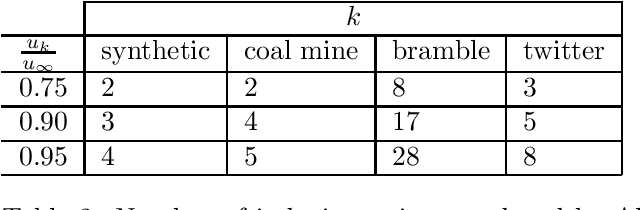
Latent force models (LFM) are principled approaches to incorporating solutions to differential equations within non-parametric inference methods. Unfortunately, the development and application of LFMs can be inhibited by their computational cost, especially when closed-form solutions for the LFM are unavailable, as is the case in many real world problems where these latent forces exhibit periodic behaviour. Given this, we develop a new sparse representation of LFMs which considerably improves their computational efficiency, as well as broadening their applicability, in a principled way, to domains with periodic or near periodic latent forces. Our approach uses a linear basis model to approximate one generative model for each periodic force. We assume that the latent forces are generated from Gaussian process priors and develop a linear basis model which fully expresses these priors. We apply our approach to model the thermal dynamics of domestic buildings and show that it is effective at predicting day-ahead temperatures within the homes. We also apply our approach within queueing theory in which quasi-periodic arrival rates are modelled as latent forces. In both cases, we demonstrate that our approach can be implemented efficiently using state-space methods which encode the linear dynamic systems via LFMs. Further, we show that state estimates obtained using periodic latent force models can reduce the root mean squared error to 17% of that from non-periodic models and 27% of the nearest rival approach which is the resonator model.
Conservative collision prediction and avoidance for stochastic trajectories in continuous time and space
May 12, 2014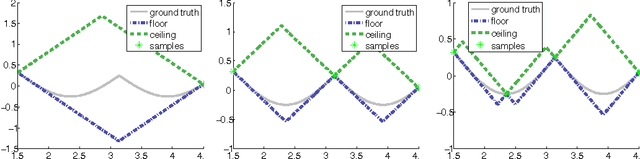

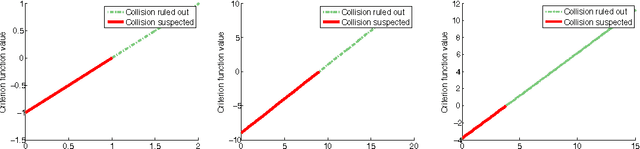
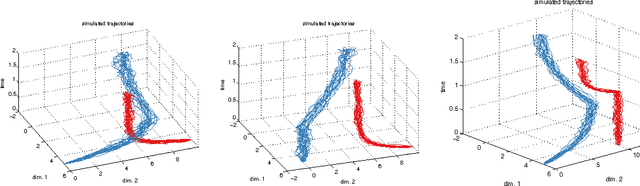
Existing work in multi-agent collision prediction and avoidance typically assumes discrete-time trajectories with Gaussian uncertainty or that are completely deterministic. We propose an approach that allows detection of collisions even between continuous, stochastic trajectories with the only restriction that means and variances can be computed. To this end, we employ probabilistic bounds to derive criterion functions whose negative sign provably is indicative of probable collisions. For criterion functions that are Lipschitz, an algorithm is provided to rapidly find negative values or prove their absence. We propose an iterative policy-search approach that avoids prior discretisations and yields collision-free trajectories with adjustably high certainty. We test our method with both fixed-priority and auction-based protocols for coordinating the iterative planning process. Results are provided in collision-avoidance simulations of feedback controlled plants.
Communication Communities in MOOCs
Apr 16, 2014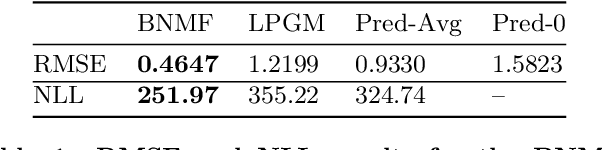
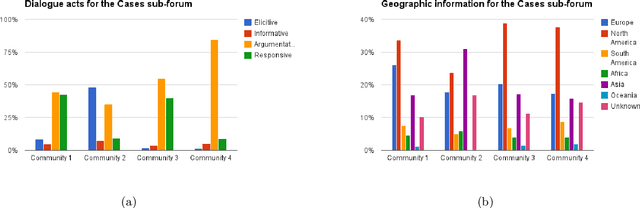
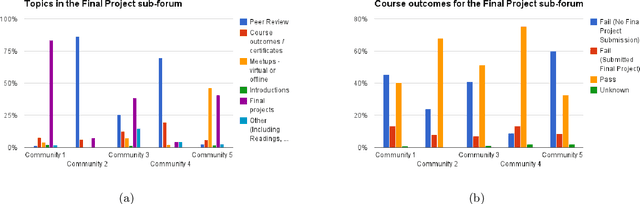
Massive Open Online Courses (MOOCs) bring together thousands of people from different geographies and demographic backgrounds -- but to date, little is known about how they learn or communicate. We introduce a new content-analysed MOOC dataset and use Bayesian Non-negative Matrix Factorization (BNMF) to extract communities of learners based on the nature of their online forum posts. We see that BNMF yields a superior probabilistic generative model for online discussions when compared to other models, and that the communities it learns are differentiated by their composite students' demographic and course performance indicators. These findings suggest that computationally efficient probabilistic generative modelling of MOOCs can reveal important insights for educational researchers and practitioners and help to develop more intelligent and responsive online learning environments.
Efficient Bayesian Community Detection using Non-negative Matrix Factorisation
Sep 25, 2010



Identifying overlapping communities in networks is a challenging task. In this work we present a novel approach to community detection that utilises the Bayesian non-negative matrix factorisation (NMF) model to produce a probabilistic output for node memberships. The scheme has the advantage of computational efficiency, soft community membership and an intuitive foundation. We present the performance of the method against a variety of benchmark problems and compare and contrast it to several other algorithms for community detection. Our approach performs favourably compared to other methods at a fraction of the computational costs.