 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Topic, Not the Language: How LLMs Classify Online Immigration Discourse Across Languages
Aug 08, 2025



Large language models (LLMs) are transforming social-science research by enabling scalable, precise analysis. Their adaptability raises the question of whether knowledge acquired through fine-tuning in a few languages can transfer to unseen languages that only appeared during pre-training. To examine this, we fine-tune lightweight LLaMA 3.2-3B models on monolingual, bilingual, or multilingual data sets to classify immigration-related tweets from X/Twitter across 13 languages, a domain characterised by polarised, culturally specific discourse. We evaluate whether minimal language-specific fine-tuning enables cross-lingual topic detection and whether adding targeted languages corrects pre-training biases. Results show that LLMs fine-tuned in one or two languages can reliably classify immigration-related content in unseen languages. However, identifying whether a tweet expresses a pro- or anti-immigration stance benefits from multilingual fine-tuning. Pre-training bias favours dominant languages, but even minimal exposure to under-represented languages during fine-tuning (as little as $9.62\times10^{-11}$ of the original pre-training token volume) yields significant gains. These findings challenge the assumption that cross-lingual mastery requires extensive multilingual training: limited language coverage suffices for topic-level generalisation, and structural biases can be corrected with lightweight interventions. By releasing 4-bit-quantised, LoRA fine-tuned models, we provide an open-source, reproducible alternative to proprietary LLMs that delivers 35 times faster inference at just 0.00000989% of the dollar cost of the OpenAI GPT-4o model, enabling scalable, inclusive research.
Assessing Machine Learning Algorithms for Near-Real Time Bus Ridership Prediction During Extreme Weather
Apr 20, 2022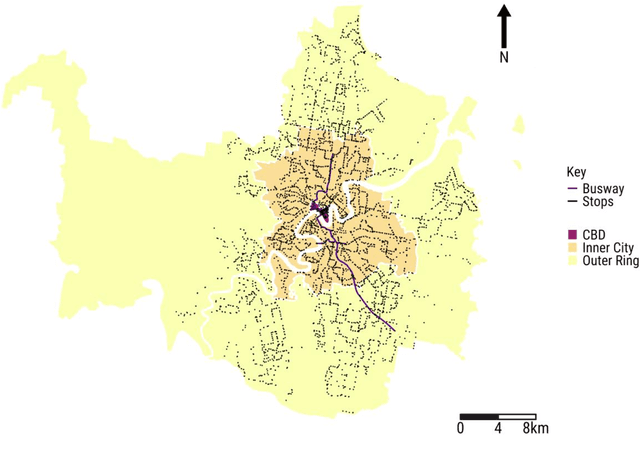
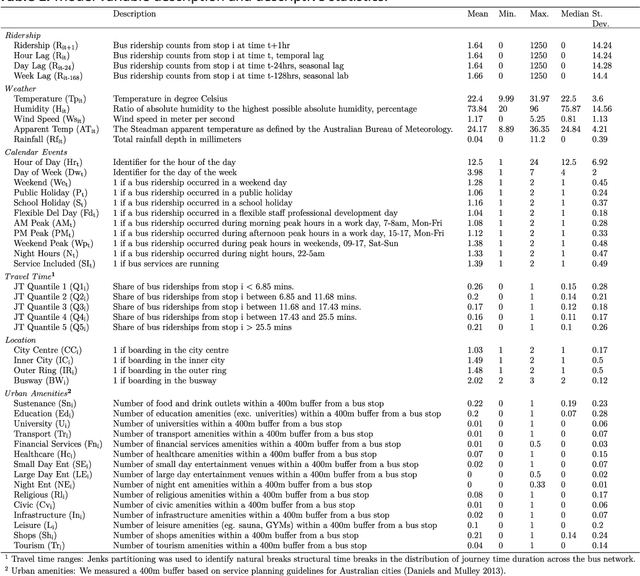
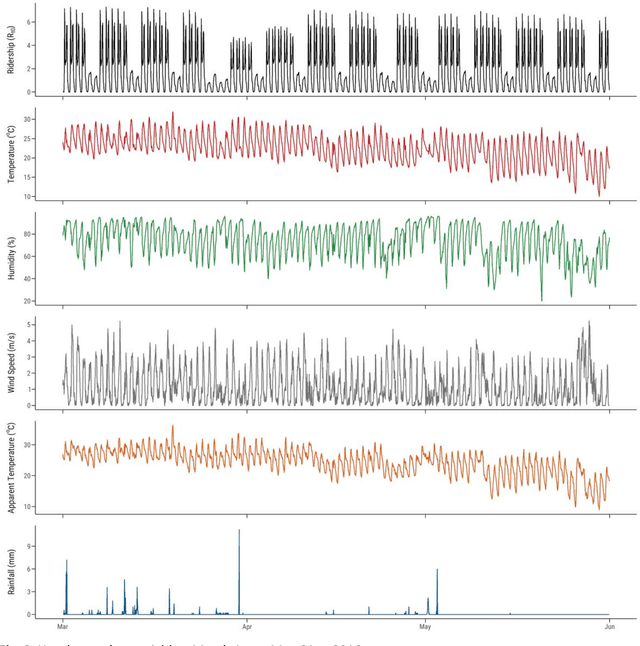
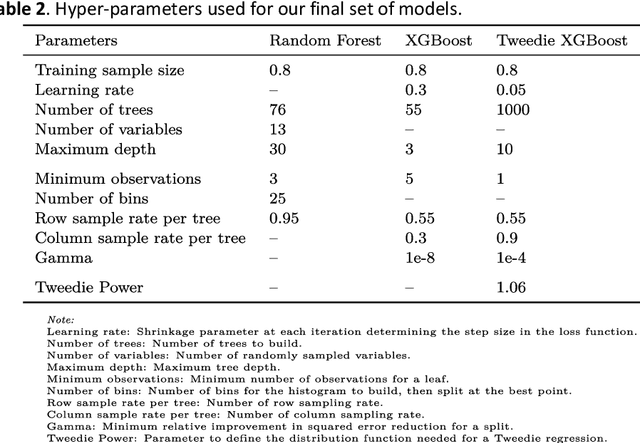
Given an increasingly volatile climate, the relationship between weather and transit ridership has drawn increasing interest. However, challenges stemming from spatio-temporal dependency and non-stationarity have not been fully addressed in modelling and predicting transit ridership under the influence of weather conditions especially with the traditional statistical approaches. Drawing on three-month smart card data in Brisbane, Australia, this research adopts and assesses a suite of machine-learning algorithms, i.e., random forest, eXtreme Gradient Boosting (XGBoost) and Tweedie XGBoost, to model and predict near real-time bus ridership in relation to sudden change of weather conditions. The study confirms that there indeed exists a significant level of spatio-temporal variability of weather-ridership relationship, which produces equally dynamic patterns of prediction errors. Further comparison of model performance suggests that Tweedie XGBoost outperforms the other two machine-learning algorithms in generating overall more accurate prediction outcomes in space and time. Future research may advance the current study by drawing on larger data sets and applying more advanced machine and deep-learning approaches to provide more enhanced evidence for real-time operation of transit systems.