 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Heterogeneity in Climate Risk and Human Flourishing: An Exploration with Generative AI
Jan 26, 2026Recent advances in Generative Artificial Intelligence (AI), particularly Large Language Models (LLMs), enable scalable extraction of spatial information from unstructured text and offer new methodological opportunities for studying climate geography. This study develops a spatial framework to examine how cumulative climate risk relates to multidimensional human flourishing across U.S. counties. High-resolution climate hazard indicators are integrated with a Human Flourishing Geographic Index (HFGI), an index derived from classification of 2.6 billion geotagged tweets using fine-tuned open-source Large Language Models (LLMs). These indicators are aggregated to the US county-level and mapped to a structural equation model to infer overall climate risk and human flourishing dimensions, including expressed well-being, meaning and purpose, social connectedness, psychological distress, physical condition, economic stability, religiosity, character and virtue, and institutional trust. The results reveal spatially heterogeneous associations between greater cumulative climate risk and lower levels of expressed human flourishing, with coherent spatial patterns corresponding to recurrent exposure to heat, flooding, wind, drought, and wildfire hazards. The study demonstrates how Generative AI can be combined with latent construct modeling for geographical analysis and for spatial knowledge extraction.
Two Americas of Well-Being: Divergent Rural-Urban Patterns of Life Satisfaction and Happiness from 2.6 B Social Media Posts
Nov 13, 2025Using 2.6 billion geolocated social-media posts (2014-2022) and a fine-tuned generative language model, we construct county-level indicators of life satisfaction and happiness for the United States. We document an apparent rural-urban paradox: rural counties express higher life satisfaction while urban counties exhibit greater happiness. We reconcile this by treating the two as distinct layers of subjective well-being, evaluative vs. hedonic, showing that each maps differently onto place, politics, and time. Republican-leaning areas appear more satisfied in evaluative terms, but partisan gaps in happiness largely flatten outside major metros, indicating context-dependent political effects. Temporal shocks dominate the hedonic layer: happiness falls sharply during 2020-2022, whereas life satisfaction moves more modestly. These patterns are robust across logistic and OLS specifications and align with well-being theory. Interpreted as associations for the population of social-media posts, the results show that large-scale, language-based indicators can resolve conflicting findings about the rural-urban divide by distinguishing the type of well-being expressed, offering a transparent, reproducible complement to traditional surveys.
Learning the Topic, Not the Language: How LLMs Classify Online Immigration Discourse Across Languages
Aug 08, 2025



Large language models (LLMs) are transforming social-science research by enabling scalable, precise analysis. Their adaptability raises the question of whether knowledge acquired through fine-tuning in a few languages can transfer to unseen languages that only appeared during pre-training. To examine this, we fine-tune lightweight LLaMA 3.2-3B models on monolingual, bilingual, or multilingual data sets to classify immigration-related tweets from X/Twitter across 13 languages, a domain characterised by polarised, culturally specific discourse. We evaluate whether minimal language-specific fine-tuning enables cross-lingual topic detection and whether adding targeted languages corrects pre-training biases. Results show that LLMs fine-tuned in one or two languages can reliably classify immigration-related content in unseen languages. However, identifying whether a tweet expresses a pro- or anti-immigration stance benefits from multilingual fine-tuning. Pre-training bias favours dominant languages, but even minimal exposure to under-represented languages during fine-tuning (as little as $9.62\times10^{-11}$ of the original pre-training token volume) yields significant gains. These findings challenge the assumption that cross-lingual mastery requires extensive multilingual training: limited language coverage suffices for topic-level generalisation, and structural biases can be corrected with lightweight interventions. By releasing 4-bit-quantised, LoRA fine-tuned models, we provide an open-source, reproducible alternative to proprietary LLMs that delivers 35 times faster inference at just 0.00000989% of the dollar cost of the OpenAI GPT-4o model, enabling scalable, inclusive research.
