 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-fly Strategy Adaptation for ad-hoc Agent Coordination
Mar 08, 2022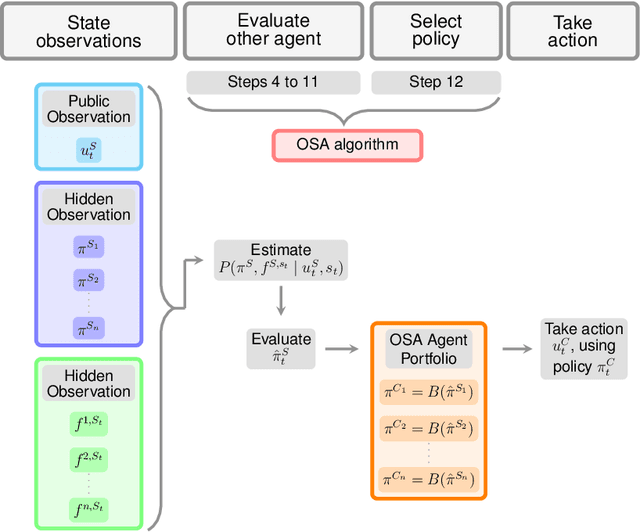

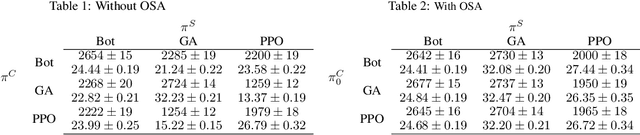

Training agents in cooperative settings offers the promise of AI agents able to interact effectively with humans (and other agents) in the real world. Multi-agent reinforcement learning (MARL) has the potential to achieve this goal, demonstrating success in a series of challenging problems. However, whilst these advances are significant, the vast majority of focus has been on the self-play paradigm. This often results in a coordination problem, caused by agents learning to make use of arbitrary conventions when playing with themselves. This means that even the strongest self-play agents may have very low cross-play with other agents, including other initializations of the same algorithm. In this paper we propose to solve this problem by adapting agent strategies on the fly, using a posterior belief over the other agents' strategy. Concretely, we consider the problem of selecting a strategy from a finite set of previously trained agents, to play with an unknown partner. We propose an extension of the classic statistical technique, Gibbs sampling, to update beliefs about other agents and obtain close to optimal ad-hoc performance. Despite its simplicity, our method is able to achieve strong cross-play with unseen partners in the challenging card game of Hanabi, achieving successful ad-hoc coordination without knowledge of the partner's strategy a priori.
HumBugDB: A Large-scale Acoustic Mosquito Dataset
Oct 14, 2021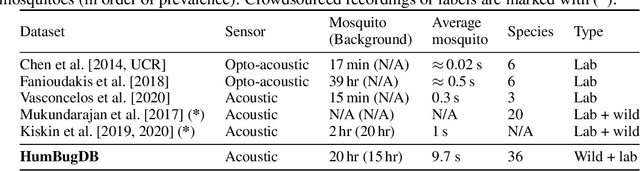
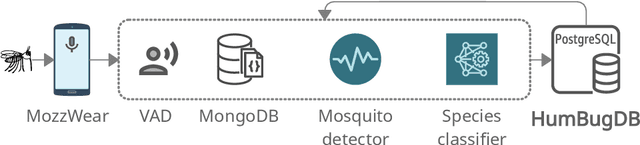
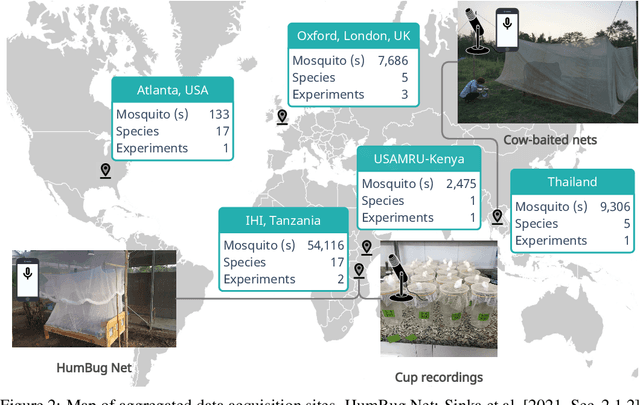
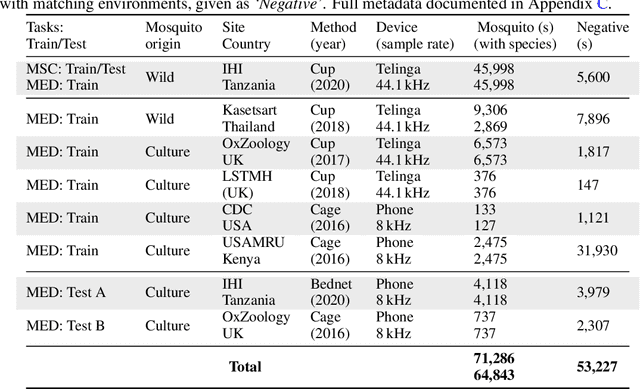
This paper presents the first large-scale multi-species dataset of acoustic recordings of mosquitoes tracked continuously in free flight. We present 20 hours of audio recordings that we have expertly labelled and tagged precisely in time. Significantly, 18 hours of recordings contain annotations from 36 different species. Mosquitoes are well-known carriers of diseases such as malaria, dengue and yellow fever. Collecting this dataset is motivated by the need to assist applications which utilise mosquito acoustics to conduct surveys to help predict outbreaks and inform intervention policy. The task of detecting mosquitoes from the sound of their wingbeats is challenging due to the difficulty in collecting recordings from realistic scenarios. To address this, as part of the HumBug project, we conducted global experiments to record mosquitoes ranging from those bred