 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVBALD - Variational Bayesian Approximation of Log Determinants
Feb 21, 2018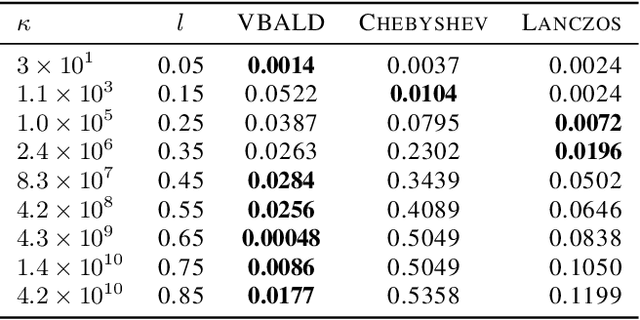
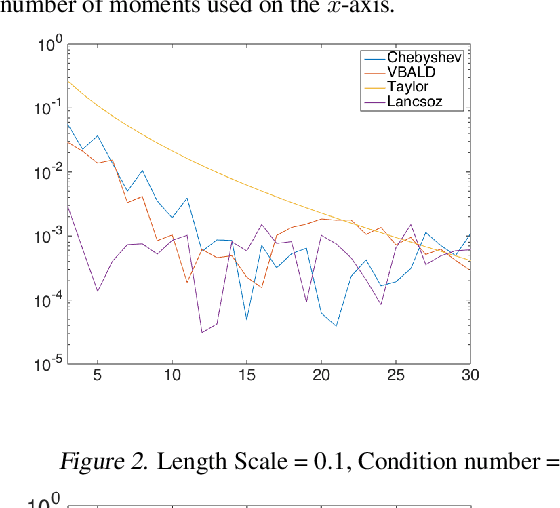
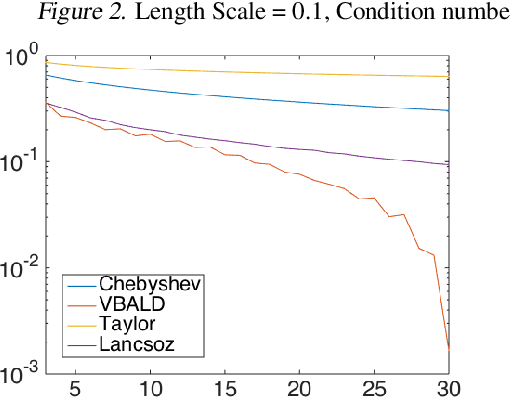

Evaluating the log determinant of a positive definite matrix is ubiquitous in machine learning. Applications thereof range from Gaussian processes, minimum-volume ellipsoids, metric learning, kernel learning, Bayesian neural networks, Determinental Point Processes, Markov random fields to partition functions of discrete graphical models. In order to avoid the canonical, yet prohibitive, Cholesky $\mathcal{O}(n^{3})$ computational cost, we propose a novel approach, with complexity $\mathcal{O}(n^{2})$, based on a constrained variational Bayes algorithm. We compare our method to Taylor, Chebyshev and Lanczos approaches and show state of the art performance on both synthetic and real-world datasets.
