 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Vision-Language Models via Biased Prompts
Jan 31, 2023



Machine learning models have been shown to inherit biases from their training datasets, which can be particularly problematic for vision-language foundation models trained on uncurated datasets scraped from the internet. The biases can be amplified and propagated to downstream applications like zero-shot classifiers and text-to-image generative models. In this study, we propose a general approach for debiasing vision-language foundation models by projecting out biased directions in the text embedding. In particular, we show that debiasing only the text embedding with a calibrated projection matrix suffices to yield robust classifiers and fair generative models. The closed-form solution enables easy integration into large-scale pipelines, and empirical results demonstrate that our approach effectively reduces social bias and spurious correlation in both discriminative and generative vision-language models without the need for additional data or training.
Efficiently predicting high resolution mass spectra with graph neural networks
Jan 26, 2023



Identifying a small molecule from its mass spectrum is the primary open problem in computational metabolomics. This is typically cast as information retrieval: an unknown spectrum is matched against spectra predicted computationally from a large database of chemical structures. However, current approaches to spectrum prediction model the output space in ways that force a tradeoff between capturing high resolution mass information and tractable learning. We resolve this tradeoff by casting spectrum prediction as a mapping from an input molecular graph to a probability distribution over molecular formulas. We discover that a large corpus of mass spectra can be closely approximated using a fixed vocabulary constituting only 2% of all observed formulas. This enables efficient spectrum prediction using an architecture similar to graph classification - GrAFF-MS - achieving significantly lower prediction error and orders-of-magnitude faster runtime than state-of-the-art methods.
Optimal algorithms for group distributionally robust optimization and beyond
Dec 28, 2022



Distributionally robust optimization (DRO) can improve the robustness and fairness of learning methods. In this paper, we devise stochastic algorithms for a class of DRO problems including group DRO, subpopulation fairness, and empirical conditional value at risk (CVaR) optimization. Our new algorithms achieve faster convergence rates than existing algorithms for multiple DRO settings. We also provide a new information-theoretic lower bound that implies our bounds are tight for group DRO. Empirically, too, our algorithms outperform known methods
InfoOT: Information Maximizing Optimal Transport
Oct 06, 2022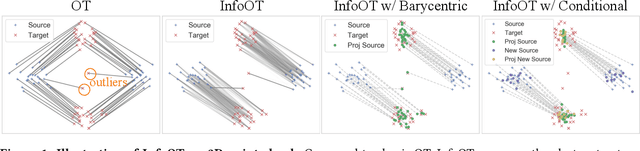
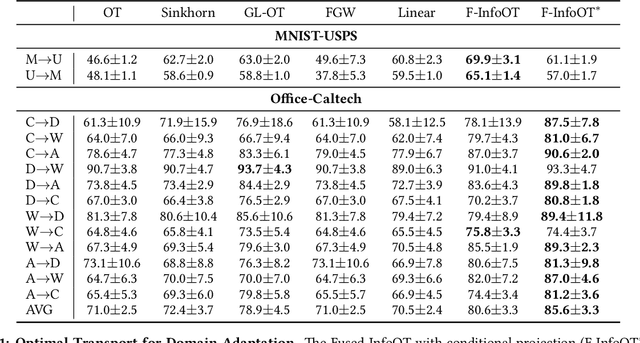
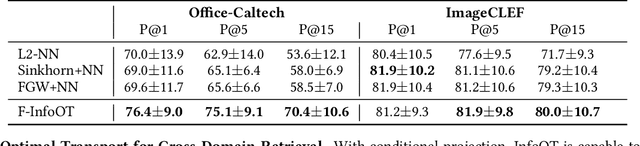
Optimal transport aligns samples across distributions by minimizing the transportation cost between them, e.g., the geometric distances. Yet, it ignores coherence structure in the data such as clusters, does not handle outliers well, and cannot integrate new data points. To address these drawbacks, we propose InfoOT, an information-theoretic extension of optimal transport that maximizes the mutual information between domains while minimizing geometric distances. The resulting objective can still be formulated as a (generalized) optimal transport problem, and can be efficiently solved by projected gradient descent. This formulation yields a new projection method that is robust to outliers and generalizes to unseen samples. Empirically, InfoOT improves the quality of alignments across benchmarks in domain adaptation, cross-domain retrieval, and single-cell alignment.