in culture cages to mosquitoes captured in the wild. Consequently, the audio recordings vary in signal-to-noise ratio and contain a broad range of indoor and outdoor background environments from Tanzania, Thailand, Kenya, the USA and the UK. In this paper we describe in detail how we collected, labelled and curated the data. The data is provided from a PostgreSQL database, which contains important metadata such as the capture method, age, feeding status and gender of the mosquitoes. Additionally, we provide code to extract features and train Bayesian convolutional neural networks for two key tasks: the identification of mosquitoes from their corresponding background environments, and the classification of detected mosquitoes into species. Our extensive dataset is both challenging to machine learning researchers focusing on acoustic identification, and critical to entomologists, geo-spatial modellers and other domain experts to understand mosquito behaviour, model their distribution, and manage the threat they pose to humans.
Revisiting Design Choices in Model-Based Offline Reinforcement Learning
Oct 08, 2021
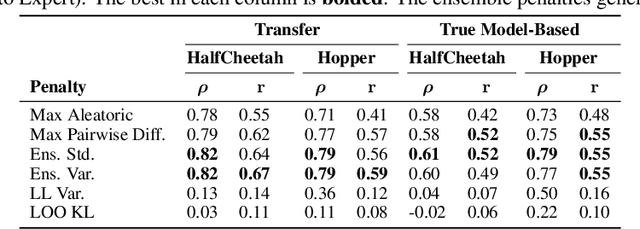
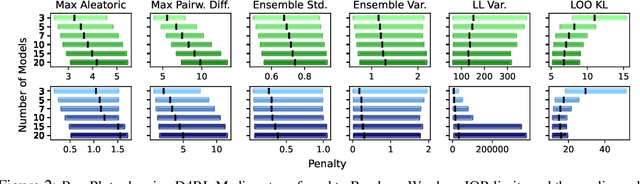
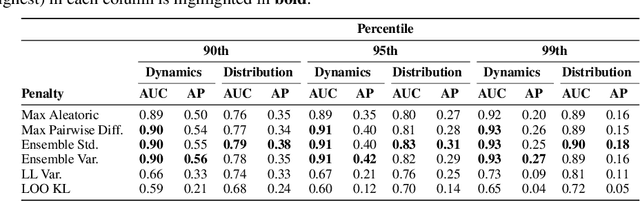
Offline reinforcement learning enables agents to leverage large pre-collected datasets of environment transitions to learn control policies, circumventing the need for potentially expensive or unsafe online data collection. Significant progress has been made recently in offline model-based reinforcement learning, approaches which leverage a learned dynamics model. This typically involves constructing a probabilistic model, and using the model uncertainty to penalize rewards where there is insufficient data, solving for a pessimistic MDP that lower bounds the true MDP. Existing methods, however, exhibit a breakdown between theory and practice, whereby pessimistic return ought to be bounded by the total variation distance of the model from the true dynamics, but is instead implemented through a penalty based on estimated model uncertainty. This has spawned a variety of uncertainty heuristics, with little to no comparison between differing approaches. In this paper, we compare these heuristics, and design novel protocols to investigate their interaction with other hyperparameters, such as the number of models, or imaginary rollout horizon. Using these insights, we show that selecting these key hyperparameters using Bayesian Optimization produces superior configurations that are vastly different to those currently used in existing hand-tuned state-of-the-art methods, and result in drastically stronger performance.