Safe Policy Search with Gaussian Process Models
Dec 15, 2017
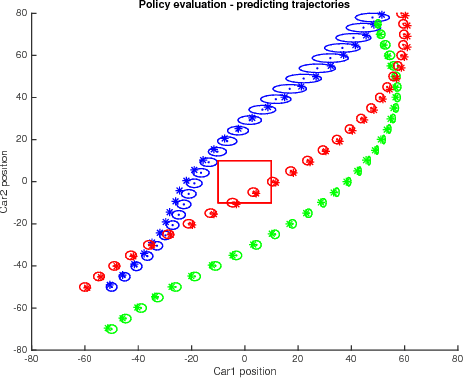
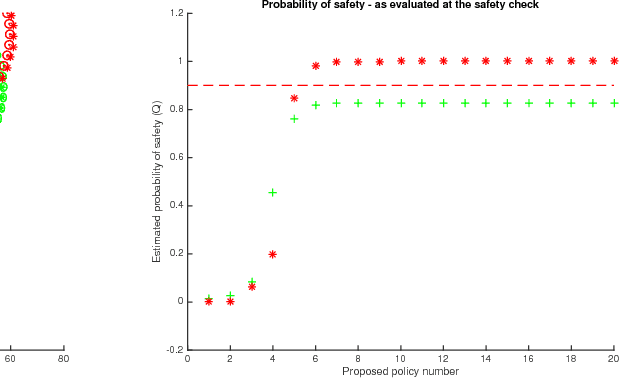
We propose a method to optimise the parameters of a policy which will be used to safely perform a given task in a data-efficient manner. We train a Gaussian process model to capture the system dynamics, based on the PILCO framework. Our model has useful analytic properties, which allow closed form computation of error gradients and estimating the probability of violating given state space constraints. During training, as well as operation, only policies that are deemed safe are implemented on the real system, minimising the risk of failure.
Cost-sensitive detection with variational autoencoders for environmental acoustic sensing
Dec 07, 2017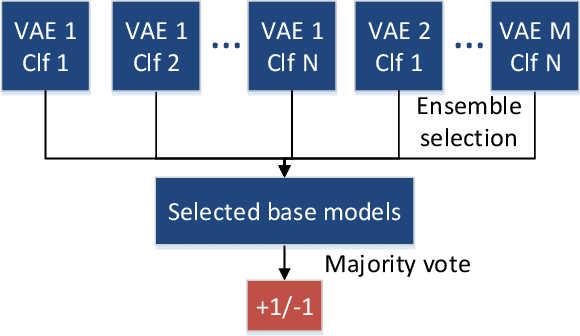

Environmental acoustic sensing involves the retrieval and processing of audio signals to better understand our surroundings. While large-scale acoustic data make manual analysis infeasible, they provide a suitable playground for machine learning approaches. Most existing machine learning techniques developed for environmental acoustic sensing do not provide flexible control of the trade-off between the false positive rate and the false negative rate. This paper presents a cost-sensitive classification paradigm, in which the hyper-parameters of classifiers and the structure of variational autoencoders are selected in a principled Neyman-Pearson framework. We examine the performance of the proposed approach using a dataset from the HumBug project which aims to detect the presence of mosquitoes using sound collected by simple embedded devices.
Mosquito detection with low-cost smartphones: data acquisition for malaria research
Dec 06, 2017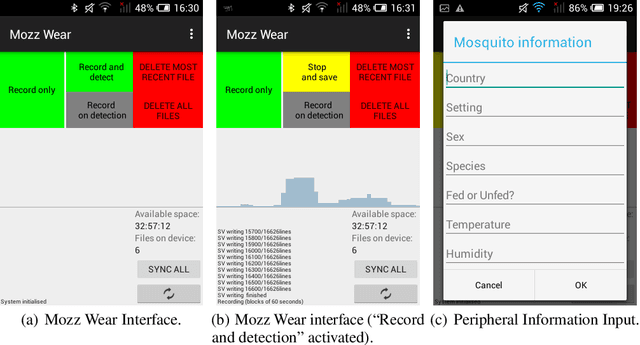
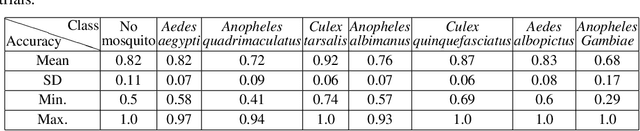
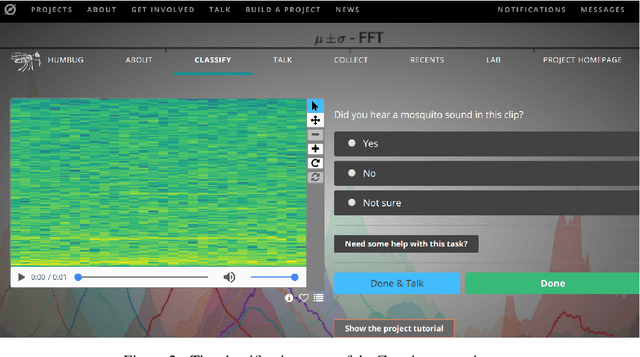
Mosquitoes are a major vector for malaria, causing hundreds of thousands of deaths in the developing world each year. Not only is the prevention of mosquito bites of paramount importance to the reduction of malaria transmission cases, but understanding in more forensic detail the interplay between malaria, mosquito vectors, vegetation, standing water and human populations is crucial to the deployment of more effective