 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Prompt KV Cache: Where It Becomes Dispensable
May 28, 2026Prior KV cache compression schemes empirically demonstrate that the prompt cache is partially redundant during decoding, dropping or summarising entries with little accuracy loss. We ask when and what kind of redundancy: at which layers, after how many decoding steps, and in what form can the prompt span KV cache be replaced without breaking the task. A controlled splice intervention swept over layer cutoff and decoding steps shows this redundancy is about form (chat template scaffolding) rather than content. Replacing the upper layer prompt span KV cache with KV cache from a chat template scaffold whose user content is a neutral filler recovers near clean accuracy, while zeroing the same slots collapses accuracy. The dissociation replicates across the Qwen3, Gemma 3, and Llama 3 families on multiple datasets.
Achieving Fairness Across Local and Global Models in Federated Learning
Jun 24, 2024Achieving fairness across diverse clients in Federated Learning (FL) remains a significant challenge due to the heterogeneity of the data and the inaccessibility of sensitive attributes from clients' private datasets. This study addresses this issue by introducing \texttt{EquiFL}, a novel approach designed to enhance both local and global fairness in federated learning environments. \texttt{EquiFL} incorporates a fairness term into the local optimization objective, effectively balancing local performance and fairness. The proposed coordination mechanism also prevents bias from propagating across clients during the collaboration phase. Through extensive experiments across multiple benchmarks, we demonstrate that \texttt{EquiFL} not only strikes a better balance between accuracy and fairness locally at each client but also achieves global fairness. The results also indicate that \texttt{EquiFL} ensures uniform performance distribution among clients, thus contributing to performance fairness. Furthermore, we showcase the benefits of \texttt{EquiFL} in a real-world distributed dataset from a healthcare application, specifically in predicting the effects of treatments on patients across various hospital locations.
Federated Learning for Estimating Heterogeneous Treatment Effects
Feb 27, 2024


Machine learning methods for estimating heterogeneous treatment effects (HTE) facilitate large-scale personalized decision-making across various domains such as healthcare, policy making, education, and more. Current machine learning approaches for HTE require access to substantial amounts of data per treatment, and the high costs associated with interventions makes centrally collecting so much data for each intervention a formidable challenge. To overcome this obstacle, in this work, we propose a novel framework for collaborative learning of HTE estimators across institutions via Federated Learning. We show that even under a diversity of interventions and subject populations across clients, one can jointly learn a common feature representation, while concurrently and privately learning the specific predictive functions for outcomes under distinct interventions across institutions. Our framework and the associated algorithm are based on this insight, and leverage tabular transformers to map multiple input data to feature representations which are then used for outcome prediction via multi-task learning. We also propose a novel way of federated training of personalised transformers that can work with heterogeneous input feature spaces. Experimental results on real-world clinical trial data demonstrate the effectiveness of our method.
Privacy Preserving Bayesian Federated Learning in Heterogeneous Settings
Jun 13, 2023



In several practical applications of federated learning (FL), the clients are highly heterogeneous in terms of both their data and compute resources, and therefore enforcing the same model architecture for each client is very limiting. Moreover, the need for uncertainty quantification and data privacy constraints are often particularly amplified for clients that have limited local data. This paper presents a unified FL framework to simultaneously address all these constraints and concerns, based on training customized local Bayesian models that learn well even in the absence of large local datasets. A Bayesian framework provides a natural way of incorporating supervision in the form of prior distributions. We use priors in the functional (output) space of the networks to facilitate collaboration across heterogeneous clients. Moreover, formal differential privacy guarantees are provided for this framework. Experiments on standard FL datasets demonstrate that our approach outperforms strong baselines in both homogeneous and heterogeneous settings and under strict privacy constraints, while also providing characterizations of model uncertainties.