Tree Mover's Distance: Bridging Graph Metrics and Stability of Graph Neural Networks
Oct 04, 2022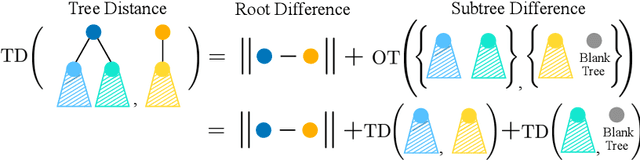
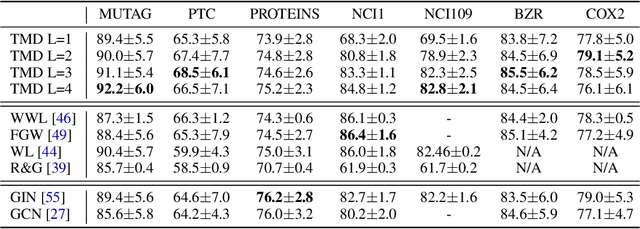

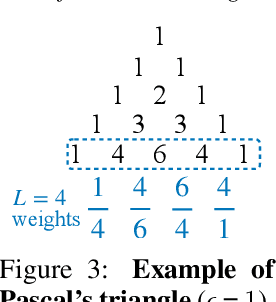
Understanding generalization and robustness of machine learning models fundamentally relies on assuming an appropriate metric on the data space. Identifying such a metric is particularly challenging for non-Euclidean data such as graphs. Here, we propose a pseudometric for attributed graphs, the Tree Mover's Distance (TMD), and study its relation to generalization. Via a hierarchical optimal transport problem, TMD reflects the local distribution of node attributes as well as the distribution of local computation trees, which are known to be decisive for the learning behavior of graph neural networks (GNNs). First, we show that TMD captures properties relevant to graph classification: a simple TMD-SVM performs competitively with standard GNNs. Second, we relate TMD to generalization of GNNs under distribution shifts, and show that it correlates well with performance drop under such shifts.
On the generalization of learning algorithms that do not converge
Aug 19, 2022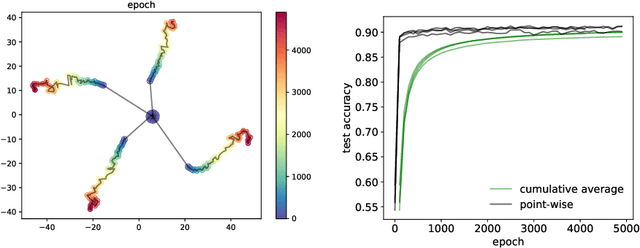
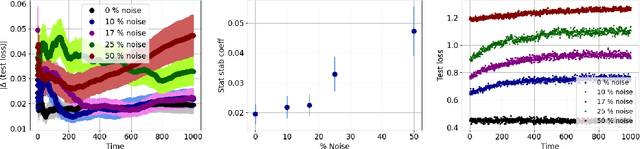
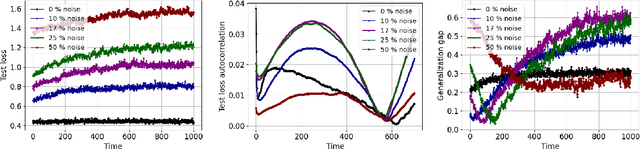
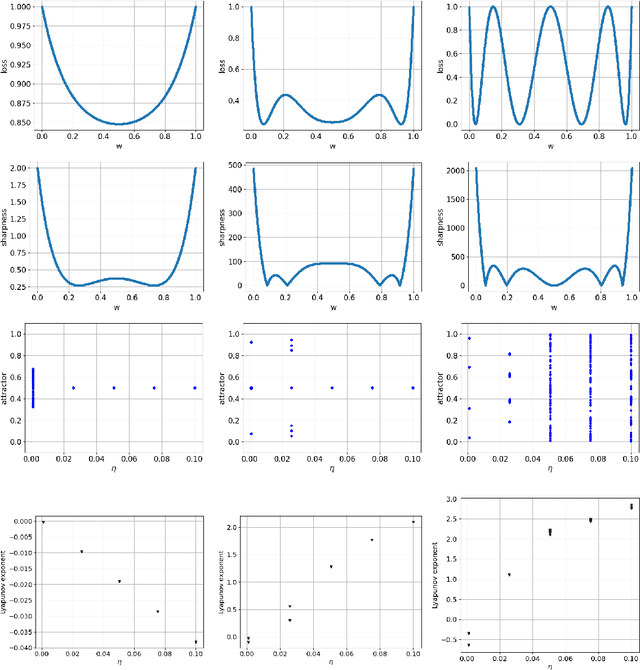
Generalization analyses of deep learning typically assume that the training converges to a fixed point. But, recent results indicate that in practice, the weights of deep neural networks optimized with stochastic gradient descent often oscillate indefinitely. To reduce this discrepancy between theory and practice, this paper focuses on the generalization of neural networks whose training dynamics do not necessarily converge to fixed points. Our main contribution is to propose a notion of statistical algorithmic stability (SAS) that extends classical algorithmic stability to non-convergent algorithms and to study its connection to generalization. This ergodic-theoretic approach leads to new insights when compared to the traditional optimization and learning theory perspectives. We prove that the stability of the time-asymptotic behavior of a learning algorithm relates to its generalization and empirically demonstrate how loss dynamics can provide clues to generalization performance. Our findings provide evidence that networks that "train stably generalize better" even when the training continues indefinitely and the weights do not converge.