Marginalising over Stationary Kernels with Bayesian Quadrature
Jun 14, 2021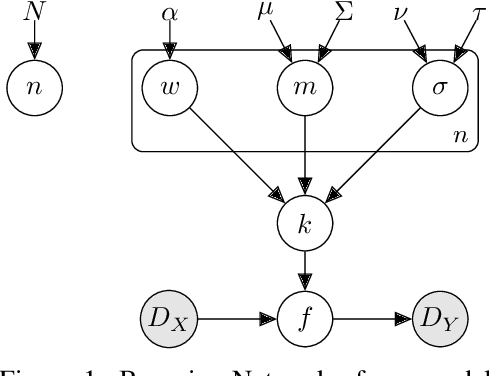

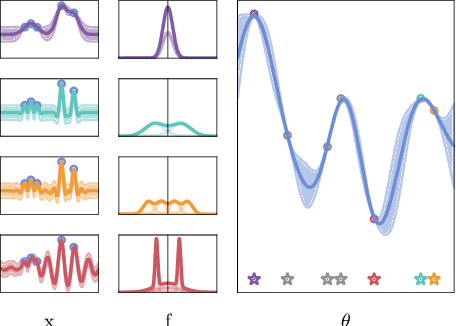

Marginalising over families of Gaussian Process kernels produces flexible model classes with well-calibrated uncertainty estimates. Existing approaches require likelihood evaluations of many kernels, rendering them prohibitively expensive for larger datasets. We propose a Bayesian Quadrature scheme to make this marginalisation more efficient and thereby more practical. Through use of the maximum mean discrepancies between distributions, we define a kernel over kernels that captures invariances between Spectral Mixture (SM) Kernels. Kernel samples are selected by generalising an information-theoretic acquisition function for warped Bayesian Quadrature. We show that our framework achieves more accurate predictions with better calibrated uncertainty than state-of-the-art baselines, especially when given limited (wall-clock) time budgets.
Same State, Different Task: Continual Reinforcement Learning without Interference
Jun 05, 2021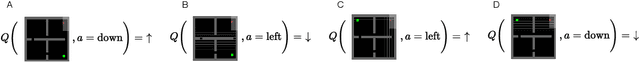



Continual Learning (CL) considers the problem of training an agent sequentially on a set of tasks while seeking to retain performance on all previous tasks. A key challenge in CL is catastrophic forgetting, which arises when performance on a previously mastered task is reduced when learning a new task. While a variety of methods exist to combat forgetting, in some cases tasks are fundamentally incompatible with each other and thus cannot be learnt by a single policy. This can occur, in reinforcement learning (RL) when an agent may be rewarded for achieving different goals from the same observation. In this paper we formalize this ``interference'' as distinct from the problem of forgetting. We show that existing CL methods based on single neural network predictors with shared replay buffers fail in the presence of interference. Instead, we propose a simple method, OWL, to address this challenge. OWL learns a factorized policy, using shared feature extraction layers, but separate heads, each specializing on a new task. The separate heads in OWL are used to prevent interference. At test time, we formulate policy selection as a multi-armed bandit problem, and show it is possible to select the best policy for an unknown task using feedback from the environment. The use of bandit algorithms allows the OWL agent to constructively re-use different continually learnt policies at different times during an episode. We show in multiple RL environments that existing replay based CL methods fail, while OWL is able to achieve close to optimal performance when training sequentially.
OffCon$^3$: What is state of the art anyway?
