 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAOMI: Non-Autoregressive Multiresolution Sequence Imputation
Jan 30, 2019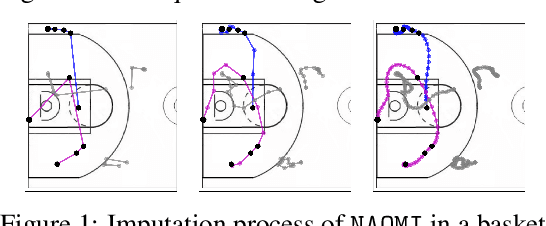

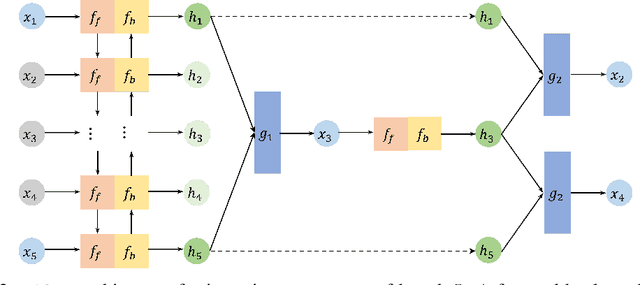

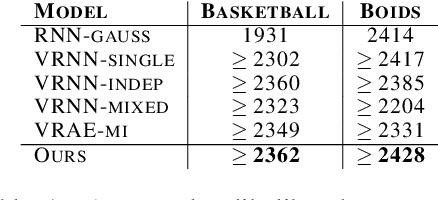
Missing value imputation is a fundamental problem in modeling spatiotemporal sequences, from motion tracking to the dynamics of physical systems. In this paper, we take a non-autoregressive approach and propose a novel deep generative model: Non-AutOregressive Multiresolution Imputation (NAOMI) for imputing long-range spatiotemporal sequences given arbitrary missing patterns. In particular, NAOMI exploits the multiresolution structure of spatiotemporal data to interpolate recursively from coarse to fine-grained resolutions. We further enhance our model with adversarial training using an imitation learning objective. When trained on billiards and basketball trajectories, NAOMI demonstrates significant improvement in imputation accuracy (reducing average prediction error by 60% compared to autoregressive counterparts) and generalization capability for long range trajectories in systems of both deterministic and stochastic dynamics.
Generative Multi-Agent Behavioral Cloning
May 20, 2018
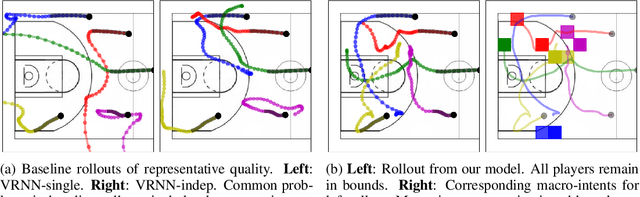
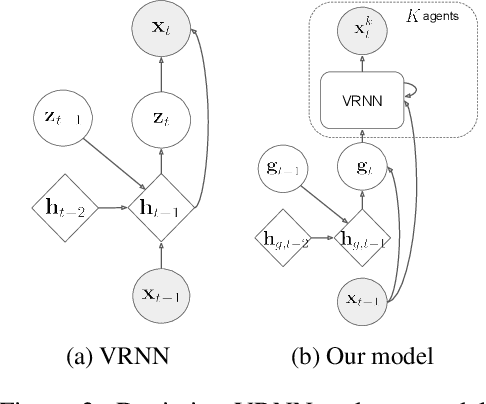
We propose and study the problem of generative multi-agent behavioral cloning, where the goal is to learn a generative, i.e., non-deterministic, multi-agent policy from pre-collected demonstration data. Building upon advances in deep generative models, we present a hierarchical policy framework that can tractably learn complex mappings from input states to distributions over multi-agent action spaces by introducing a hierarchy with macro-intent variables that encode long-term intent. In addition to synthetic settings, we show how to instantiate our framework to effectively model complex interactions between basketball players and generate realistic multi-agent trajectories of basketball gameplay over long time periods. We validate our approach using both quantitative and qualitative evaluations, including a user study comparison conducted with professional sports analysts.
