 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Americas of Well-Being: Divergent Rural-Urban Patterns of Life Satisfaction and Happiness from 2.6 B Social Media Posts
Nov 13, 2025Using 2.6 billion geolocated social-media posts (2014-2022) and a fine-tuned generative language model, we construct county-level indicators of life satisfaction and happiness for the United States. We document an apparent rural-urban paradox: rural counties express higher life satisfaction while urban counties exhibit greater happiness. We reconcile this by treating the two as distinct layers of subjective well-being, evaluative vs. hedonic, showing that each maps differently onto place, politics, and time. Republican-leaning areas appear more satisfied in evaluative terms, but partisan gaps in happiness largely flatten outside major metros, indicating context-dependent political effects. Temporal shocks dominate the hedonic layer: happiness falls sharply during 2020-2022, whereas life satisfaction moves more modestly. These patterns are robust across logistic and OLS specifications and align with well-being theory. Interpreted as associations for the population of social-media posts, the results show that large-scale, language-based indicators can resolve conflicting findings about the rural-urban divide by distinguishing the type of well-being expressed, offering a transparent, reproducible complement to traditional surveys.
The Human Flourishing Geographic Index: A County-Level Dataset for the United States, 2013--2023
Nov 05, 2025



Quantifying human flourishing, a multidimensional construct including happiness, health, purpose, virtue, relationships, and financial stability, is critical for understanding societal well-being beyond economic indicators. Existing measures often lack fine spatial and temporal resolution. Here we introduce the Human Flourishing Geographic Index (HFGI), derived from analyzing approximately 2.6 billion geolocated U.S. tweets (2013-2023) using fine-tuned large language models to classify expressions across 48 indicators aligned with Harvard's Global Flourishing Study framework plus attitudes towards migration and perception of corruption. The dataset offers monthly and yearly county- and state-level indicators of flourishing-related discourse, validated to confirm that the measures accurately represent the underlying constructs and show expected correlations with established indicators. This resource enables multidisciplinary analyses of well-being, inequality, and social change at unprecedented resolution, offering insights into the dynamics of human flourishing as reflected in social media discourse across the United States over the past decade.
Rethinking Scale: The Efficacy of Fine-Tuned Open-Source LLMs in Large-Scale Reproducible Social Science Research
Oct 31, 2024



