 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Momentum: Jointly Learning Time-Series and Cross-Sectional Strategies
Feb 20, 2023



We introduce Spatio-Temporal Momentum strategies, a class of models that unify both time-series and cross-sectional momentum strategies by trading assets based on their cross-sectional momentum features over time. While both time-series and cross-sectional momentum strategies are designed to systematically capture momentum risk premia, these strategies are regarded as distinct implementations and do not consider the concurrent relationship and predictability between temporal and cross-sectional momentum features of different assets. We model spatio-temporal momentum with neural networks of varying complexities and demonstrate that a simple neural network with only a single fully connected layer learns to simultaneously generate trading signals for all assets in a portfolio by incorporating both their time-series and cross-sectional momentum features. Backtesting on portfolios of 46 actively-traded US equities and 12 equity index futures contracts, we demonstrate that the model is able to retain its performance over benchmarks in the presence of high transaction costs of up to 5-10 basis points. In particular, we find that the model when coupled with least absolute shrinkage and turnover regularization results in the best performance over various transaction cost scenarios.
A large-scale and PCR-referenced vocal audio dataset for COVID-19
Dec 15, 2022The UK COVID-19 Vocal Audio Dataset is designed for the training and evaluation of machine learning models that classify SARS-CoV-2 infection status or associated respiratory symptoms using vocal audio. The UK Health Security Agency recruited voluntary participants through the national Test and Trace programme and the REACT-1 survey in England from March 2021 to March 2022, during dominant transmission of the Alpha and Delta SARS-CoV-2 variants and some Omicron variant sublineages. Audio recordings of volitional coughs, exhalations, and speech were collected in the 'Speak up to help beat coronavirus' digital survey alongside demographic, self-reported symptom and respiratory condition data, and linked to SARS-CoV-2 test results. The UK COVID-19 Vocal Audio Dataset represents the largest collection of SARS-CoV-2 PCR-referenced audio recordings to date. PCR results were linked to 70,794 of 72,999 participants and 24,155 of 25,776 positive cases. Respiratory symptoms were reported by 45.62% of participants. This dataset has additional potential uses for bioacoustics research, with 11.30% participants reporting asthma, and 27.20% with linked influenza PCR test results.
Audio-based AI classifiers show no evidence of improved COVID-19 screening over simple symptoms checkers
Dec 15, 2022



Recent work has reported that AI classifiers trained on audio recordings can accurately predict severe acute respiratory syndrome coronavirus 2 (SARSCoV2) infection status. Here, we undertake a large scale study of audio-based deep learning classifiers, as part of the UK governments pandemic response. We collect and analyse a dataset of audio recordings from 67,842 individuals with linked metadata, including reverse transcription polymerase chain reaction (PCR) test outcomes, of whom 23,514 tested positive for SARS CoV 2. Subjects were recruited via the UK governments National Health Service Test-and-Trace programme and the REal-time Assessment of Community Transmission (REACT) randomised surveillance survey. In an unadjusted analysis of our dataset AI classifiers predict SARS-CoV-2 infection status with high accuracy (Receiver Operating Characteristic Area Under the Curve (ROCAUC) 0.846 [0.838, 0.854]) consistent with the findings of previous studies. However, after matching on measured confounders, such as age, gender, and self reported symptoms, our classifiers performance is much weaker (ROC-AUC 0.619 [0.594, 0.644]). Upon quantifying the utility of audio based classifiers in practical settings, we find them to be outperformed by simple predictive scores based on user reported symptoms.