Rethinking Scale: The Efficacy of Fine-Tuned Open-Source LLMs in Large-Scale Reproducible Social Science Research
Oct 31, 2024



Large Language Models (LLMs) are distinguished by their architecture, which dictates their parameter size and performance capabilities. Social scientists have increasingly adopted LLMs for text classification tasks, which are difficult to scale with human coders. While very large, closed-source models often deliver superior performance, their use presents significant risks. These include lack of transparency, potential exposure of sensitive data, challenges to replicability, and dependence on proprietary systems. Additionally, their high costs make them impractical for large-scale research projects. In contrast, open-source models, although available in various sizes, may underperform compared to commercial alternatives if used without further fine-tuning. However, open-source models offer distinct advantages: they can be run locally (ensuring data privacy), fine-tuned for specific tasks, shared within the research community, and integrated into reproducible workflows. This study demonstrates that small, fine-tuned open-source LLMs can achieve equal or superior performance to models such as ChatGPT-4. We further explore the relationship between training set size and fine-tuning efficacy in open-source models. Finally, we propose a hybrid workflow that leverages the strengths of both open and closed models, offering a balanced approach to performance, transparency, and reproducibility.
Mobility Functional Areas and COVID-19 Spread
Mar 31, 2021



This work introduces a new concept of functional areas called Mobility Functional Areas (MFAs), i.e., the geographic zones highly interconnected according to the analysis of mobile positioning data. The MFAs do not coincide necessarily with administrative borders as they are built observing natural human mobility and, therefore, they can be used to inform, in a bottom-up approach, local transportation, health and economic policies. After presenting the methodology behind the MFAs, this study focuses on the link between the COVID-19 pandemic and the MFAs in Austria. It emerges that the MFAs registered an average number of infections statistically larger than the areas in the rest of the country, suggesting the usefulness of the MFAs in the context of targeted re-escalation policy responses to this health crisis.
Twitter Subjective Well-Being Indicator During COVID-19 Pandemic: A Cross-Country Comparative Study
Jan 19, 2021
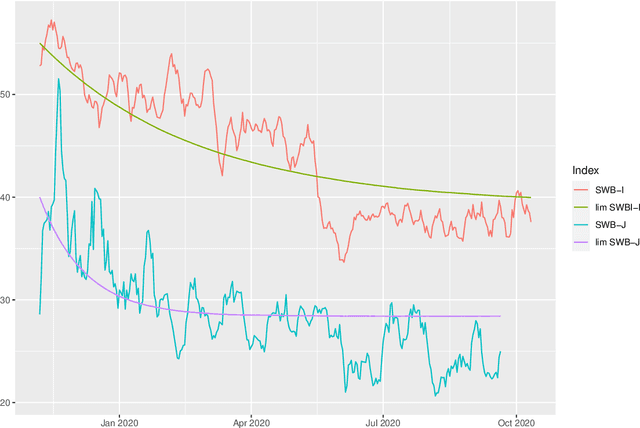
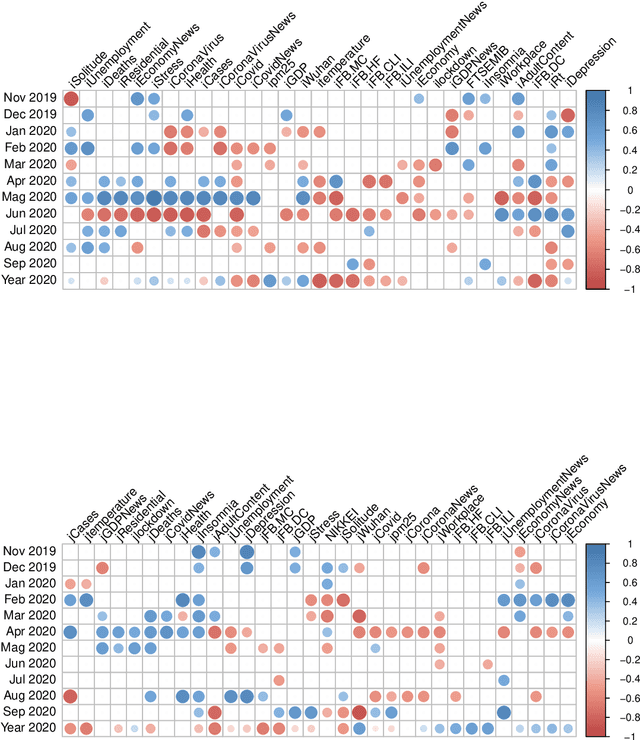

This study analyzes the impact of the COVID-19 pandemic on the subjective well-being as measured through Twitter data indicators for Japan and Italy. It turns out that, overall, the subjective well-being dropped by 11.7% for Italy and 8.3% for Japan in the first nine months of 2020 compared to the last two months of 2019 and even more compared to the historical mean of the indexes. Through a data science approach we try to identify the possible causes of this drop down by considering several explanatory variables including, climate and air quality data, number of COVID-19 cases and deaths, Facebook Covid and flu symptoms global survey, Google Trends data and coronavirus-related searches, Google mobility data, policy intervention measures, economic variables and their Google Trends proxies, as well as health and stress proxy variables based on big data. We show that a simple static regression model is not able to capture the complexity of well-being and therefore we propose a dynamic elastic net approach to show how different group of factors may impact the well-being in different periods, even over a short time length, and showing further country-specific aspects. Finally, a structural equation modeling analysis tries to address the causal relationships among the COVID-19 factors and subjective well-being showing that, overall, prolonged mobility restrictions,flu and Covid-like symptoms, economic uncertainty, social distancing and news about the pandemic have negative effects on the subjective well-being.