Neural Set Function Extensions: Learning with Discrete Functions in High Dimensions
Aug 08, 2022
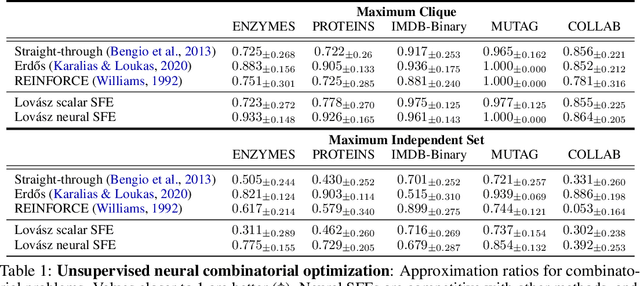


Integrating functions on discrete domains into neural networks is key to developing their capability to reason about discrete objects. But, discrete domains are (1) not naturally amenable to gradient-based optimization, and (2) incompatible with deep learning architectures that rely on representations in high-dimensional vector spaces. In this work, we address both difficulties for set functions, which capture many important discrete problems. First, we develop a framework for extending set functions onto low-dimensional continuous domains, where many extensions are naturally defined. Our framework subsumes many well-known extensions as special cases. Second, to avoid undesirable low-dimensional neural network bottlenecks, we convert low-dimensional extensions into representations in high-dimensional spaces, taking inspiration from the success of semidefinite programs for combinatorial optimization. Empirically, we observe benefits of our extensions for unsupervised neural combinatorial optimization, in particular with high-dimensional representations.
Theory of Graph Neural Networks: Representation and Learning
Apr 16, 2022
Graph Neural Networks (GNNs), neural network architectures targeted to learning representations of graphs, have become a popular learning model for prediction tasks on nodes, graphs and configurations of points, with wide success in practice. This article summarizes a selection of the emerging theoretical results on approximation and learning properties of widely used message passing GNNs and higher-order GNNs, focusing on representation, generalization and extrapolation. Along the way, it summarizes mathematical connections.
Sign and Basis Invariant Networks for Spectral Graph Representation Learning
Apr 11, 2022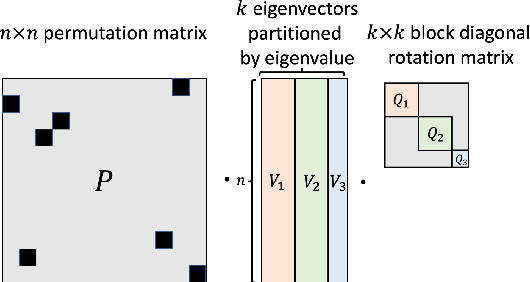
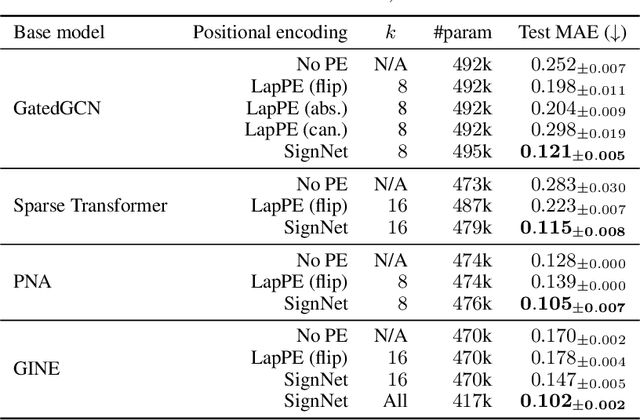

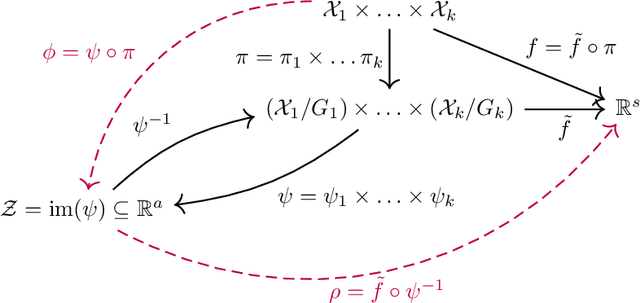
Many machine learning tasks involve processing eigenvectors derived from data. Especially valuable are Laplacian eigenvectors, which capture useful structural information about graphs and other geometric objects. However, ambiguities arise when computing eigenvectors: for each eigenvector $v$, the sign flipped $-v$ is also an eigenvector. More generally, higher dimensional eigenspaces contain infinitely many choices of basis eigenvectors. These ambiguities make it a challenge to process eigenvectors and eigenspaces in a consistent way. In this work we introduce SignNet and BasisNet -- new neural architectures that are invariant to all requisite symmetries and hence process collections of eigenspaces in a principled manner. Our networks are universal, i.e., they can approximate any continuous function of eigenvectors with the proper invariances. They are also theoretically strong for graph representation learning -- they can approximate any spectral graph convolution, can compute spectral invariants that go beyond message passing neural networks, and can provably simulate previously proposed graph positional encodings. Experiments show the strength of our networks for molecular graph regression, learning expressive graph representations, and learning implicit neural representations on triangle meshes. Our code is available at https://github.com/cptq/SignNet-BasisNet .