Federated Self-supervised Learning for Heterogeneous Clients
May 31, 2022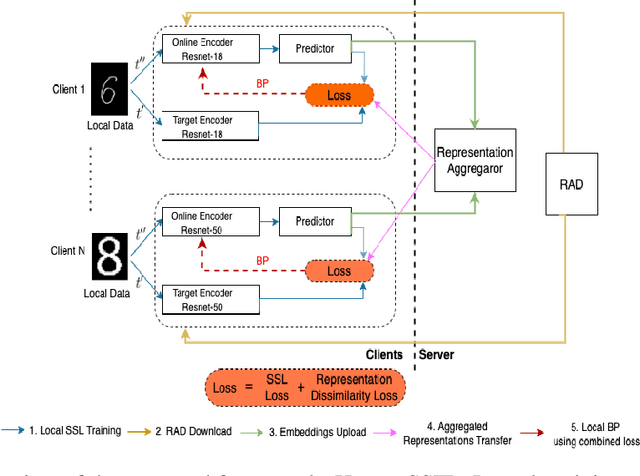
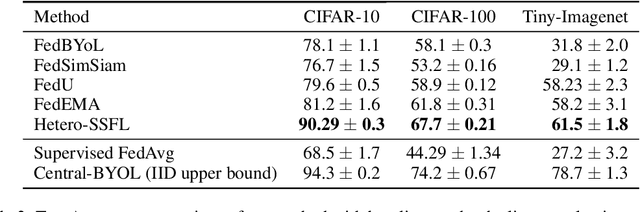

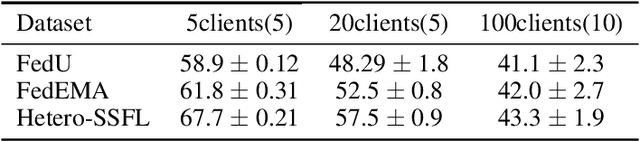
Federated Learning has become an important learning paradigm due to its privacy and computational benefits. As the field advances, two key challenges that still remain to be addressed are: (1) system heterogeneity - variability in the compute and/or data resources present on each client, and (2) lack of labeled data in certain federated settings. Several recent developments have tried to overcome these challenges independently. In this work, we propose a unified and systematic framework, \emph{Heterogeneous Self-supervised Federated Learning} (Hetero-SSFL) for enabling self-supervised learning with federation on heterogeneous clients. The proposed framework allows collaborative representation learning across all the clients without imposing architectural constraints or requiring presence of labeled data. The key idea in Hetero-SSFL is to let each client train its unique self-supervised model and enable the joint learning across clients by aligning the lower dimensional representations on a common dataset. The entire training procedure could be viewed as self and peer-supervised as both the local training and the alignment procedures do not require presence of any labeled data. As in conventional self-supervised learning, the obtained client models are task independent and can be used for varied end-tasks. We provide a convergence guarantee of the proposed framework for non-convex objectives in heterogeneous settings and also empirically demonstrate that our proposed approach outperforms the state of the art methods by a significant margin.
Architecture Agnostic Federated Learning for Neural Networks
Feb 17, 2022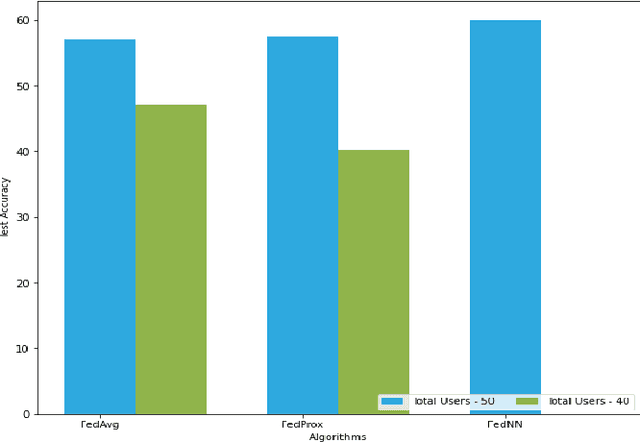
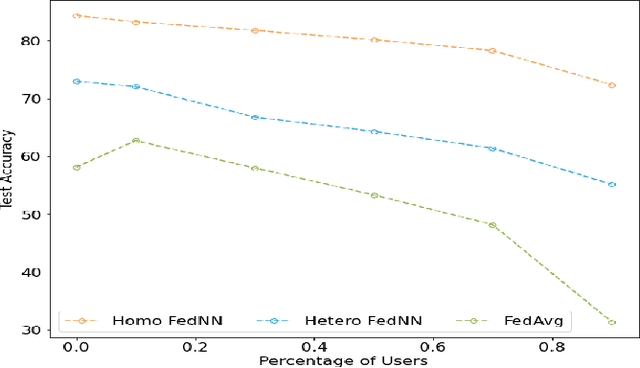
With growing concerns regarding data privacy and rapid increase in data volume, Federated Learning(FL) has become an important learning paradigm. However, jointly learning a deep neural network model in a FL setting proves to be a non-trivial task because of the complexities associated with the neural networks, such as varied architectures across clients, permutation invariance of the neurons, and presence of non-linear transformations in each layer. This work introduces a novel Federated Heterogeneous Neural Networks (FedHeNN) framework that allows each client to build a personalised model without enforcing a common architecture across clients. This allows each client to optimize with respect to local data and compute constraints, while still benefiting from the learnings of other (potentially more powerful) clients. The key idea of FedHeNN is to use the instance-level representations obtained from peer clients to guide the simultaneous training on each client. The extensive experimental results demonstrate that the FedHeNN framework is capable of learning better performing models on clients in both the settings of homogeneous and heterogeneous architectures across clients.