interventions. Typically the presence and detection of malaria-vectoring mosquitoes is only quantified by hand-operated insect traps or signified by the diagnosis of malaria. If we are to gather timely, large-scale data to improve this situation, we need to automate the process of mosquito detection and classification as much as possible. In this paper, we present a candidate mobile sensing system that acts as both a portable early warning device and an automatic acoustic data acquisition pipeline to help fuel scientific inquiry and policy. The machine learning algorithm that powers the mobile system achieves excellent off-line multi-species detection performance while remaining computationally efficient. Further, we have conducted preliminary live mosquito detection tests using low-cost mobile phones and achieved promising results. The deployment of this system for field usage in Southeast Asia and Africa is planned in the near future. In order to accelerate processing of field recordings and labelling of collected data, we employ a citizen science platform in conjunction with automated methods, the former implemented using the Zooniverse platform, allowing crowdsourcing on a grand scale.
Novel Exploration Techniques (NETs) for Malaria Policy Interventions
Dec 01, 2017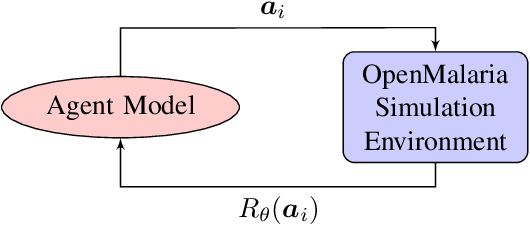
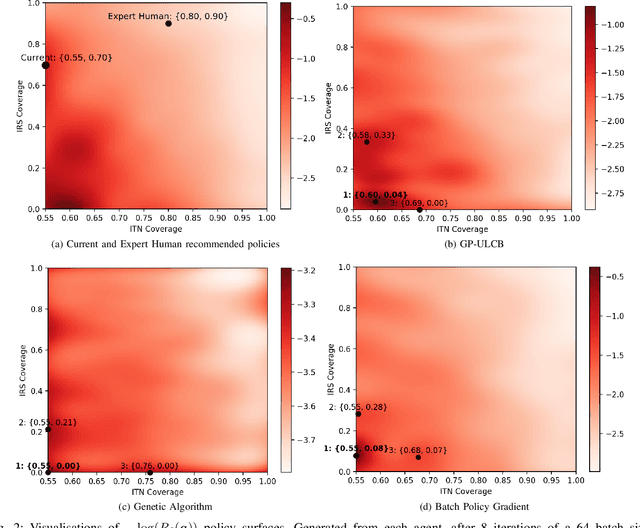

The task of decision-making under uncertainty is daunting, especially for problems which have significant complexity. Healthcare policy makers across the globe are facing problems under challenging constraints, with limited tools to help them make data driven decisions. In this work we frame the process of finding an optimal malaria policy as a stochastic multi-armed bandit problem, and implement three agent based strategies to explore the policy space. We apply a Gaussian Process regression to the findings of each agent, both for comparison and to account for stochastic results from simulating the spread of malaria in a fixed population. The generated policy spaces are compared with published results to give a direct reference with human expert decisions for the same simulated population. Our novel approach provides a powerful resource for policy makers, and a platform which can be readily extended to capture future more nuanced policy spaces.