Training invariances and the low-rank phenomenon: beyond linear networks
Jan 28, 2022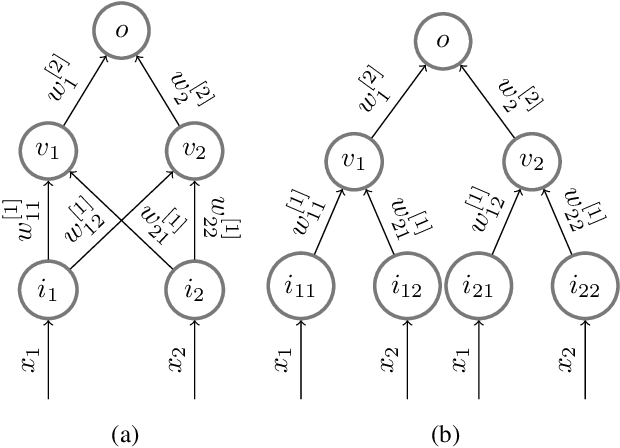
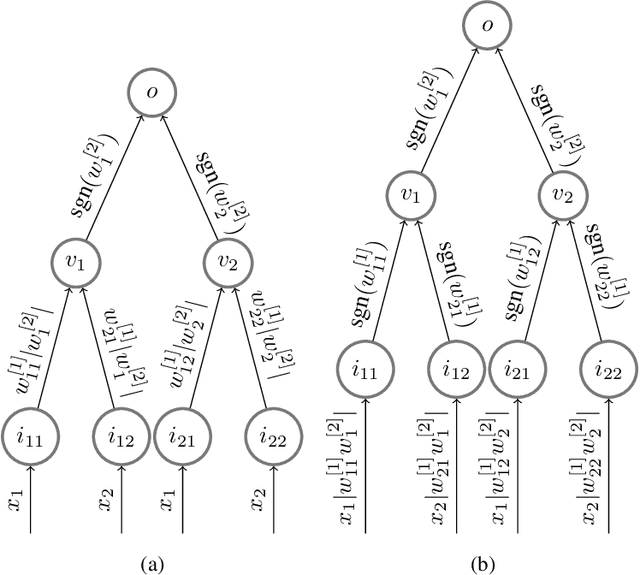
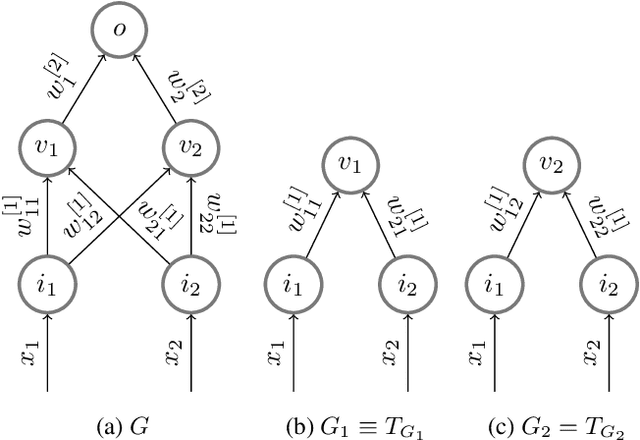
The implicit bias induced by the training of neural networks has become a topic of rigorous study. In the limit of gradient flow and gradient descent with appropriate step size, it has been shown that when one trains a deep linear network with logistic or exponential loss on linearly separable data, the weights converge to rank-$1$ matrices. In this paper, we extend this theoretical result to the much wider class of nonlinear ReLU-activated feedforward networks containing fully-connected layers and skip connections. To the best of our knowledge, this is the first time a low-rank phenomenon is proven rigorously for these architectures, and it reflects empirical results in the literature. The proof relies on specific local training invariances, sometimes referred to as alignment, which we show to hold for a wide set of ReLU architectures. Our proof relies on a specific decomposition of the network into a multilinear function and another ReLU network whose weights are constant under a certain parameter directional convergence.