 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Evaluation of Spoken vs. Visual Explanations for Open-Domain QA
Dec 30, 2020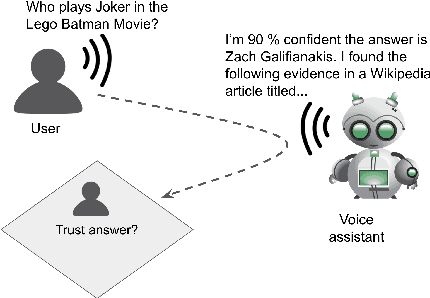


While research on explaining predictions of open-domain QA systems (ODQA) to users is gaining momentum, most works have failed to evaluate the extent to which explanations improve user trust. While few works evaluate explanations using user studies, they employ settings that may deviate from the end-user's usage in-the-wild: ODQA is most ubiquitous in voice-assistants, yet current research only evaluates explanations using a visual display, and may erroneously extrapolate conclusions about the most performant explanations to other modalities. To alleviate these issues, we conduct user studies that measure whether explanations help users correctly decide when to accept or reject an ODQA system's answer. Unlike prior work, we control for explanation modality, e.g., whether they are communicated to users through a spoken or visual interface, and contrast effectiveness across modalities. Our results show that explanations derived from retrieved evidence passages can outperform strong baselines (calibrated confidence) across modalities but the best explanation strategy in fact changes with the modality. We show common failure cases of current explanations, emphasize end-to-end evaluation of explanations, and caution against evaluating them in proxy modalities that are different from deployment.
RECONSIDER: Re-Ranking using Span-Focused Cross-Attention for Open Domain Question Answering
Oct 21, 2020
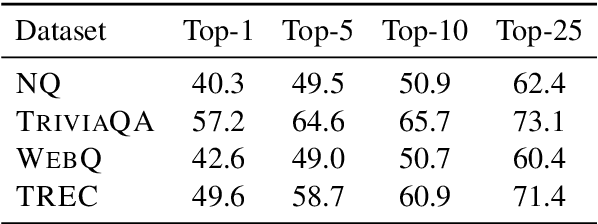
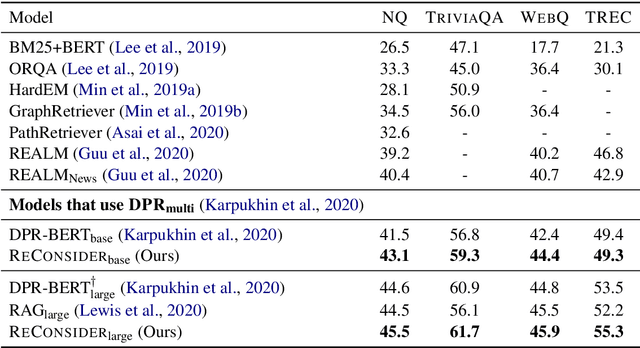
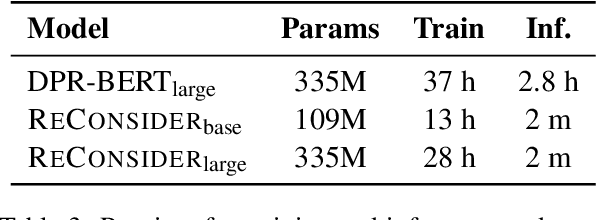
State-of-the-art Machine Reading Comprehension (MRC) models for Open-domain Question Answering (QA) are typically trained for span selection using distantly supervised positive examples and heuristically retrieved negative examples. This training scheme possibly explains empirical observations that these models achieve a high recall amongst their top few predictions, but a low overall accuracy, motivating the need for answer re-ranking. We develop a simple and effective re-ranking approach (RECONSIDER) for span-extraction tasks, that improves upon the performance of large pre-trained MRC models. RECONSIDER is trained on positive and negative examples extracted from high confidence predictions of MRC models, and uses in-passage span annotations to perform span-focused re-ranking over a smaller candidate set. As a result, RECONSIDER learns to eliminate close false positive passages, and achieves a new state of the art on four QA tasks, including 45.5% Exact Match accuracy on Natural Questions with real user questions, and 61.7% on TriviaQA.