Transfer Ranking in Finance: Applications to Cross-Sectional Momentum with Data Scarcity
Aug 24, 2022
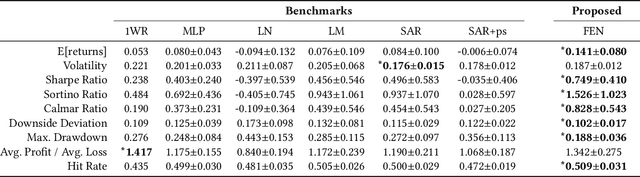
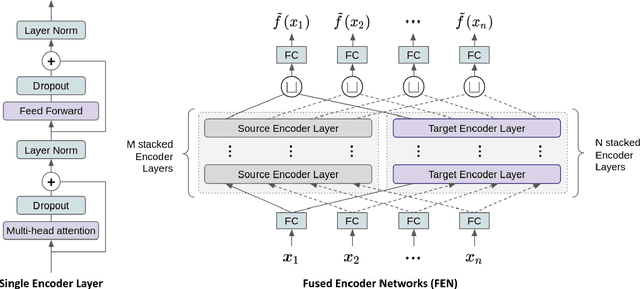
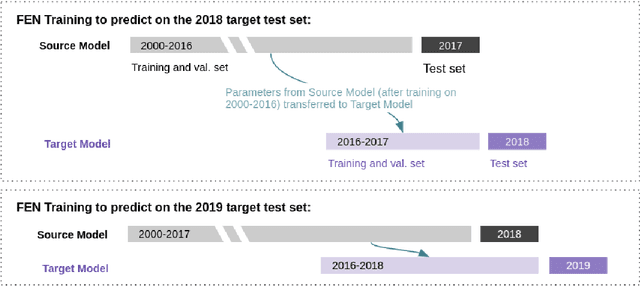
Cross-sectional strategies are a classical and popular trading style, with recent high performing variants incorporating sophisticated neural architectures. While these strategies have been applied successfully to data-rich settings involving mature assets with long histories, deploying them on instruments with limited samples generally produce over-fitted models with degraded performance. In this paper, we introduce Fused Encoder Networks -- a novel and hybrid parameter-sharing transfer ranking model. The model fuses information extracted using an encoder-attention module operated on a source dataset with a similar but separate module focused on a smaller target dataset of interest. This mitigates the issue of models with poor generalisability that are a consequence of training on scarce target data. Additionally, the self-attention mechanism enables interactions among instruments to be accounted for, not just at the loss level during model training, but also at inference time. Focusing on momentum applied to the top ten cryptocurrencies by market capitalisation as a demonstrative use-case, the Fused Encoder Networks outperforms the reference benchmarks on most performance measures, delivering a three-fold boost in the Sharpe ratio over classical momentum as well as an improvement of approximately 50% against the best benchmark model without transaction costs. It continues outperforming baselines even after accounting for the high transaction costs associated with trading cryptocurrencies.
The ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022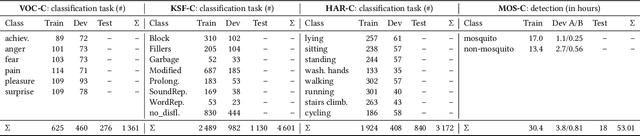

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.
Trading with the Momentum Transformer: An Intelligent and Interpretable Architecture
Dec 16, 2021Deep learning architectures, specifically Deep Momentum Networks (DMNs) [1904.04912], have been found to be an effective approach to momentum and mean-reversion trading. However, some of the key challenges in recent years involve learning long-term dependencies, degradation of performance when considering returns net of transaction costs and adapting to new market regimes, notably during the SARS-CoV-2 crisis. Attention mechanisms, or Transformer-based architectures, are a solution to such challenges because they allow the network to focus on significant time steps in the past and longer-term patterns. We introduce the Momentum Transformer, an attention-based architecture which outperforms the benchmarks, and is inherently interpretable, providing us with greater insights into our deep learning trading strategy. Our model is an extension to the LSTM-based DMN, which directly outputs position sizing by optimising the network on a risk-adjusted performance metric, such as Sharpe ratio. We find an attention-LSTM hybrid Decoder-Only Temporal Fusion Transformer (TFT) style architecture is the best performing model. In terms of interpretability, we observe remarkable structure in the attention patterns, with significant peaks of importance at momentum turning points. The time series is thus segmented into regimes and the model tends to focus on previous time-steps in alike regimes. We find changepoint detection (CPD) [2105.13727], another technique for responding to regime change, can complement multi-headed attention, especially when we run CPD at multiple timescales. Through the addition of an interpretable variable selection network, we observe how CPD helps our model to move away from trading predominantly on daily returns data. We note that the model can intelligently switch between, and blend, classical strategies - basing its decision on patterns in the data.