Riemannian tangent space mapping and elastic net regularization for cost-effective EEG markers of brain atrophy in Alzheimer's disease
Nov 22, 2017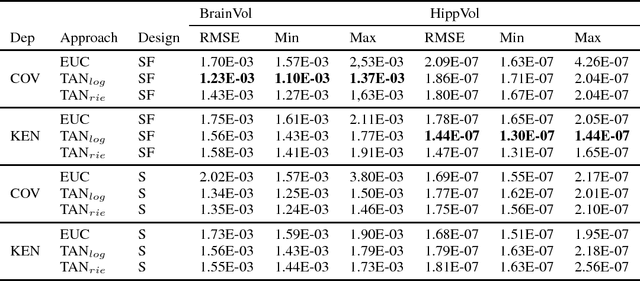
The diagnosis of Alzheimer's disease (AD) in routine clinical practice is most commonly based on subjective clinical interpretations. Quantitative electroencephalography (QEEG) measures have been shown to reflect neurodegenerative processes in AD and might qualify as affordable and thereby widely available markers to facilitate the objectivization of AD assessment. Here, we present a novel framework combining Riemannian tangent space mapping and elastic net regression for the development of brain atrophy markers. While most AD QEEG studies are based on small sample sizes and psychological test scores as outcome measures, here we train and test our models using data of one of the largest prospective EEG AD trials ever conducted, including MRI biomarkers of brain atrophy.
Entropic Determinants
Sep 08, 2017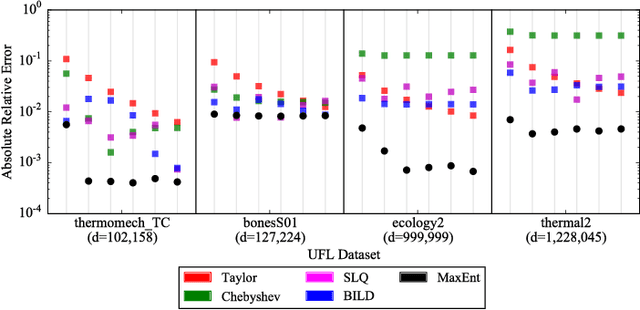
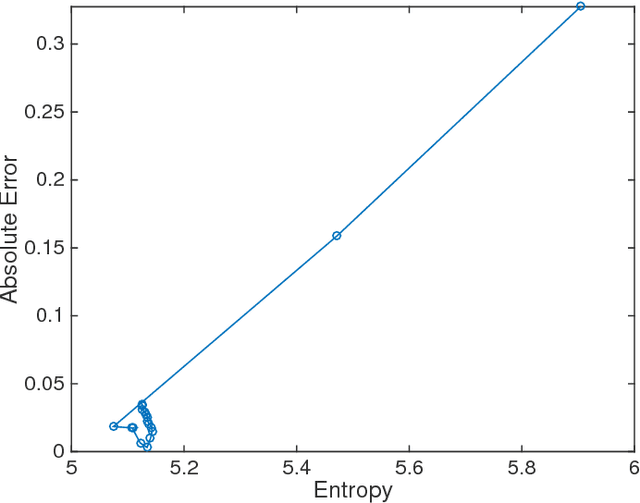
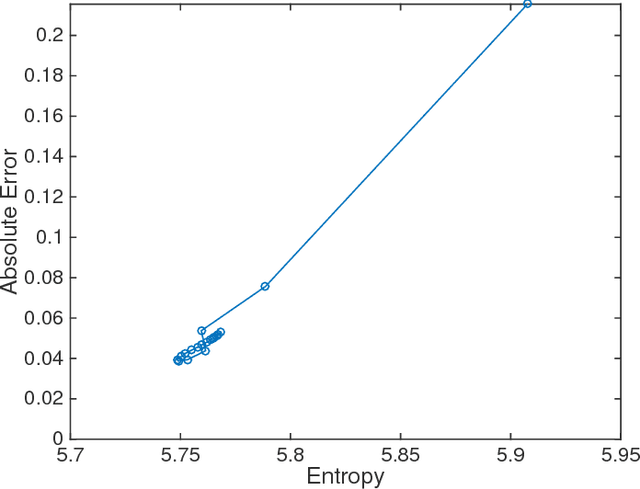
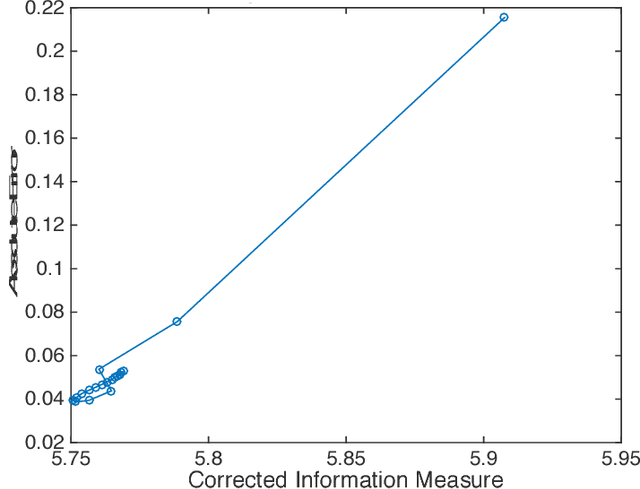
The ability of many powerful machine learning algorithms to deal with large data sets without compromise is often hampered by computationally expensive linear algebra tasks, of which calculating the log determinant is a canonical example. In this paper we demonstrate the optimality of Maximum Entropy methods in approximating such calculations. We prove the