Audience Creation for Consumables -- Simple and Scalable Precision Merchandising for a Growing Marketplace
Nov 17, 2020
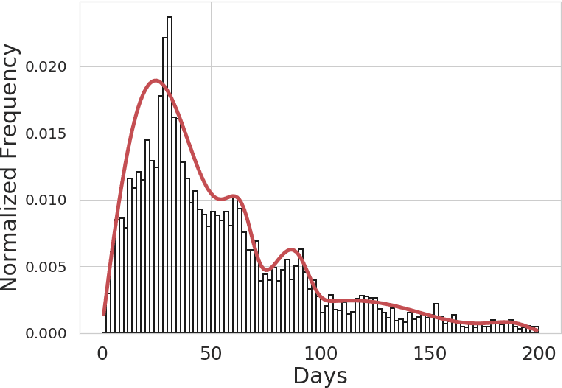
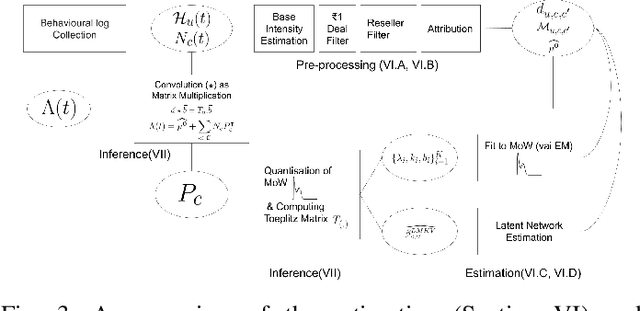
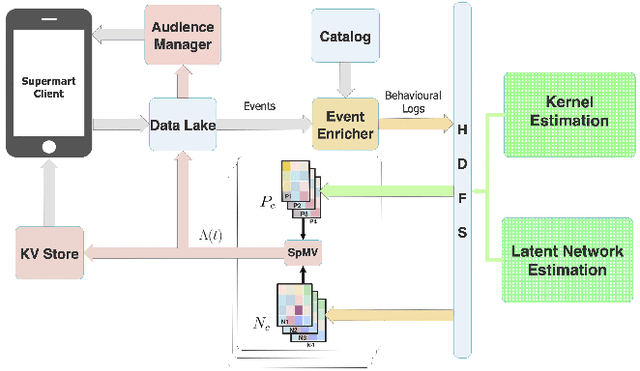
Consumable categories, such as grocery and fast-moving consumer goods, are quintessential to the growth of e-commerce marketplaces in developing countries. In this work, we present the design and implementation of a precision merchandising system, which creates audience sets from over 10 million consumers and is deployed at Flipkart Supermart, one of the largest online grocery stores in India. We employ temporal point process to model the latent periodicity and mutual-excitation in the purchase dynamics of consumables. Further, we develop a likelihood-free estimation procedure that is robust against data sparsity, censure and noise typical of a growing marketplace. Lastly, we scale the inference by quantizing the triggering kernels and exploiting sparse matrix-vector multiplication primitive available on a commercial distributed linear algebra backend. In operation spanning more than a year, we have witnessed a consistent increase in click-through rate in the range of 25-70% for banner-based merchandising in the storefront, and in the range of 12-26% for push notification-based campaigns.