A Bayesian take on option pricing with Gaussian processes
Dec 07, 2021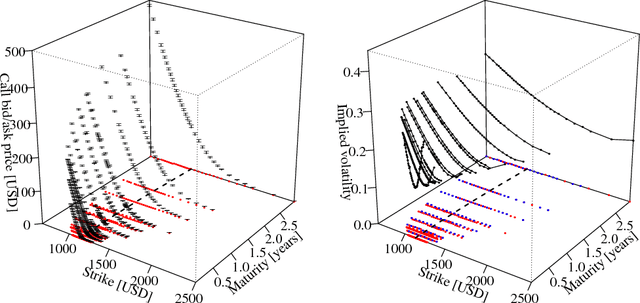
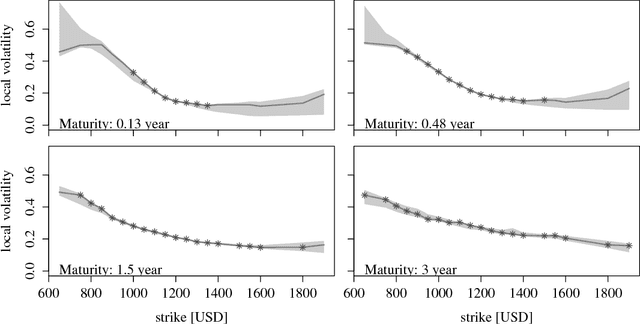
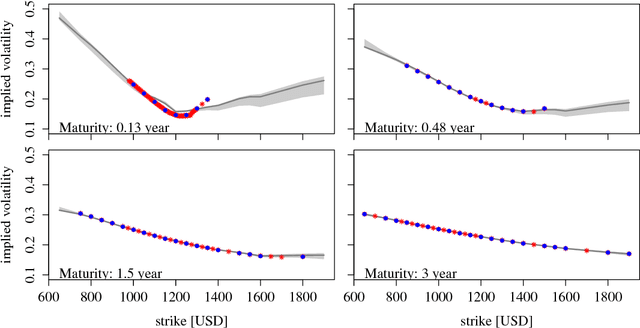
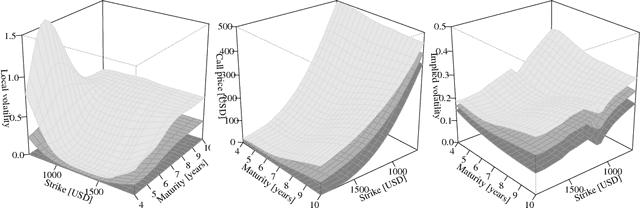
Local volatility is a versatile option pricing model due to its state dependent diffusion coefficient. Calibration is, however, non-trivial as it involves both proposing a hypothesis model of the latent function and a method for fitting it to data. In this paper we present novel Bayesian inference with Gaussian process priors. We obtain a rich representation of the local volatility function with a probabilistic notion of uncertainty attached to the calibrate. We propose an inference algorithm and apply our approach to S&P 500 market data.