Detecting Adversarial Examples via Neural Fingerprinting
Mar 29, 2018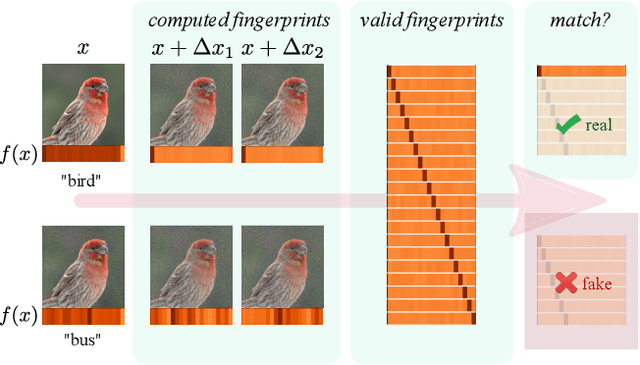
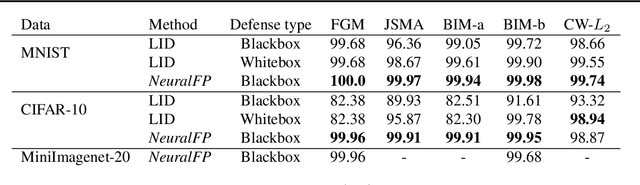
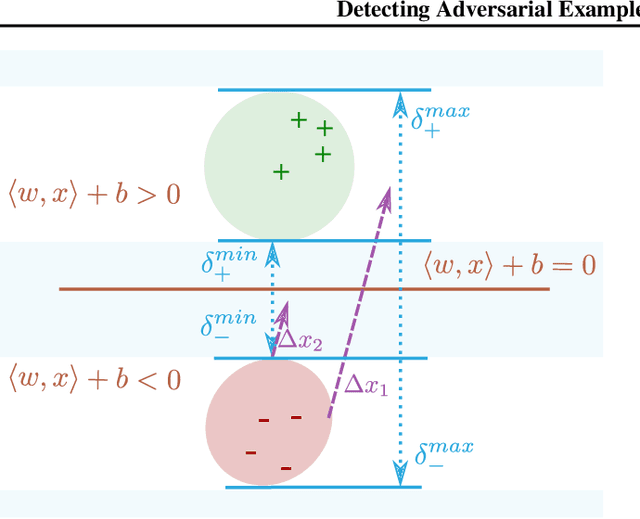

Deep neural networks are vulnerable to adversarial examples, which dramatically alter model output using small input changes. We propose Neural Fingerprinting, a simple, yet effective method to detect adversarial examples by verifying whether model behavior is consistent with a set of secret fingerprints, inspired by the use of biometric and cryptographic signatures. The benefits of our method are that 1) it is fast, 2) it is prohibitively expensive for an attacker to reverse-engineer which fingerprints were used, and 3) it does not assume knowledge of the adversary. In this work, we pose a formal framework to analyze fingerprints under various threat models, and characterize Neural Fingerprinting for linear models. For complex neural networks, we empirically demonstrate that Neural Fingerprinting significantly improves on state-of-the-art detection mechanisms by detecting the strongest known adversarial attacks with 98-100% AUC-ROC scores on the MNIST, CIFAR-10 and MiniImagenet (20 classes) datasets. In particular, the detection accuracy of Neural Fingerprinting generalizes well to unseen test-data under various black- and whitebox threat models, and is robust over a wide range of hyperparameters and choices of fingerprints.