Large Language Models (LLMs) are distinguished by their architecture, which dictates their parameter size and performance capabilities. Social scientists have increasingly adopted LLMs for text classification tasks, which are difficult to scale with human coders. While very large, closed-source models often deliver superior performance, their use presents significant risks. These include lack of transparency, potential exposure of sensitive data, challenges to replicability, and dependence on proprietary systems. Additionally, their high costs make them impractical for large-scale research projects. In contrast, open-source models, although available in various sizes, may underperform compared to commercial alternatives if used without further fine-tuning. However, open-source models offer distinct advantages: they can be run locally (ensuring data privacy), fine-tuned for specific tasks, shared within the research community, and integrated into reproducible workflows. This study demonstrates that small, fine-tuned open-source LLMs can achieve equal or superior performance to models such as ChatGPT-4. We further explore the relationship between training set size and fine-tuning efficacy in open-source models. Finally, we propose a hybrid workflow that leverages the strengths of both open and closed models, offering a balanced approach to performance, transparency, and reproducibility.
Twitter Subjective Well-Being Indicator During COVID-19 Pandemic: A Cross-Country Comparative Study
Jan 19, 2021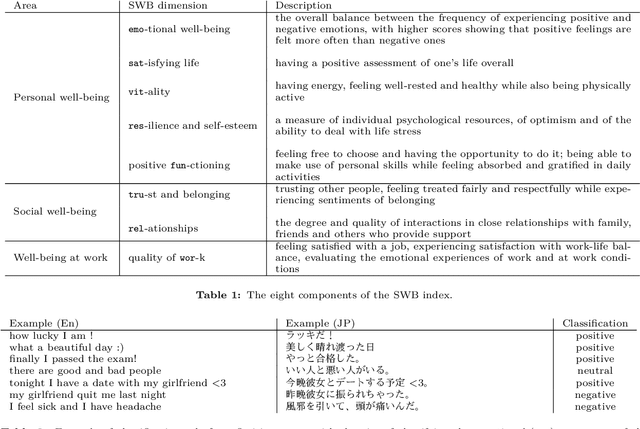
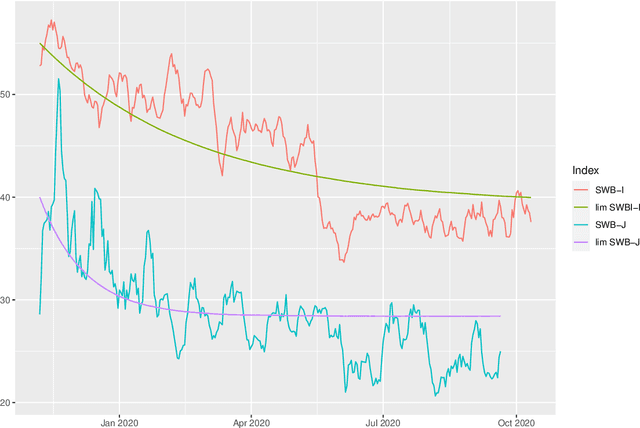
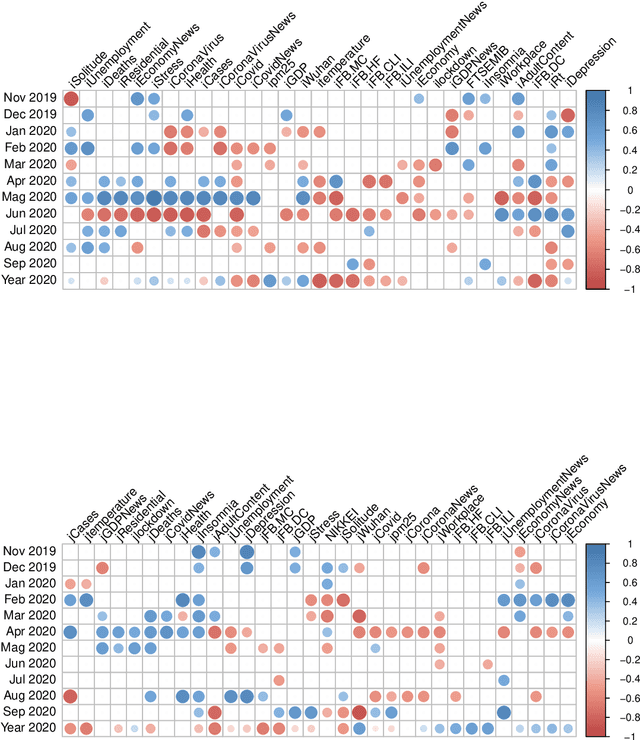

This study analyzes the impact of the COVID-19 pandemic on the subjective well-being as measured through Twitter data indicators for Japan and Italy. It turns out that, overall, the subjective well-being dropped by 11.7% for Italy and 8.3% for Japan in the first nine months of 2020 compared to the last two months of 2019 and even more compared to the historical mean of the indexes. Through a data science approach we try to identify the possible causes of this drop down by considering several explanatory variables including, climate and air quality data, number of COVID-19 cases and deaths, Facebook Covid and flu symptoms global survey, Google Trends data and coronavirus-related searches, Google mobility data, policy intervention measures, economic variables and their Google Trends proxies, as well as health and stress proxy variables based on big data. We show that a simple static regression model is not able to capture the complexity of well-being and therefore we propose a dynamic elastic net approach to show how different group of factors may impact the well-being in different periods, even over a short time length, and showing further country-specific aspects. Finally, a structural equation modeling analysis tries to address the causal relationships among the COVID-19 factors and subjective well-being showing that, overall, prolonged mobility restrictions,flu and Covid-like symptoms, economic uncertainty, social distancing and news about the pandemic have negative effects on the subjective well-being.