One-Shot Transfer Learning of Physics-Informed Neural Networks
Oct 21, 2021
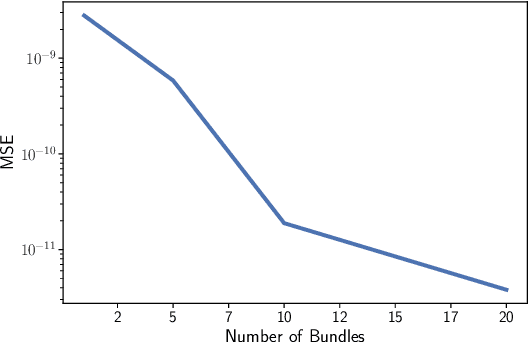
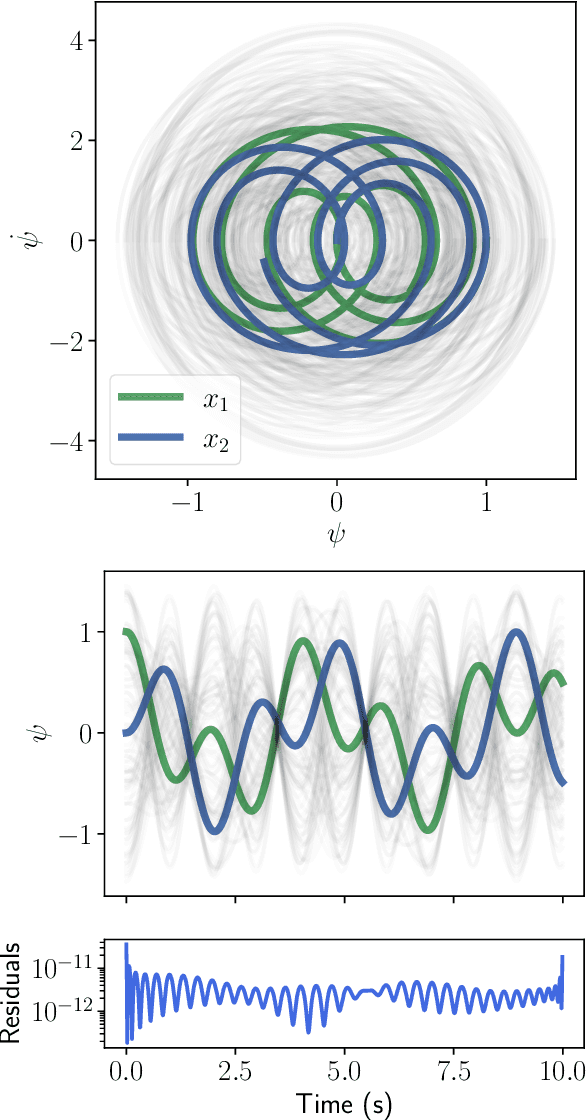
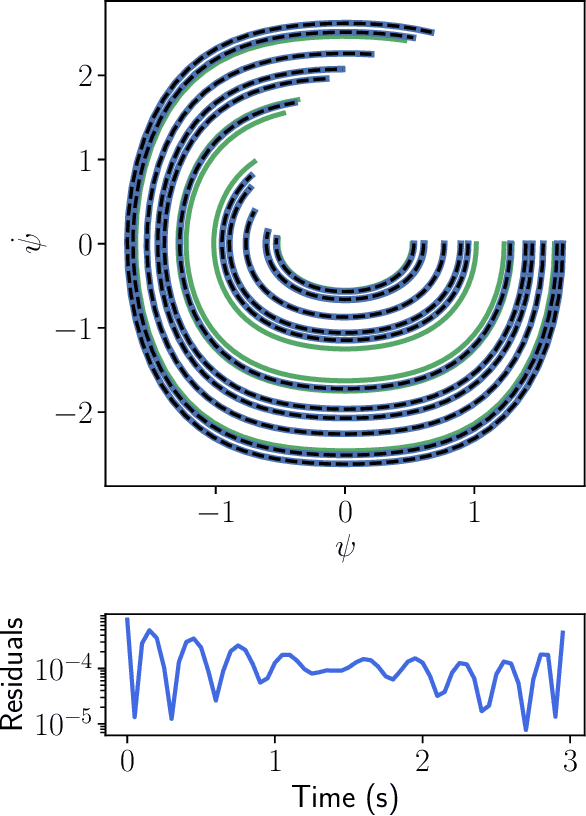
Solving differential equations efficiently and accurately sits at the heart of progress in many areas of scientific research, from classical dynamical systems to quantum mechanics. There is a surge of interest in using Physics-Informed Neural Networks (PINNs) to tackle such problems as they provide numerous benefits over traditional numerical approaches. Despite their potential benefits for solving differential equations, transfer learning has been under explored. In this study, we present a general framework for transfer learning PINNs that results in one-shot inference for linear systems of both ordinary and partial differential equations. This means that highly accurate solutions to many unknown differential equations can be obtained instantaneously without retraining an entire network. We demonstrate the efficacy of the proposed deep learning approach by solving several real-world problems, such as first- and second-order linear ordinary equations, the Poisson equation, and the time-dependent Schrodinger complex-value partial differential equation.
