 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Attention (DynAttn): Interpretable High-Dimensional Spatio-Temporal Forecasting (with Application to Conflict Fatalities)
Dec 24, 2025Forecasting conflict-related fatalities remains a central challenge in political science and policy analysis due to the sparse, bursty, and highly non-stationary nature of violence data. We introduce DynAttn, an interpretable dynamic-attention forecasting framework for high-dimensional spatio-temporal count processes. DynAttn combines rolling-window estimation, shared elastic-net feature gating, a compact weight-tied self-attention encoder, and a zero-inflated negative binomial (ZINB) likelihood. This architecture produces calibrated multi-horizon forecasts of expected casualties and exceedance probabilities, while retaining transparent diagnostics through feature gates, ablation analysis, and elasticity measures. We evaluate DynAttn using global country-level and high-resolution PRIO-grid-level conflict data from the VIEWS forecasting system, benchmarking it against established statistical and machine-learning approaches, including DynENet, LSTM, Prophet, PatchTST, and the official VIEWS baseline. Across forecast horizons from one to twelve months, DynAttn consistently achieves substantially higher predictive accuracy, with particularly large gains in sparse grid-level settings where competing models often become unstable or degrade sharply. Beyond predictive performance, DynAttn enables structured interpretation of regional conflict dynamics. In our application, cross-regional analyses show that short-run conflict persistence and spatial diffusion form the core predictive backbone, while climate stress acts either as a conditional amplifier or a primary driver depending on the conflict theater.
The Human Flourishing Geographic Index: A County-Level Dataset for the United States, 2013--2023
Nov 05, 2025



Quantifying human flourishing, a multidimensional construct including happiness, health, purpose, virtue, relationships, and financial stability, is critical for understanding societal well-being beyond economic indicators. Existing measures often lack fine spatial and temporal resolution. Here we introduce the Human Flourishing Geographic Index (HFGI), derived from analyzing approximately 2.6 billion geolocated U.S. tweets (2013-2023) using fine-tuned large language models to classify expressions across 48 indicators aligned with Harvard's Global Flourishing Study framework plus attitudes towards migration and perception of corruption. The dataset offers monthly and yearly county- and state-level indicators of flourishing-related discourse, validated to confirm that the measures accurately represent the underlying constructs and show expected correlations with established indicators. This resource enables multidisciplinary analyses of well-being, inequality, and social change at unprecedented resolution, offering insights into the dynamics of human flourishing as reflected in social media discourse across the United States over the past decade.
Rethinking Scale: The Efficacy of Fine-Tuned Open-Source LLMs in Large-Scale Reproducible Social Science Research
Oct 31, 2024



Large Language Models (LLMs) are distinguished by their architecture, which dictates their parameter size and performance capabilities. Social scientists have increasingly adopted LLMs for text classification tasks, which are difficult to scale with human coders. While very large, closed-source models often deliver superior performance, their use presents significant risks. These include lack of transparency, potential exposure of sensitive data, challenges to replicability, and dependence on proprietary systems. Additionally, their high costs make them impractical for large-scale research projects. In contrast, open-source models, although available in various sizes, may underperform compared to commercial alternatives if used without further fine-tuning. However, open-source models offer distinct advantages: they can be run locally (ensuring data privacy), fine-tuned for specific tasks, shared within the research community, and integrated into reproducible workflows. This study demonstrates that small, fine-tuned open-source LLMs can achieve equal or superior performance to models such as ChatGPT-4. We further explore the relationship between training set size and fine-tuning efficacy in open-source models. Finally, we propose a hybrid workflow that leverages the strengths of both open and closed models, offering a balanced approach to performance, transparency, and reproducibility.