equivalence between mean value constraints and sample expectations in the big data limit, that Covariance matrix eigenvalue distributions can be completely defined by moment information and that the reduction of the self entropy of a maximum entropy proposal distribution, achieved by adding more moments reduces the KL divergence between the proposal and true eigenvalue distribution. We empirically verify our results on a variety of SparseSuite matrices and establish best practices.
Mosquito Detection with Neural Networks: The Buzz of Deep Learning
May 15, 2017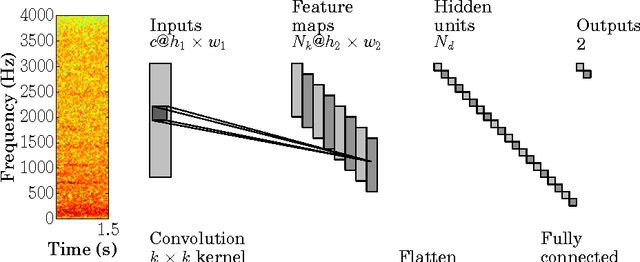

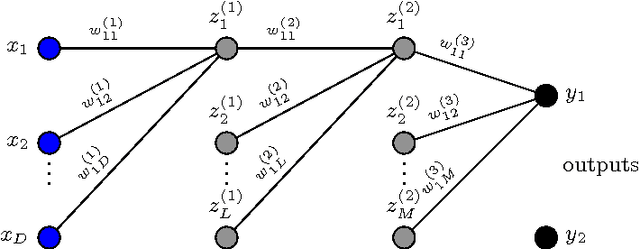
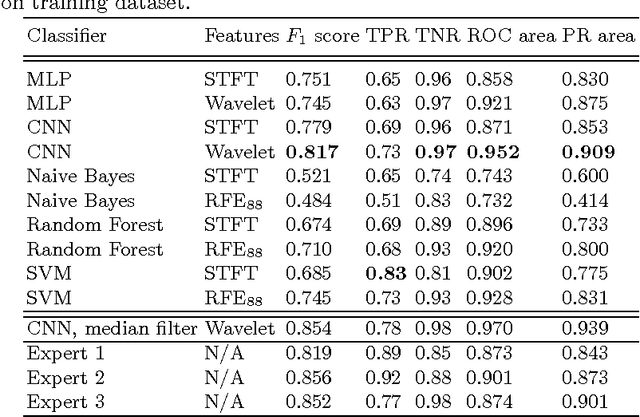
Many real-world time-series analysis problems are characterised by scarce data. Solutions typically rely on hand-crafted features extracted from the time or frequency domain allied with classification or regression engines which condition on this (often low-dimensional) feature vector. The huge advances enjoyed by many application domains in recent years have been fuelled by the use of deep learning architectures trained on large data sets. This paper presents an application of deep learning for acoustic event detection in a challenging, data-scarce, real-world problem. Our candidate challenge is to accurately detect the presence of a mosquito from its acoustic signature. We develop convolutional neural networks (CNNs) operating on wavelet transformations of audio recordings. Furthermore, we interrogate the network's