 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Detection of Lead-Lag Relationships in Lagged Multi-Factor Models
May 11, 2023



In multivariate time series systems, key insights can be obtained by discovering lead-lag relationships inherent in the data, which refer to the dependence between two time series shifted in time relative to one another, and which can be leveraged for the purposes of control, forecasting or clustering. We develop a clustering-driven methodology for the robust detection of lead-lag relationships in lagged multi-factor models. Within our framework, the envisioned pipeline takes as input a set of time series, and creates an enlarged universe of extracted subsequence time series from each input time series, by using a sliding window approach. We then apply various clustering techniques (e.g, K-means++ and spectral clustering), employing a variety of pairwise similarity measures, including nonlinear ones. Once the clusters have been extracted, lead-lag estimates across clusters are aggregated to enhance the identification of the consistent relationships in the original universe. Since multivariate time series are ubiquitous in a wide range of domains, we demonstrate that our method is not only able to robustly detect lead-lag relationships in financial markets, but can also yield insightful results when applied to an environmental data set.
Spatio-Temporal Momentum: Jointly Learning Time-Series and Cross-Sectional Strategies
Feb 20, 2023



We introduce Spatio-Temporal Momentum strategies, a class of models that unify both time-series and cross-sectional momentum strategies by trading assets based on their cross-sectional momentum features over time. While both time-series and cross-sectional momentum strategies are designed to systematically capture momentum risk premia, these strategies are regarded as distinct implementations and do not consider the concurrent relationship and predictability between temporal and cross-sectional momentum features of different assets. We model spatio-temporal momentum with neural networks of varying complexities and demonstrate that a simple neural network with only a single fully connected layer learns to simultaneously generate trading signals for all assets in a portfolio by incorporating both their time-series and cross-sectional momentum features. Backtesting on portfolios of 46 actively-traded US equities and 12 equity index futures contracts, we demonstrate that the model is able to retain its performance over benchmarks in the presence of high transaction costs of up to 5-10 basis points. In particular, we find that the model when coupled with least absolute shrinkage and turnover regularization results in the best performance over various transaction cost scenarios.
Asynchronous Deep Double Duelling Q-Learning for Trading-Signal Execution in Limit Order Book Markets
Jan 20, 2023



We employ deep reinforcement learning (RL) to train an agent to successfully translate a high-frequency trading signal into a trading strategy that places individual limit orders. Based on the ABIDES limit order book simulator, we build a reinforcement learning OpenAI gym environment and utilise it to simulate a realistic trading environment for NASDAQ equities based on historic order book messages. To train a trading agent that learns to maximise its trading return in this environment, we use Deep Duelling Double Q-learning with the APEX (asynchronous prioritised experience replay) architecture. The agent observes the current limit order book state, its recent history, and a short-term directional forecast. To investigate the performance of RL for adaptive trading independently from a concrete forecasting algorithm, we study the performance of our approach utilising synthetic alpha signals obtained by perturbing forward-looking returns with varying levels of noise. Here, we find that the RL agent learns an effective trading strategy for inventory management and order placing that outperforms a heuristic benchmark trading strategy having access to the same signal.
On Sequential Bayesian Inference for Continual Learning
Jan 04, 2023



Sequential Bayesian inference can be used for continual learning to prevent catastrophic forgetting of past tasks and provide an informative prior when learning new tasks. We revisit sequential Bayesian inference and test whether having access to the true posterior is guaranteed to prevent catastrophic forgetting in Bayesian neural networks. To do this we perform sequential Bayesian inference using Hamiltonian Monte Carlo. We propagate the posterior as a prior for new tasks by fitting a density estimator on Hamiltonian Monte Carlo samples. We find that this approach fails to prevent catastrophic forgetting demonstrating the difficulty in performing sequential Bayesian inference in neural networks. From there we study simple analytical examples of sequential Bayesian inference and CL and highlight the issue of model misspecification which can lead to sub-optimal continual learning performance despite exact inference. Furthermore, we discuss how task data imbalances can cause forgetting. From these limitations, we argue that we need probabilistic models of the continual learning generative process rather than relying on sequential Bayesian inference over Bayesian neural network weights. In this vein, we also propose a simple baseline called Prototypical Bayesian Continual Learning, which is competitive with state-of-the-art Bayesian continual learning methods on class incremental continual learning vision benchmarks.