Robust and Scalable SDE Learning: A Functional Perspective
Oct 11, 2021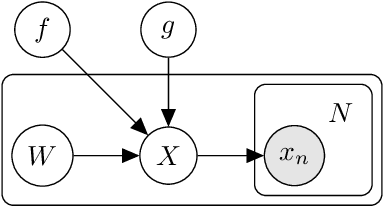
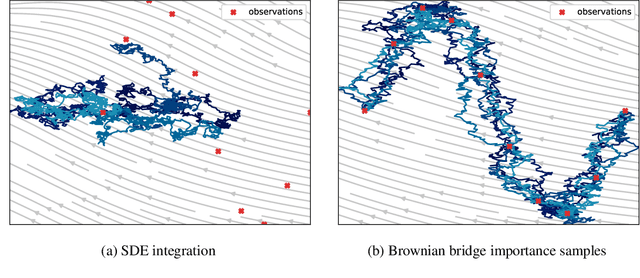
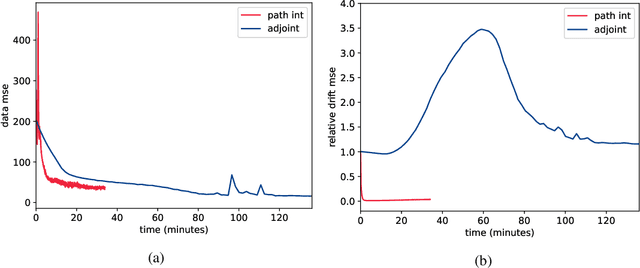
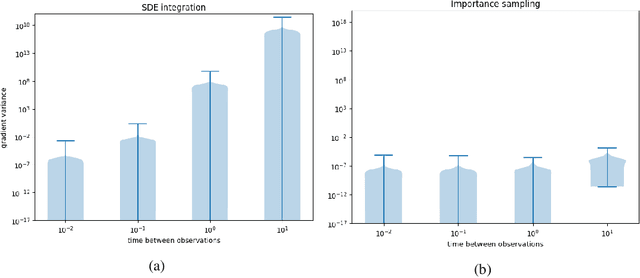
Stochastic differential equations provide a rich class of flexible generative models, capable of describing a wide range of spatio-temporal processes. A host of recent work looks to learn data-representing SDEs, using neural networks and other flexible function approximators. Despite these advances, learning remains computationally expensive due to the sequential nature of SDE integrators. In this work, we propose an importance-sampling estimator for probabilities of observations of SDEs for the purposes of learning. Crucially, the approach we suggest does not rely on such integrators. The proposed method produces lower-variance gradient estimates compared to algorithms based on SDE integrators and has the added advantage of being embarrassingly parallelizable. This facilitates the effective use of large-scale parallel hardware for massive decreases in computation time.
Port-Hamiltonian Neural Networks for Learning Explicit Time-Dependent Dynamical Systems
Jul 16, 2021Accurately learning the temporal behavior of dynamical systems requires models with well-chosen learning biases. Recent innovations embed the Hamiltonian and Lagrangian formalisms into neural networks and demonstrate a significant improvement over other approaches in predicting trajectories of physical systems. These methods generally tackle autonomous systems that depend implicitly on time or systems for which a control signal is known apriori. Despite this success, many real world dynamical systems are non-autonomous, driven by time-dependent forces and experience energy dissipation. In this study, we address the challenge of learning from such non-autonomous systems by embedding the port-Hamiltonian formalism into neural networks, a versatile framework that can capture energy dissipation and time-dependent control forces. We show that the proposed \emph{port-Hamiltonian neural network} can efficiently learn the dynamics of nonlinear physical systems of practical interest and accurately recover the underlying stationary Hamiltonian, time-dependent force, and dissipative coefficient. A promising outcome of our network is its ability to learn and predict chaotic systems such as the Duffing equation, for which the trajectories are typically hard to learn.