predictive power by visualising statistics of network-excitatory samples. These visualisations offer a deep insight into the relative informativeness of components in the detection problem. We include comparisons with conventional classifiers, conditioned on both hand-tuned and generic features, to stress the strength of automatic deep feature learning. Detection is achieved with performance metrics significantly surpassing those of existing algorithmic methods, as well as marginally exceeding those attained by individual human experts.
Entropic Trace Estimates for Log Determinants
Apr 24, 2017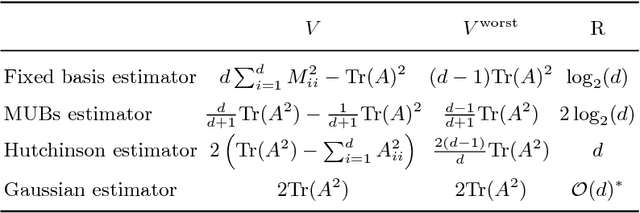
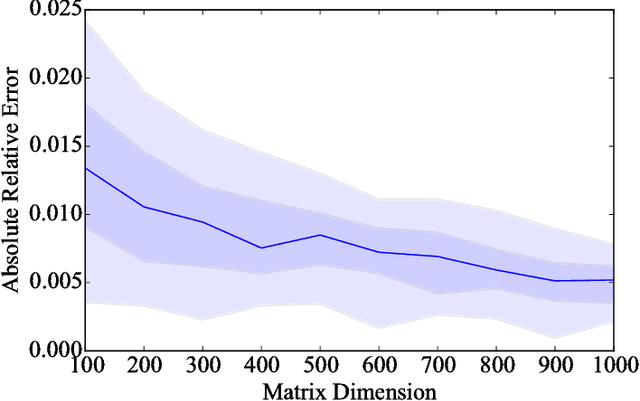
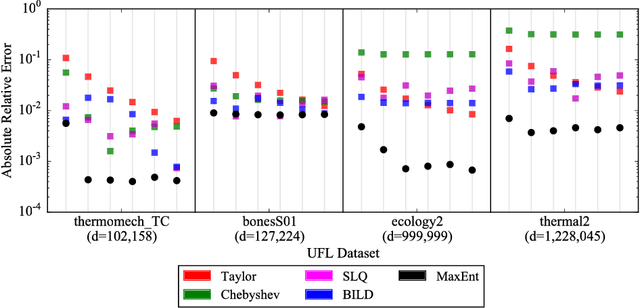
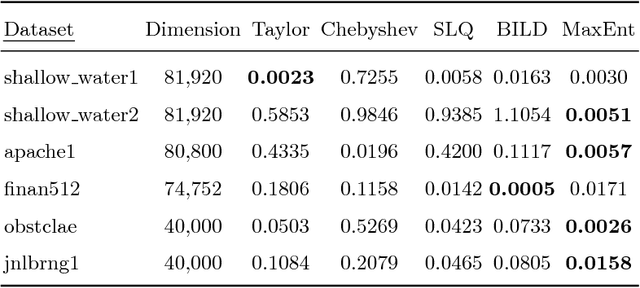
The scalable calculation of matrix determinants has been a bottleneck to the widespread application of many machine learning methods such as determinantal point processes, Gaussian processes, generalised Markov random fields, graph models and many others. In this work, we estimate log determinants under the framework of maximum entropy, given information in the form of moment constraints from stochastic trace estimation. The estimates demonstrate a significant improvement on state-of-the-art alternative methods, as shown on a wide variety of UFL sparse matrices. By taking the example of a general Markov random field, we also demonstrate how this approach can significantly accelerate inference in large-scale learning methods involving the log determinant.