FairJudge: Trustworthy User Prediction in Rating Platforms
Mar 30, 2017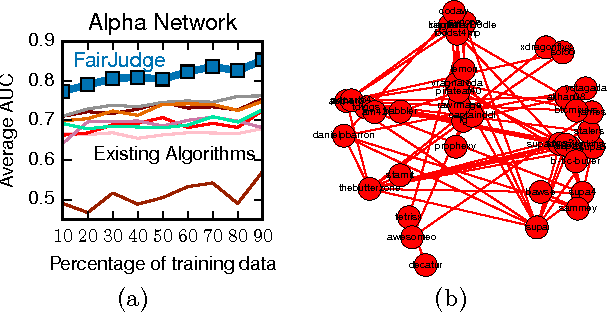

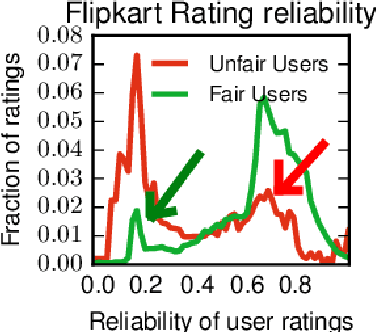
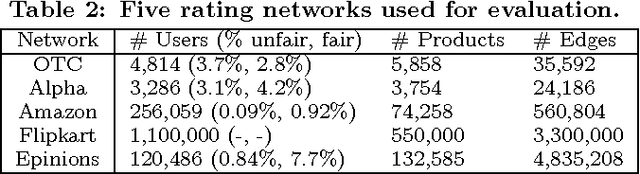
Rating platforms enable large-scale collection of user opinion about items (products, other users, etc.). However, many untrustworthy users give fraudulent ratings for excessive monetary gains. In the paper, we present FairJudge, a system to identify such fraudulent users. We propose three metrics: (i) the fairness of a user that quantifies how trustworthy the user is in rating the products, (ii) the reliability of a rating that measures how reliable the rating is, and (iii) the goodness of a product that measures the quality of the product. Intuitively, a user is fair if it provides reliable ratings that are close to the goodness of the product. We formulate a mutually recursive definition of these metrics, and further address cold start problems and incorporate behavioral properties of users and products in the formulation. We propose an iterative algorithm, FairJudge, to predict the values of the three metrics. We prove that FairJudge is guaranteed to converge in a bounded number of iterations, with linear time complexity. By conducting five different experiments on five rating platforms, we show that FairJudge significantly outperforms nine existing algorithms in predicting fair and unfair users. We reported the 100 most unfair users in the Flipkart network to their review fraud investigators, and 80 users were correctly identified (80% accuracy). The FairJudge algorithm is already being deployed at Flipkart.
BIRDNEST: Bayesian Inference for Ratings-Fraud Detection
Mar 07, 2016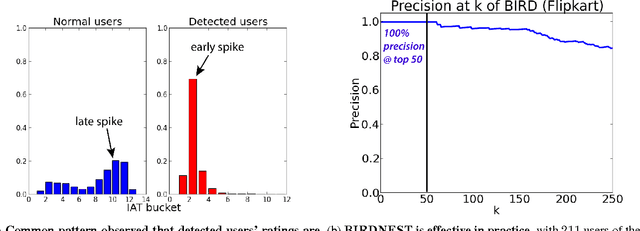
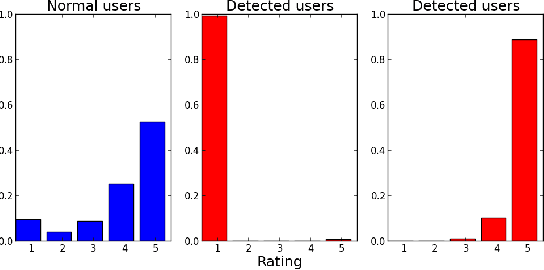
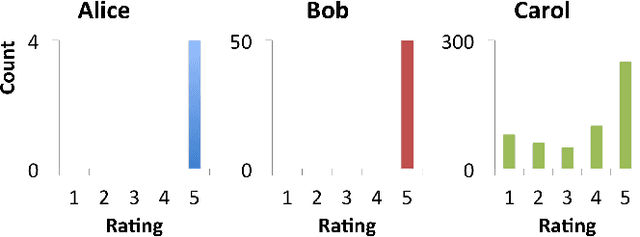
Review fraud is a pervasive problem in online commerce, in which fraudulent sellers write or purchase fake reviews to manipulate perception of their products and services. Fake reviews are often detected based on several signs, including 1) they occur in short bursts of time; 2) fraudulent user accounts have skewed rating distributions. However, these may both be true in any given dataset. Hence, in this paper, we propose an approach for detecting fraudulent reviews which combines these 2 approaches in a principled manner, allowing successful detection even when one of these signs is not present. To combine these 2 approaches, we formulate our Bayesian Inference for Rating Data (BIRD) model, a flexible Bayesian model of user rating behavior. Based on our model we formulate a likelihood-based suspiciousness metric, Normalized Expected Surprise Total (NEST). We propose a linear-time algorithm for performing Bayesian inference using our model and computing the metric. Experiments on real data show that BIRDNEST successfully spots review fraud in large, real-world graphs: the 50 most suspicious users of the Flipkart platform flagged by our algorithm were investigated and all identified as fraudulent by domain experts at Flipkart.