Forecasting asylum applications in the European Union with machine learning and data at scale
Nov 10, 2020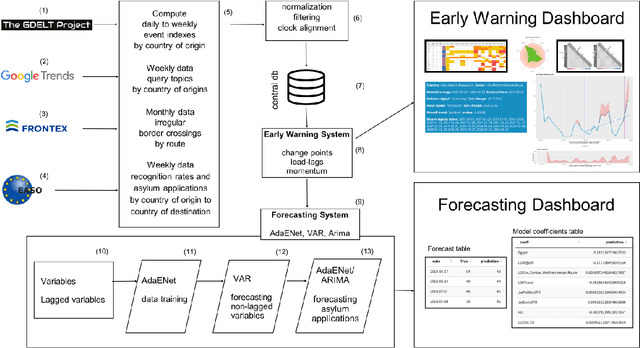
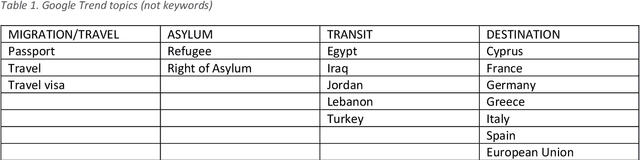
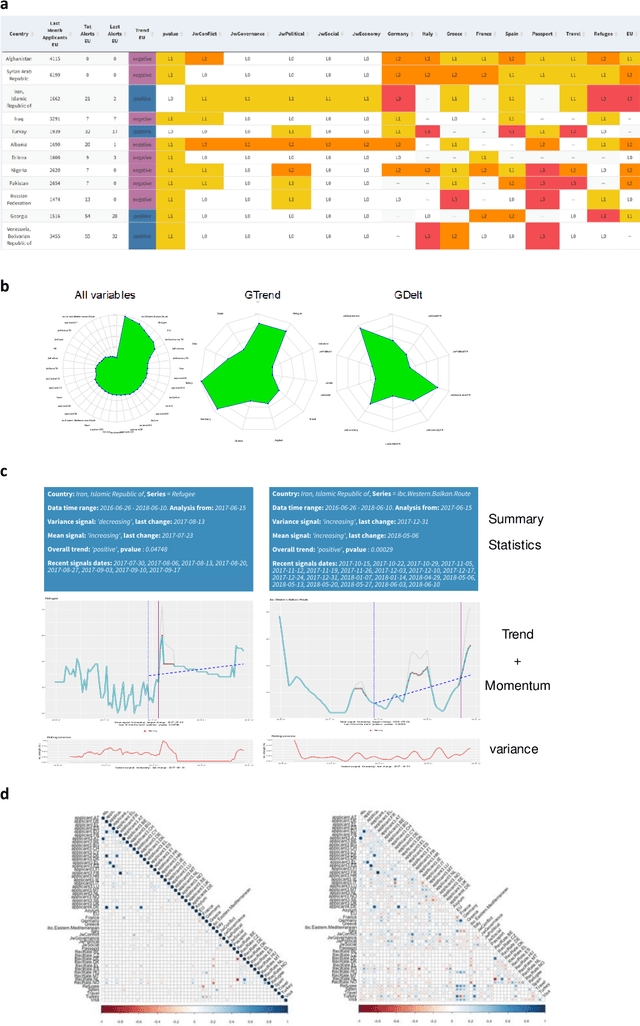
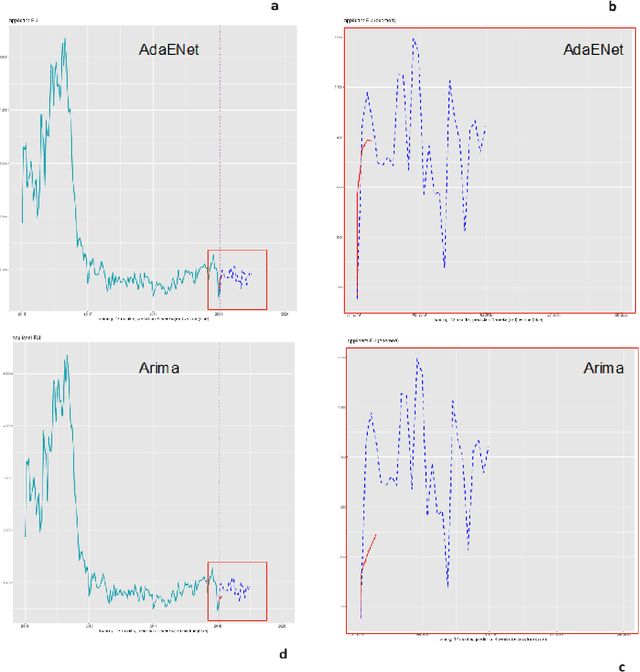
The effects of the so-called "refugee crisis" of 2015-16 continue to dominate much of the European political agenda. Migration flows were sudden and unexpected, exposing significant shortcomings in the field of migration forecasting and leaving governments and NGOs unprepared. Migration is a complex system typified by episodic variation, underpinned by causal factors that are interacting, highly context dependent and short-lived. Correspondingly, migration nowcasts rely on scattered low-quality data and much-needed forecasts are local and inconsistent. Here we describe a data-driven adaptive system for forecasting asylum applications in the European Union (EU), built on machine learning algorithms that combine administrative data with non-traditional data sources at scale. We exploit three tiers of data: geolocated events and internet searches in countries of origin, detections at the EU external border, and asylum recognition rates in the EU, to effectively forecast individual asylum-migration flows up to four weeks ahead with high accuracy. Uniquely our approach a) models individual country-to-country migration flows; b) detects migration drivers early onset; c) anticipates lagged effects; d) estimates the effect of individual drivers; and e) describes how patterns of drivers shift over time. This is, to our knowledge, the first comprehensive system for forecasting asylum applications based on an unsupervised algorithm and data at scale. Importantly, this approach can be extended to forecast other migration social-economic indicators.