Bayesian Inference of Log Determinants
Apr 05, 2017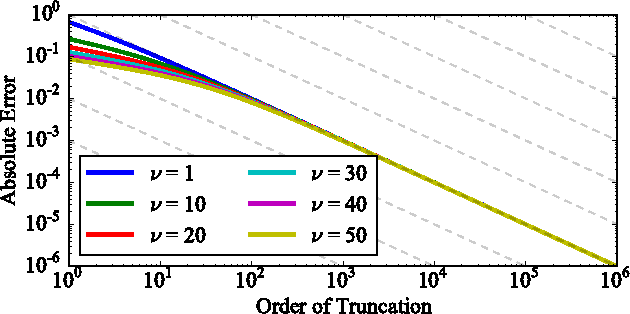
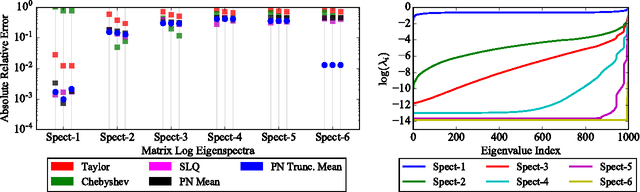
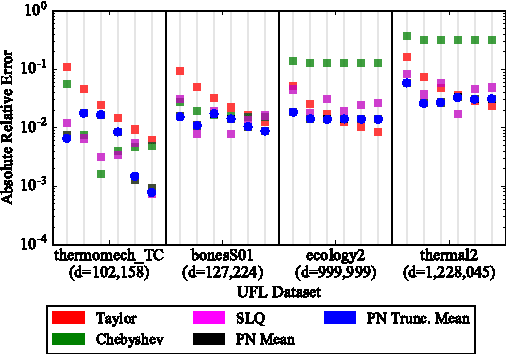
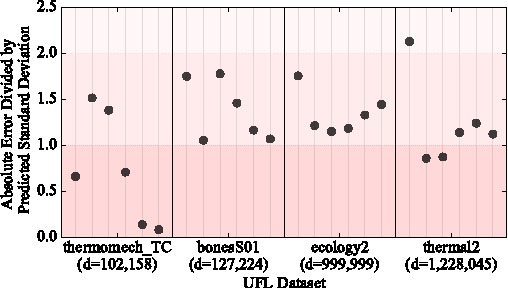
The log-determinant of a kernel matrix appears in a variety of machine learning problems, ranging from determinantal point processes and generalized Markov random fields, through to the training of Gaussian processes. Exact calculation of this term is often intractable when the size of the kernel matrix exceeds a few thousand. In the spirit of probabilistic numerics, we reinterpret the problem of computing the log-determinant as a Bayesian inference problem. In particular, we combine prior knowledge in the form of bounds from matrix theory and evidence derived from stochastic trace estimation to obtain probabilistic estimates for the log-determinant and its associated uncertainty within a given computational budget. Beyond its novelty and theoretic appeal, the performance of our proposal is competitive with state-of-the-art approaches to approximating the log-determinant, while also quantifying the uncertainty due to budget-constrained evidence.