 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Probabilities of Error to Combine Quantization and Early Exiting: QuEE
Jun 20, 2024



Machine learning models can solve complex tasks but often require significant computational resources during inference. This has led to the development of various post-training computation reduction methods that tackle this issue in different ways, such as quantization which reduces the precision of weights and arithmetic operations, and dynamic networks which adapt computation to the sample at hand. In this work, we propose a more general dynamic network that can combine both quantization and early exit dynamic network: QuEE. Our algorithm can be seen as a form of soft early exiting or input-dependent compression. Rather than a binary decision between exiting or continuing, we introduce the possibility of continuing with reduced computation. This complicates the traditionally considered early exiting problem, which we solve through a principled formulation. The crucial factor of our approach is accurate prediction of the potential accuracy improvement achievable through further computation. We demonstrate the effectiveness of our method through empirical evaluation, as well as exploring the conditions for its success on 4 classification datasets.
Soft Prompt Threats: Attacking Safety Alignment and Unlearning in Open-Source LLMs through the Embedding Space
Feb 14, 2024



Current research in adversarial robustness of LLMs focuses on discrete input manipulations in the natural language space, which can be directly transferred to closed-source models. However, this approach neglects the steady progression of open-source models. As open-source models advance in capability, ensuring their safety also becomes increasingly imperative. Yet, attacks tailored to open-source LLMs that exploit full model access remain largely unexplored. We address this research gap and propose the embedding space attack, which directly attacks the continuous embedding representation of input tokens. We find that embedding space attacks circumvent model alignments and trigger harmful behaviors more efficiently than discrete attacks or model fine-tuning. Furthermore, we present a novel threat model in the context of unlearning and show that embedding space attacks can extract supposedly deleted information from unlearned LLMs across multiple datasets and models. Our findings highlight embedding space attacks as an important threat model in open-source LLMs. Trigger Warning: the appendix contains LLM-generated text with violence and harassment.
Topology-Matching Normalizing Flows for Out-of-Distribution Detection in Robot Learning
Nov 11, 2023



To facilitate reliable deployments of autonomous robots in the real world, Out-of-Distribution (OOD) detection capabilities are often required. A powerful approach for OOD detection is based on density estimation with Normalizing Flows (NFs). However, we find that prior work with NFs attempts to match the complex target distribution topologically with naive base distributions leading to adverse implications. In this work, we circumvent this topological mismatch using an expressive class-conditional base distribution trained with an information-theoretic objective to match the required topology. The proposed method enjoys the merits of wide compatibility with existing learned models without any performance degradation and minimum computation overhead while enhancing OOD detection capabilities. We demonstrate superior results in density estimation and 2D object detection benchmarks in comparison with extensive baselines. Moreover, we showcase the applicability of the method with a real-robot deployment.
BIRDNEST: Bayesian Inference for Ratings-Fraud Detection
Mar 07, 2016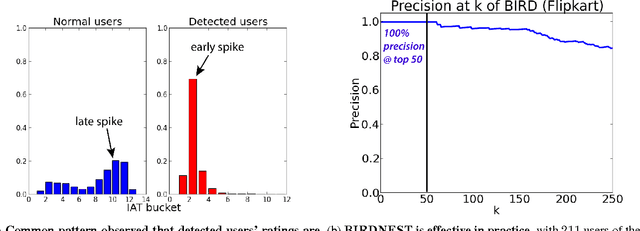
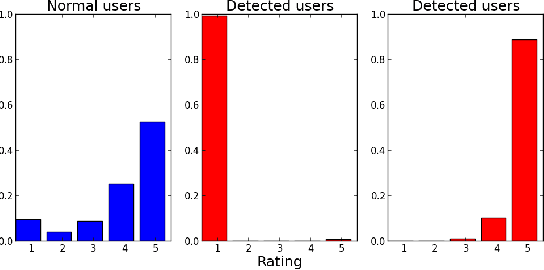
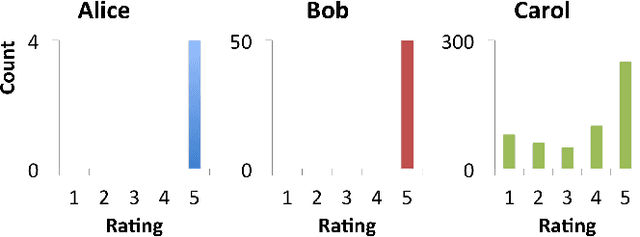
Review fraud is a pervasive problem in online commerce, in which fraudulent sellers write or purchase fake reviews to manipulate perception of their products and services. Fake reviews are often detected based on several signs, including 1) they occur in short bursts of time; 2) fraudulent user accounts have skewed rating distributions. However, these may both be true in any given dataset. Hence, in this paper, we propose an approach for detecting fraudulent reviews which combines these 2 approaches in a principled manner, allowing successful detection even when one of these signs is not present. To combine these 2 approaches, we formulate our Bayesian Inference for Rating Data (BIRD) model, a flexible Bayesian model of user rating behavior. Based on our model we formulate a likelihood-based suspiciousness metric, Normalized Expected Surprise Total (NEST). We propose a linear-time algorithm for performing Bayesian inference using our model and computing the metric. Experiments on real data show that BIRDNEST successfully spots review fraud in large, real-world graphs: the 50 most suspicious users of the Flipkart platform flagged by our algorithm were investigated and all identified as fraudulent by domain experts at Flipkart.