DeepVol: Volatility Forecasting from High-Frequency Data with Dilated Causal Convolutions
Sep 23, 2022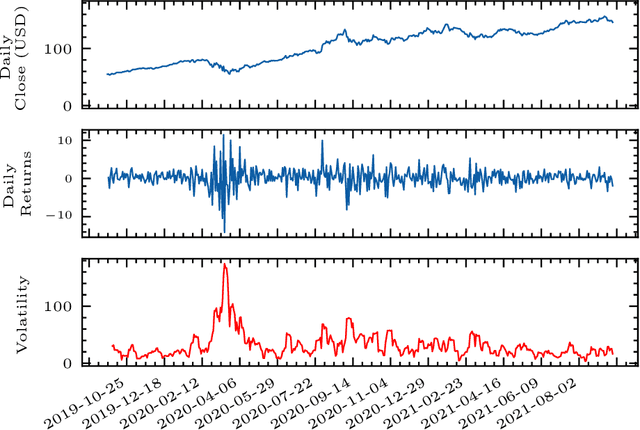
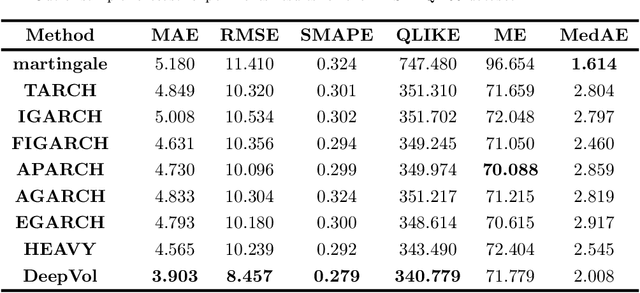
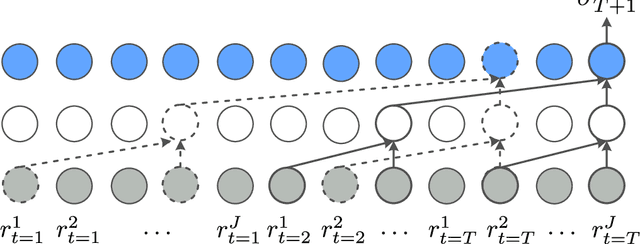
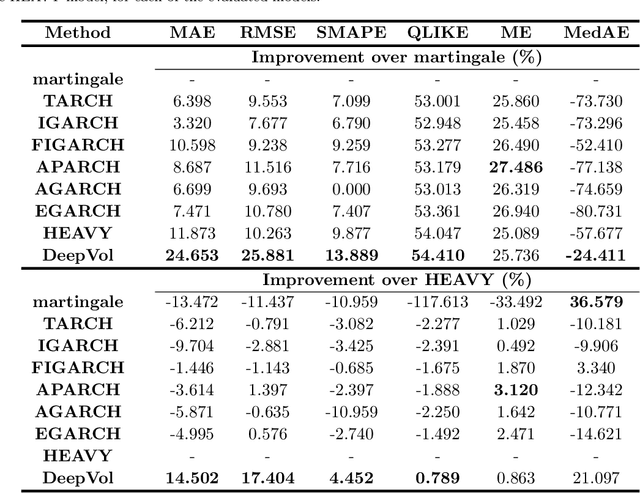
Volatility forecasts play a central role among equity risk measures. Besides traditional statistical models, modern forecasting techniques, based on machine learning, can readily be employed when treating volatility as a univariate, daily time-series. However, econometric studies have shown that increasing the number of daily observations with high-frequency intraday data helps to improve predictions. In this work, we propose DeepVol, a model based on Dilated Causal Convolutions to forecast day-ahead volatility by using high-frequency data. We show that the dilated convolutional filters are ideally suited to extract relevant information from intraday financial data, thereby naturally mimicking (via a data-driven approach) the econometric models which incorporate realised measures of volatility into the forecast. This allows us to take advantage of the abundance of intraday observations, helping us to avoid the limitations of models that use daily data, such as model misspecification or manually designed handcrafted features, whose devise involves optimising the trade-off between accuracy and computational efficiency and makes models prone to lack of adaptation into changing circumstances. In our analysis, we use two years of intraday data from NASDAQ-100 to evaluate DeepVol's performance. The reported empirical results suggest that the proposed deep learning-based approach learns global features from high-frequency data, achieving more accurate predictions than traditional methodologies, yielding to more appropriate risk measures.