Jan 27, 2021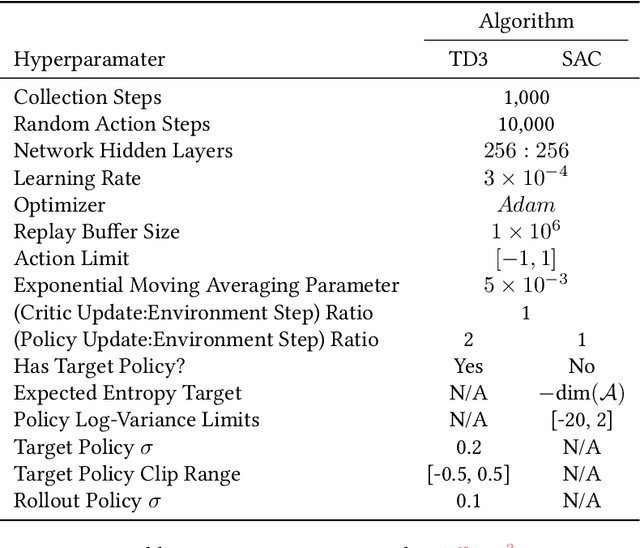
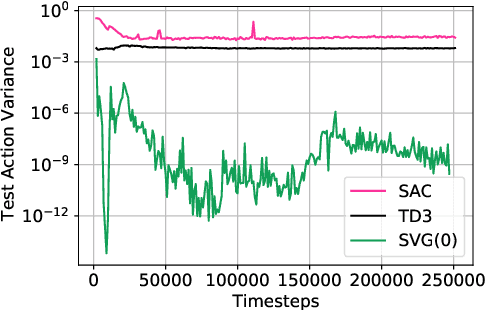
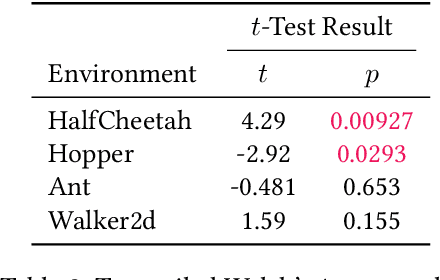
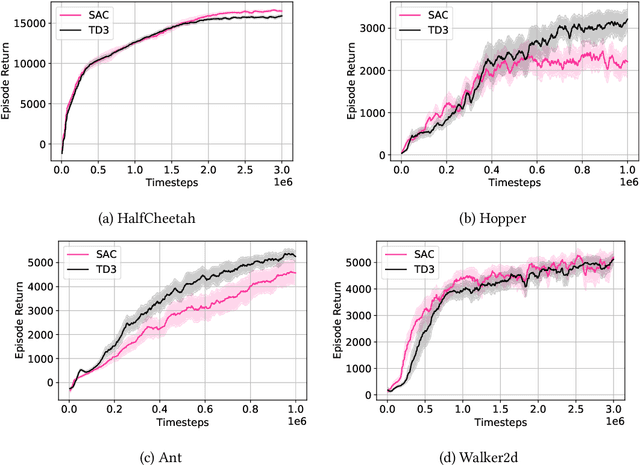
Two popular approaches to model-free continuous control tasks are SAC and TD3. At first glance these approaches seem rather different; SAC aims to solve the entropy-augmented MDP by minimising the KL-divergence between a stochastic proposal policy and a hypotheical energy-basd soft Q-function policy, whereas TD3 is derived from DPG, which uses a deterministic policy to perform policy gradient ascent along the value function. In reality, both approaches are remarkably similar, and belong to a family of approaches we call `Off-Policy Continuous Generalized Policy Iteration'. This illuminates their similar performance in most continuous control benchmarks, and indeed when hyperparameters are matched, their performance can be statistically indistinguishable. To further remove any difference due to implementation, we provide OffCon$^3$ (Off-Policy Continuous Control: Consolidated), a code base featuring state-of-the-art versions of both algorithms.