Forecasting asylum applications in the European Union with machine learning and data at scale
Nov 10, 2020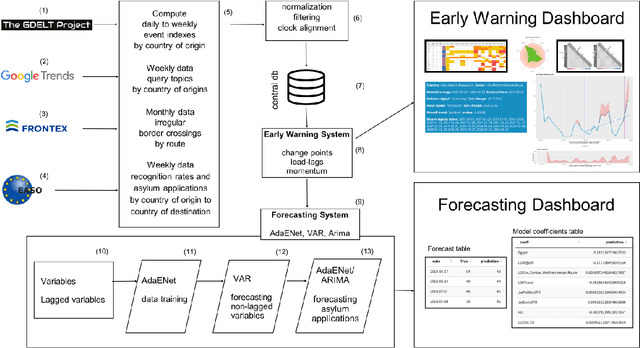
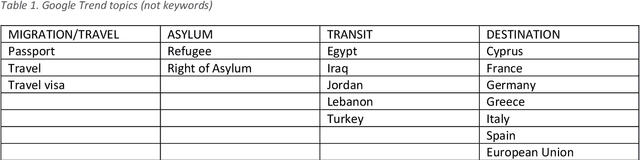
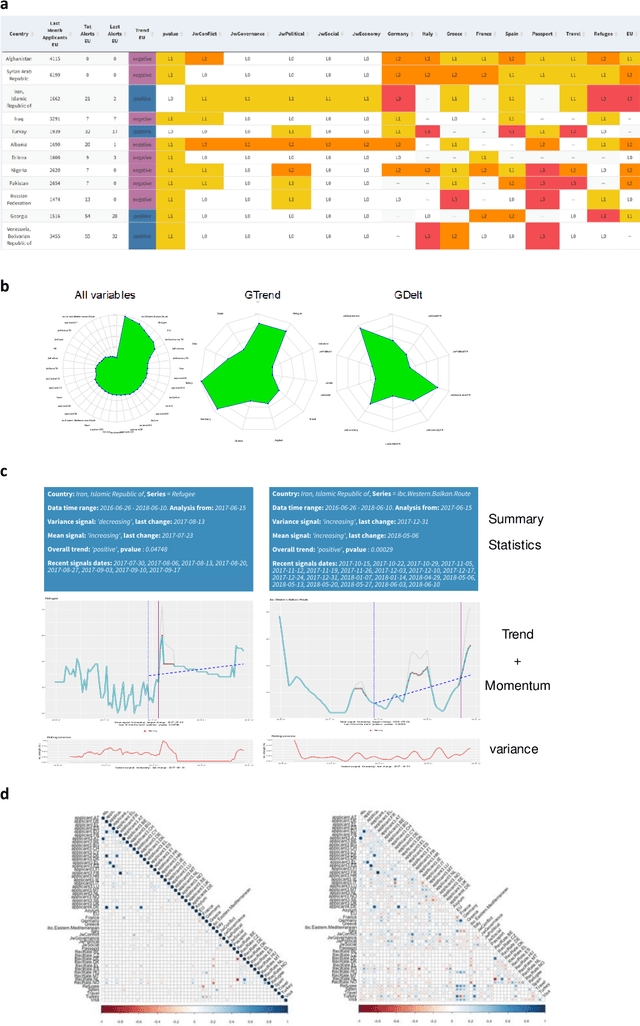
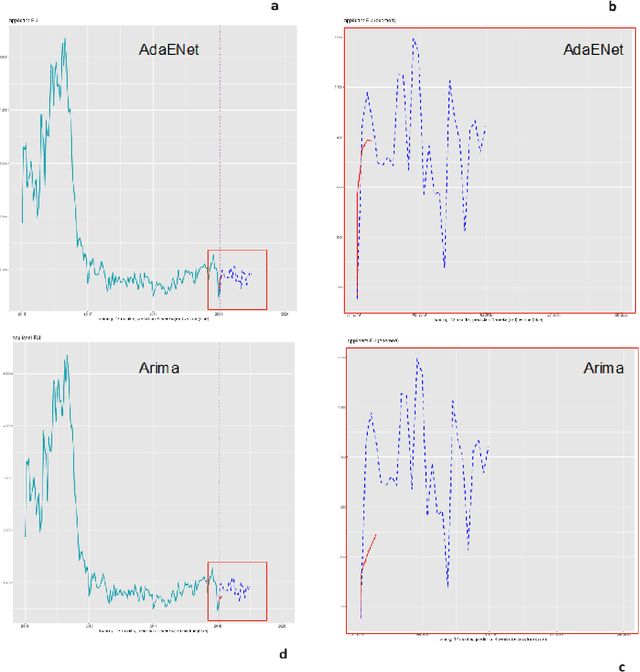
The effects of the so-called "refugee crisis" of 2015-16 continue to dominate much of the European political agenda. Migration flows were sudden and unexpected, exposing significant shortcomings in the field of migration forecasting and leaving governments and NGOs unprepared. Migration is a complex system typified by episodic variation, underpinned by causal factors that are interacting, highly context dependent and short-lived. Correspondingly, migration nowcasts rely on scattered low-quality data and much-needed forecasts are local and inconsistent. Here we describe a data-driven adaptive system for forecasting asylum applications in the European Union (EU), built on machine learning algorithms that combine administrative data with non-traditional data sources at scale. We exploit three tiers of data: geolocated events and internet searches in countries of origin, detections at the EU external border, and asylum recognition rates in the EU, to effectively forecast individual asylum-migration flows up to four weeks ahead with high accuracy. Uniquely our approach a) models individual country-to-country migration flows; b) detects migration drivers early onset; c) anticipates lagged effects; d) estimates the effect of individual drivers; and e) describes how patterns of drivers shift over time. This is, to our knowledge, the first comprehensive system for forecasting asylum applications based on an unsupervised algorithm and data at scale. Importantly, this approach can be extended to forecast other migration social-economic indicators.