Transfer Ranking in Finance: Applications to Cross-Sectional Momentum with Data Scarcity
Aug 24, 2022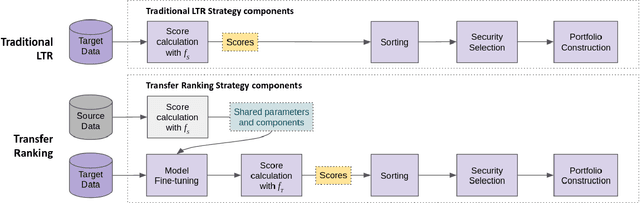
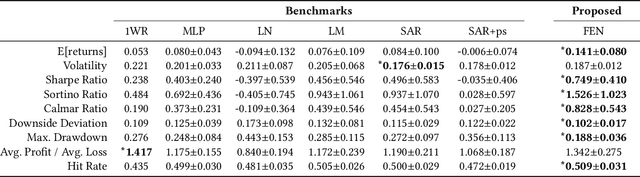
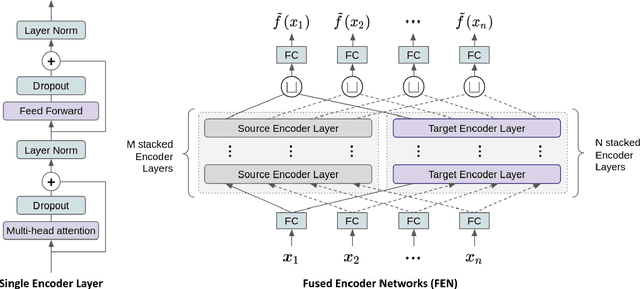
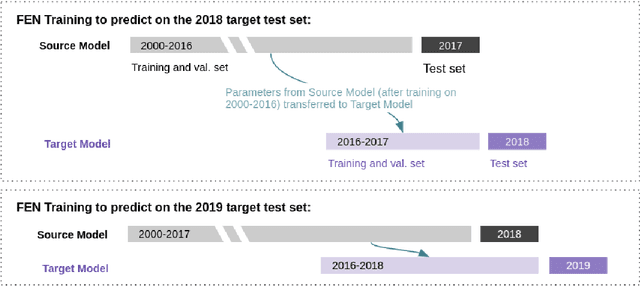
Cross-sectional strategies are a classical and popular trading style, with recent high performing variants incorporating sophisticated neural architectures. While these strategies have been applied successfully to data-rich settings involving mature assets with long histories, deploying them on instruments with limited samples generally produce over-fitted models with degraded performance. In this paper, we introduce Fused Encoder Networks -- a novel and hybrid parameter-sharing transfer ranking model. The model fuses information extracted using an encoder-attention module operated on a source dataset with a similar but separate module focused on a smaller target dataset of interest. This mitigates the issue of models with poor generalisability that are a consequence of training on scarce target data. Additionally, the self-attention mechanism enables interactions among instruments to be accounted for, not just at the loss level during model training, but also at inference time. Focusing on momentum applied to the top ten cryptocurrencies by market capitalisation as a demonstrative use-case, the Fused Encoder Networks outperforms the reference benchmarks on most performance measures, delivering a three-fold boost in the Sharpe ratio over classical momentum as well as an improvement of approximately 50% against the best benchmark model without transaction costs. It continues outperforming baselines even after accounting for the high transaction costs associated with trading cryptocurrencies.
Forecasting COVID-19 Caseloads Using Unsupervised Embedding Clusters of Social Media Posts
May 20, 2022
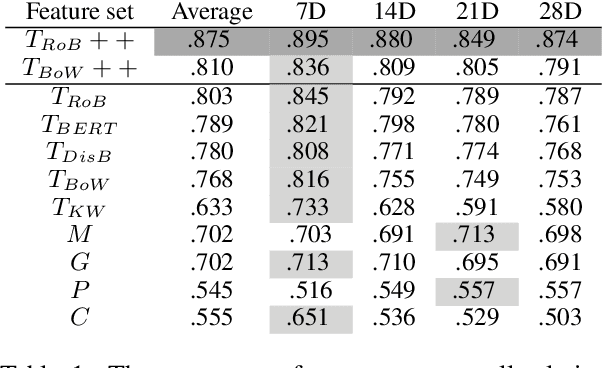
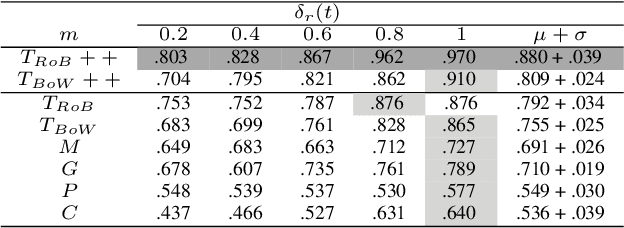
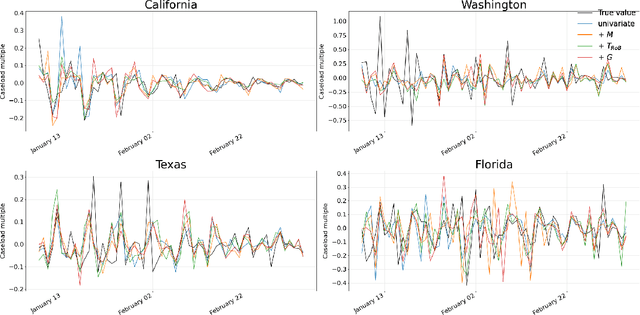
We present a novel approach incorporating transformer-based language models into infectious disease modelling. Text-derived features are quantified by tracking high-density clusters of sentence-level representations of Reddit posts within specific US states' COVID-19 subreddits. We benchmark these clustered embedding features against features extracted from other high-quality datasets. In a threshold-classification task, we show that they outperform all other feature types at predicting upward trend signals, a significant result for infectious disease modelling in areas where epidemiological data is unreliable. Subsequently, in a time-series forecasting task we fully utilise the predictive power of the caseload and compare the relative strengths of using different supplementary datasets as covariate feature sets in a transformer-based time-series model.