The Effect of Prior Lipschitz Continuity on the Adversarial Robustness of Bayesian Neural Networks
Jan 07, 2021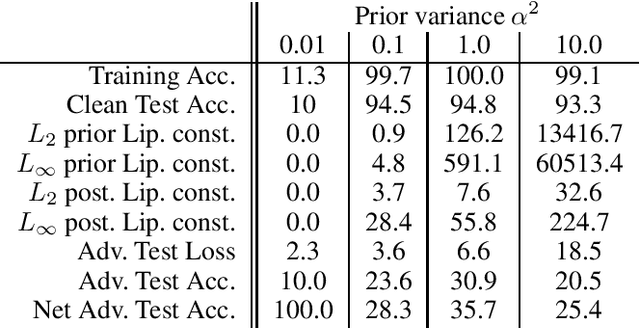
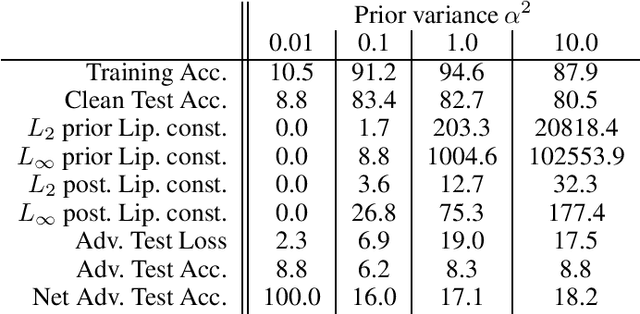
It is desirable, and often a necessity, for machine learning models to be robust against adversarial attacks. This is particularly true for Bayesian models, as they are well-suited for safety-critical applications, in which adversarial attacks can have catastrophic outcomes. In this work, we take a deeper look at the adversarial robustness of Bayesian Neural Networks (BNNs). In particular, we consider whether the adversarial robustness of a BNN can be increased by model choices, particularly the Lipschitz continuity induced by the prior. Conducting in-depth analysis on the case of i.i.d., zero-mean Gaussian priors and posteriors approximated via mean-field variational inference, we find evidence that adversarial robustness is indeed sensitive to the prior variance.
Introducing an Explicit Symplectic Integration Scheme for Riemannian Manifold Hamiltonian Monte Carlo
Oct 14, 2019

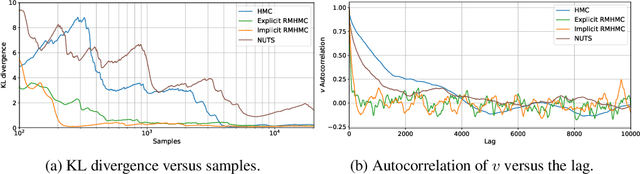
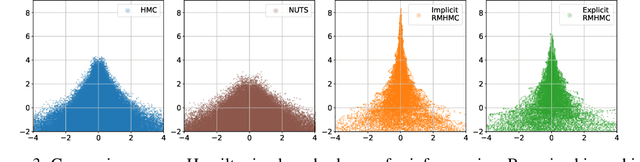
We introduce a recent symplectic integration scheme derived for solving physically motivated systems with non-separable Hamiltonians. We show its relevance to Riemannian manifold Hamiltonian Monte Carlo (RMHMC) and provide an alternative to the currently used generalised leapfrog symplectic integrator, which relies on solving multiple fixed point iterations to convergence. Via this approach, we are able to reduce the number of higher-order derivative calculations per leapfrog step. We explore the implications of this integrator and demonstrate its efficacy in reducing the computational burden of RMHMC. Our code is provided in a new open-source Python package, hamiltorch.
