 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwitter Subjective Well-Being Indicator During COVID-19 Pandemic: A Cross-Country Comparative Study
Jan 19, 2021
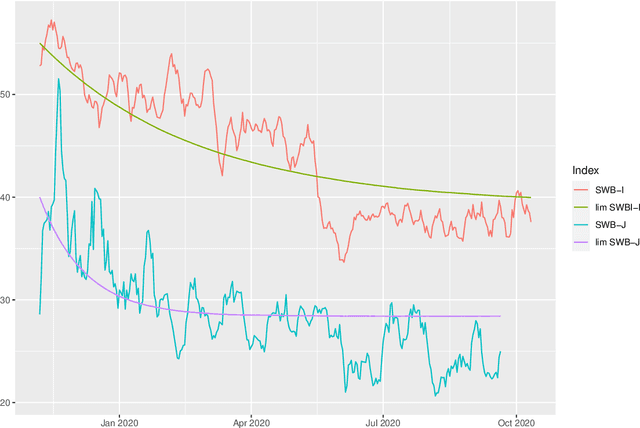
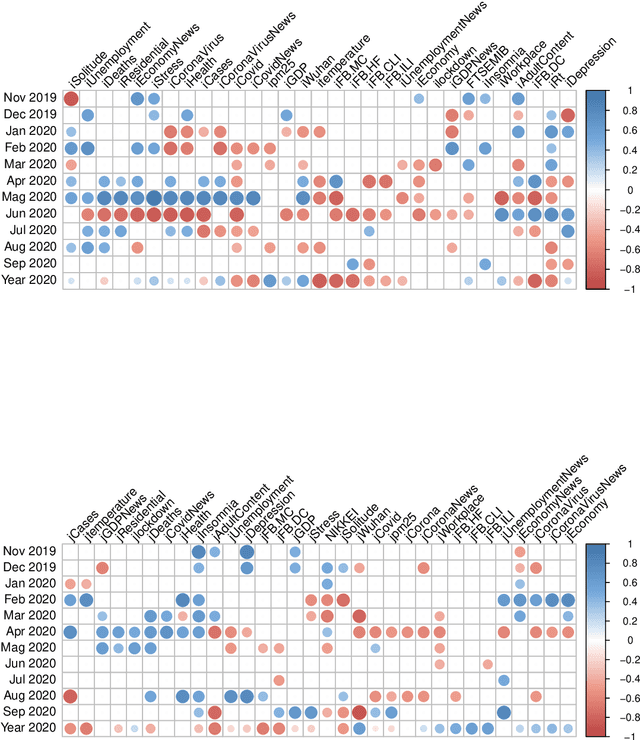

This study analyzes the impact of the COVID-19 pandemic on the subjective well-being as measured through Twitter data indicators for Japan and Italy. It turns out that, overall, the subjective well-being dropped by 11.7% for Italy and 8.3% for Japan in the first nine months of 2020 compared to the last two months of 2019 and even more compared to the historical mean of the indexes. Through a data science approach we try to identify the possible causes of this drop down by considering several explanatory variables including, climate and air quality data, number of COVID-19 cases and deaths, Facebook Covid and flu symptoms global survey, Google Trends data and coronavirus-related searches, Google mobility data, policy intervention measures, economic variables and their Google Trends proxies, as well as health and stress proxy variables based on big data. We show that a simple static regression model is not able to capture the complexity of well-being and therefore we propose a dynamic elastic net approach to show how different group of factors may impact the well-being in different periods, even over a short time length, and showing further country-specific aspects. Finally, a structural equation modeling analysis tries to address the causal relationships among the COVID-19 factors and subjective well-being showing that, overall, prolonged mobility restrictions,flu and Covid-like symptoms, economic uncertainty, social distancing and news about the pandemic have negative effects on the subjective well-being.
Is Japanese gendered language used on Twitter ? A large scale study
Jul 09, 2020



This study analyzes the usage of Japanese gendered language on Twitter. Starting from a collection of 408 million Japanese tweets from 2015 till 2019 and an additional sample of 2355 manually classified Twitter accounts timelines into gender and categories (politicians, musicians, etc). A large scale textual analysis is performed on this corpus to identify and examine sentence-final particles (SFPs) and first-person pronouns appearing in the texts. It turns out that gendered language is in fact used also on Twitter, in about 6% of the tweets, and that the prescriptive classification into "male" and "female" language does not always meet the expectations, with remarkable exceptions. Further, SFPs and pronouns show increasing or decreasing trends, indicating an evolution of the language used on Twitter.