Long-term Forecasting using Tensor-Train RNNs
Mar 06, 2018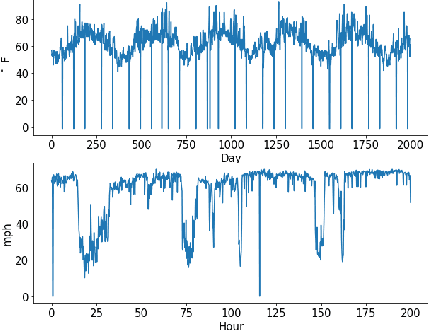
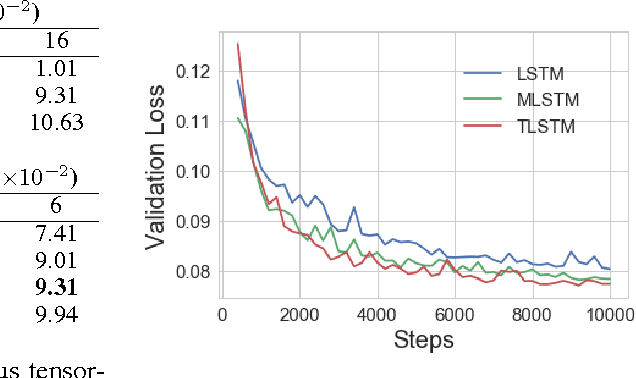
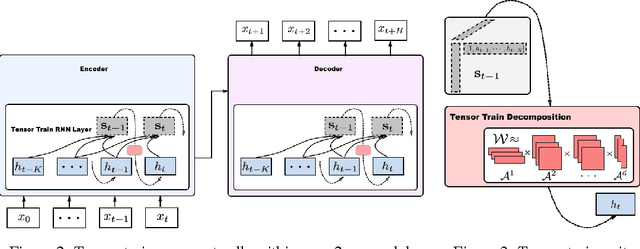

We present Tensor-Train RNN (TT-RNN), a novel family of neural sequence architectures for multivariate forecasting in environments with nonlinear dynamics. Long-term forecasting in such systems is highly challenging, since there exist long-term temporal dependencies, higher-order correlations and sensitivity to error propagation. Our proposed tensor recurrent architecture addresses these issues by learning the nonlinear dynamics directly using higher order moments and high-order state transition functions. Furthermore, we decompose the higher-order structure using the tensor-train (TT) decomposition to reduce the number of parameters while preserving the model performance. We theoretically establish the approximation properties of Tensor-Train RNNs for general sequence inputs, and such guarantees are not available for usual RNNs. We also demonstrate significant long-term prediction improvements over general RNN and LSTM architectures on a range of simulated environments with nonlinear dynamics, as well on real-world climate and traffic data.
Multi-resolution Tensor Learning for Large-Scale Spatial Data
Feb 28, 2018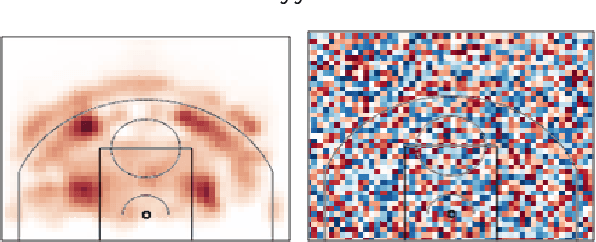

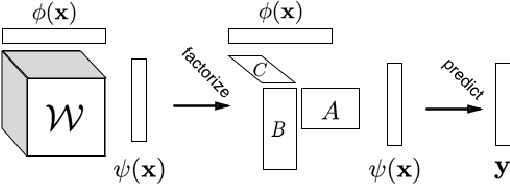
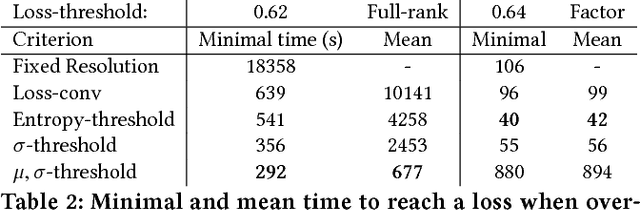
High-dimensional tensor models are notoriously computationally expensive to train. We present a meta-learning algorithm, MMT, that can significantly speed up the process for spatial tensor models. MMT leverages the property that spatial data can be viewed at multiple resolutions, which are related by coarsening and finegraining from one resolution to another. Using this property, MMT learns a tensor model by starting from a coarse resolution and iteratively increasing the model complexity. In order to not "over-train" on coarse resolution models, we investigate an information-theoretic fine-graining criterion to decide when to transition into higher-resolution models. We provide both theoretical and empirical evidence for the advantages of this approach. When applied to two real-world large-scale spatial datasets for basketball player and animal behavior modeling, our approach demonstrate 3 key benefits: 1) it efficiently captures higher-order interactions (i.e., tensor latent factors), 2) it is orders of magnitude faster than fixed resolution learning and scales to very fine-grained spatial resolutions, and 3) it reliably yields accurate and interpretable models.