Adaptive Configuration Oracle for Online Portfolio Selection Methods
Aug 22, 2019
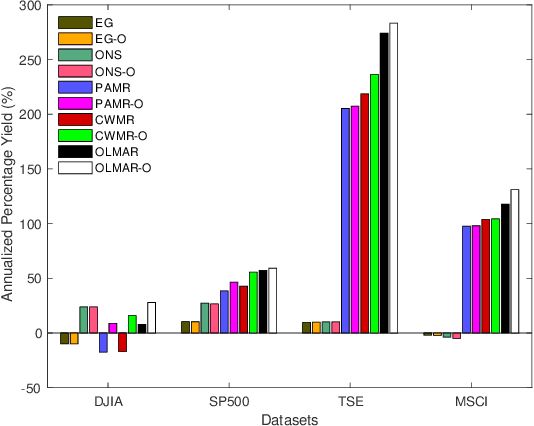
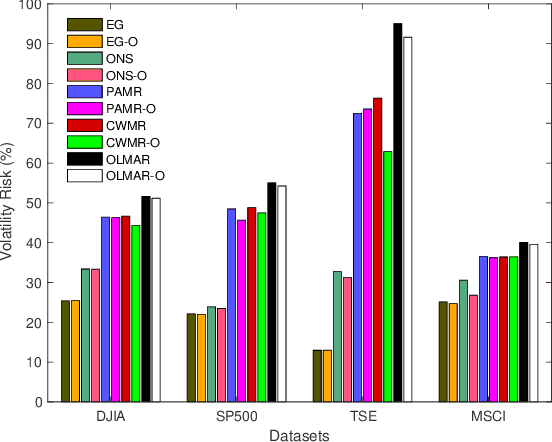
Financial markets are complex environments that produce enormous amounts of noisy and non-stationary data. One fundamental problem is online portfolio selection, the goal of which is to exploit this data to sequentially select portfolios of assets to achieve positive investment outcomes while managing risks. Various algorithms have been proposed for solving this problem in fields such as finance, statistics and machine learning, among others. Most of the methods have parameters that are estimated from backtests for good performance. Since these algorithms operate on non-stationary data that reflects the complexity of financial markets, we posit that adaptively tuning these parameters in an intelligent manner is a remedy for dealing with this complexity. In this paper, we model the mapping between the parameter space and the space of performance metrics using a Gaussian process prior. We then propose an oracle based on adaptive Bayesian optimization for automatically and adaptively configuring online portfolio selection methods. We test the efficacy of our solution on algorithms operating on equity and index data from various markets.
Bayesian Heatmaps: Probabilistic Classification with Multiple Unreliable Information Sources
Apr 05, 2019
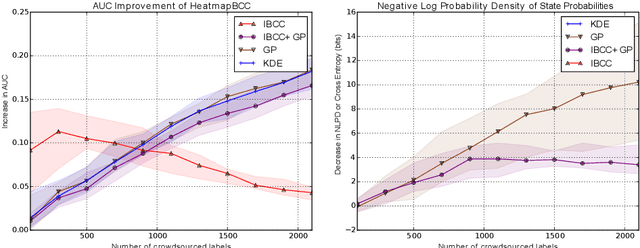
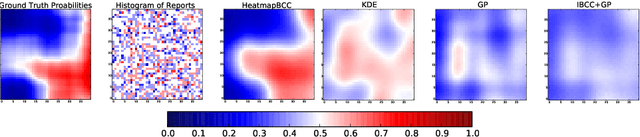
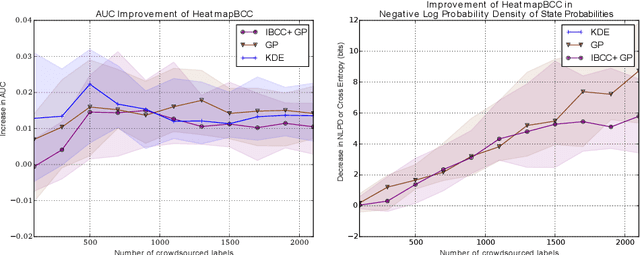
Unstructured data from diverse sources, such as social media and aerial imagery, can provide valuable up-to-date information for intelligent situation assessment. Mining these different information sources could bring major benefits to applications such as situation awareness in disaster zones and mapping the spread of diseases. Such applications depend on classifying the situation across a region of interest, which can be depicted as a spatial "heatmap". Annotating unstructured data using crowdsourcing or automated classifiers produces individual classifications at sparse locations that typically contain many errors. We propose a novel Bayesian approach that models the relevance, error rates and bias of each information source, enabling us to learn a spatial Gaussian Process classifier by aggregating data from multiple sources with varying reliability and relevance. Our method does not require gold-labelled data and can make predictions at any location in an area of interest given only sparse observations. We show empirically that our approach can handle noisy and biased data sources, and that simultaneously inferring reliability and transferring information between neighbouring reports leads to more accurate predictions. We demonstrate our method on two real-world problems from disaster response, showing how our approach reduces the amount of crowdsourced data required and can be used to generate valuable heatmap visualisations from SMS messages and satellite images.