Trading with the Momentum Transformer: An Intelligent and Interpretable Architecture
Dec 16, 2021Deep learning architectures, specifically Deep Momentum Networks (DMNs) [1904.04912], have been found to be an effective approach to momentum and mean-reversion trading. However, some of the key challenges in recent years involve learning long-term dependencies, degradation of performance when considering returns net of transaction costs and adapting to new market regimes, notably during the SARS-CoV-2 crisis. Attention mechanisms, or Transformer-based architectures, are a solution to such challenges because they allow the network to focus on significant time steps in the past and longer-term patterns. We introduce the Momentum Transformer, an attention-based architecture which outperforms the benchmarks, and is inherently interpretable, providing us with greater insights into our deep learning trading strategy. Our model is an extension to the LSTM-based DMN, which directly outputs position sizing by optimising the network on a risk-adjusted performance metric, such as Sharpe ratio. We find an attention-LSTM hybrid Decoder-Only Temporal Fusion Transformer (TFT) style architecture is the best performing model. In terms of interpretability, we observe remarkable structure in the attention patterns, with significant peaks of importance at momentum turning points. The time series is thus segmented into regimes and the model tends to focus on previous time-steps in alike regimes. We find changepoint detection (CPD) [2105.13727], another technique for responding to regime change, can complement multi-headed attention, especially when we run CPD at multiple timescales. Through the addition of an interpretable variable selection network, we observe how CPD helps our model to move away from trading predominantly on daily returns data. We note that the model can intelligently switch between, and blend, classical strategies - basing its decision on patterns in the data.
Realised Volatility Forecasting: Machine Learning via Financial Word Embedding
Aug 01, 2021We develop FinText, a novel, state-of-the-art, financial word embedding from Dow Jones Newswires Text News Feed Database. Incorporating this word embedding in a machine learning model produces a substantial increase in volatility forecasting performance on days with volatility jumps for 23 NASDAQ stocks from 27 July 2007 to 18 November 2016. A simple ensemble model, combining our word embedding and another machine learning model that uses limit order book data, provides the best forecasting performance for both normal and jump volatility days. Finally, we use Integrated Gradients and SHAP (SHapley Additive exPlanations) to make the results more 'explainable' and the model comparisons more transparent.
Slow Momentum with Fast Reversion: A Trading Strategy Using Deep Learning and Changepoint Detection
Jun 18, 2021Momentum strategies are an important part of alternative investments and are at the heart of commodity trading advisors (CTAs). These strategies have however been found to have difficulties adjusting to rapid changes in market conditions, such as during the 2020 market crash. In particular, immediately after momentum turning points, where a trend reverses from an uptrend (downtrend) to a downtrend (uptrend), time-series momentum (TSMOM) strategies are prone to making bad bets. To improve the response to regime change, we introduce a novel approach, where we insert an online change-point detection (CPD) module into a Deep Momentum Network (DMN) [1904.04912] pipeline, which uses an LSTM deep-learning architecture to simultaneously learn both trend estimation and position sizing. Furthermore, our model is able to optimise the way in which it balances 1) a slow momentum strategy which exploits persisting trends, but does not overreact to localised price moves, and 2) a fast mean-reversion strategy regime by quickly flipping its position, then swapping it back again to exploit localised price moves. Our CPD module outputs a changepoint location and severity score, allowing our model to learn to respond to varying degrees of disequilibrium, or smaller and more localised changepoints, in a data driven manner. Using a portfolio of 50, liquid, continuous futures contracts over the period 1990-2020, the addition of the CPD module leads to an improvement in Sharpe ratio of one-third. Even more notably, this module is especially beneficial in periods of significant nonstationarity, and in particular, over the most recent years tested (2015-2020) the performance boost is approximately two-thirds. This is especially interesting as traditional momentum strategies have been underperforming in this period.