Generating Long-term Trajectories Using Deep Hierarchical Networks
Jun 21, 2017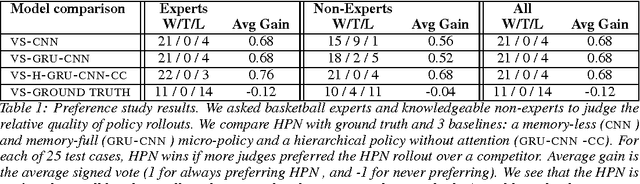
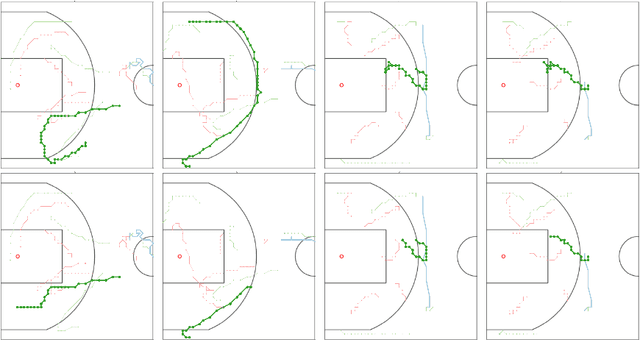
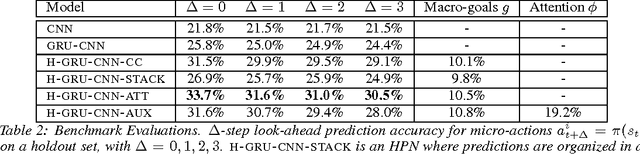
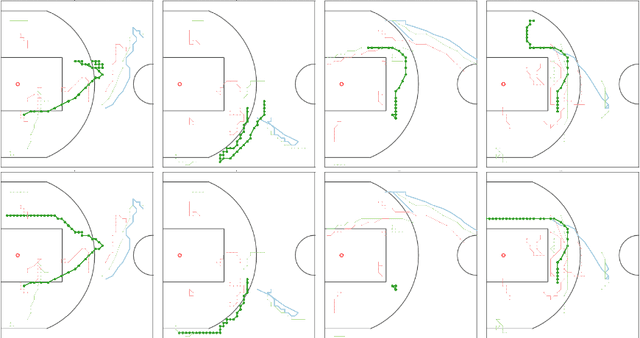
We study the problem of modeling spatiotemporal trajectories over long time horizons using expert demonstrations. For instance, in sports, agents often choose action sequences with long-term goals in mind, such as achieving a certain strategic position. Conventional policy learning approaches, such as those based on Markov decision processes, generally fail at learning cohesive long-term behavior in such high-dimensional state spaces, and are only effective when myopic modeling lead to the desired behavior. The key difficulty is that conventional approaches are "shallow" models that only learn a single state-action policy. We instead propose a hierarchical policy class that automatically reasons about both long-term and short-term goals, which we instantiate as a hierarchical neural network. We showcase our approach in a case study on learning to imitate demonstrated basketball trajectories, and show that it generates significantly more realistic trajectories compared to non-hierarchical baselines as judged by professional sports analysts.
Improving the Robustness of Deep Neural Networks via Stability Training
Apr 15, 2016


In this paper we address the issue of output instability of deep neural networks: small perturbations in the visual input can significantly distort the feature embeddings and output of a neural network. Such instability affects many deep architectures with state-of-the-art performance on a wide range of computer vision tasks. We present a general stability training method to stabilize deep networks against small input distortions that result from various types of common image processing, such as compression, rescaling, and cropping. We validate our method by stabilizing the state-of-the-art Inception architecture against these types of distortions. In addition, we demonstrate that our stabilized model gives robust state-of-the-art performance on large-scale near-duplicate detection, similar-image ranking, and classification on noisy datasets.