Is Japanese gendered language used on Twitter ? A large scale study
Jul 09, 2020



This study analyzes the usage of Japanese gendered language on Twitter. Starting from a collection of 408 million Japanese tweets from 2015 till 2019 and an additional sample of 2355 manually classified Twitter accounts timelines into gender and categories (politicians, musicians, etc). A large scale textual analysis is performed on this corpus to identify and examine sentence-final particles (SFPs) and first-person pronouns appearing in the texts. It turns out that gendered language is in fact used also on Twitter, in about 6% of the tweets, and that the prescriptive classification into "male" and "female" language does not always meet the expectations, with remarkable exceptions. Further, SFPs and pronouns show increasing or decreasing trends, indicating an evolution of the language used on Twitter.
Clustering of discretely observed diffusion processes
Sep 23, 2008



In this paper a new dissimilarity measure to identify groups of assets dynamics is proposed. The underlying generating process is assumed to be a diffusion process solution of stochastic differential equations and observed at discrete time. The mesh of observations is not required to shrink to zero. As distance between two observed paths, the quadratic distance of the corresponding estimated Markov operators is considered. Analysis of both synthetic data and real financial data from NYSE/NASDAQ stocks, give evidence that this distance seems capable to catch differences in both the drift and diffusion coefficients contrary to other commonly used metrics.