Efficient One-Pass End-to-End Entity Linking for Questions
Oct 06, 2020
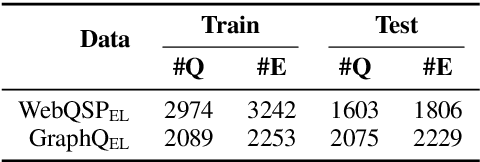
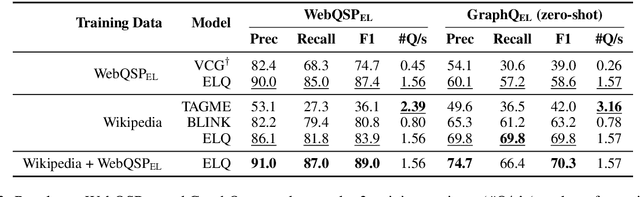
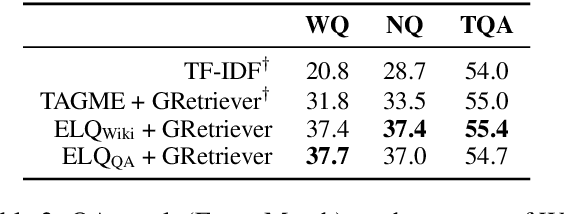
We present ELQ, a fast end-to-end entity linking model for questions, which uses a biencoder to jointly perform mention detection and linking in one pass. Evaluated on WebQSP and GraphQuestions with extended annotations that cover multiple entities per question, ELQ outperforms the previous state of the art by a large margin of +12.7% and +19.6% F1, respectively. With a very fast inference time (1.57 examples/s on a single CPU), ELQ can be useful for downstream question answering systems. In a proof-of-concept experiment, we demonstrate that using ELQ significantly improves the downstream QA performance of GraphRetriever (arXiv:1911.03868). Code and data available at https://github.com/facebookresearch/BLINK/tree/master/elq
DeLighT: Very Deep and Light-weight Transformer
Aug 03, 2020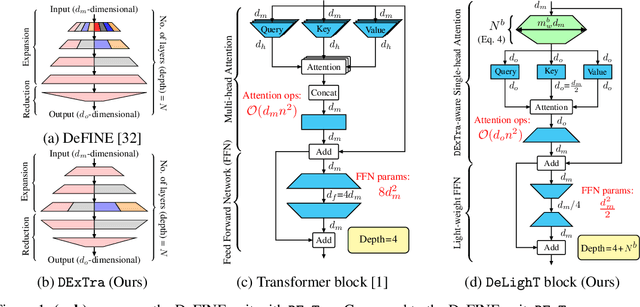
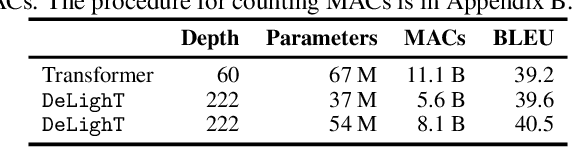
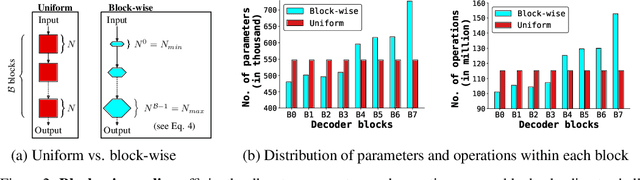
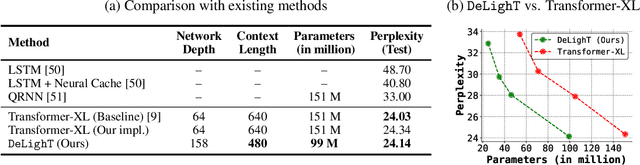
We introduce a very deep and light-weight transformer, DeLighT, that delivers similar or better performance than transformer-based models with significantly fewer parameters. DeLighT more efficiently allocates parameters both (1) within each Transformer block using DExTra, a deep and light-weight transformation and (2) across blocks using block-wise scaling, that allows for shallower and narrower DeLighT blocks near the input and wider and deeper DeLighT blocks near the output. Overall, DeLighT networks are 2.5 to 4 times deeper than standard transformer models and yet have fewer parameters and operations. Experiments on machine translation and language modeling tasks show that DeLighT matches the performance of baseline Transformers with significantly fewer parameters. On the WMT'14 En-Fr high resource dataset, DeLighT requires 1.8 times fewer parameters and 2 times fewer operations and achieves better performance (+0.4 BLEU score) than baseline transformers. On the WMT'16 En-Ro low resource dataset, DeLighT delivers similar performance with 2.8 times fewer parameters than baseline transformers.
JuICe: A Large Scale Distantly Supervised Dataset for Open Domain Context-based Code Generation
Oct 09, 2019
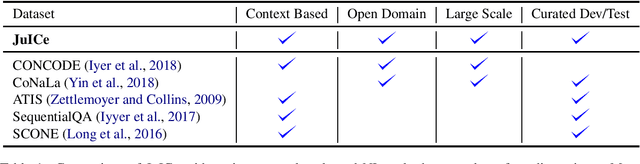
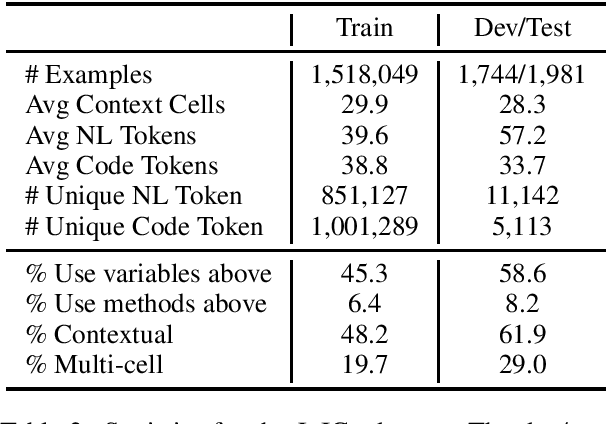
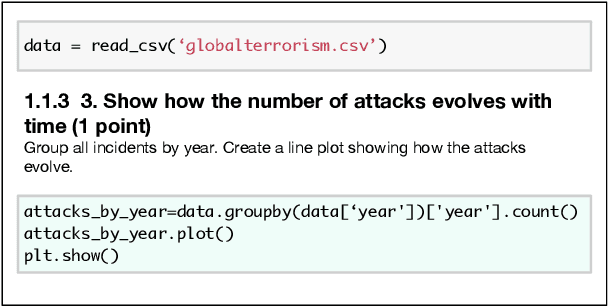
Interactive programming with interleaved code snippet cells and natural language markdown is recently gaining popularity in the form of Jupyter notebooks, which accelerate prototyping and collaboration. To study code generation conditioned on a long context history, we present JuICe, a corpus of 1.5 million examples with a curated test set of 3.7K instances based on online programming assignments. Compared with existing contextual code generation datasets, JuICe provides refined human-curated data, open-domain code, and an order of magnitude more training data. Using JuICe, we train models for two tasks: (1) generation of the API call sequence in a code cell, and (2) full code cell generation, both conditioned on the NL-Code history up to a particular code cell. Experiments using current baseline code generation models show that both context and distant supervision aid in generation, and that the dataset is challenging for current systems.
Learning Programmatic Idioms for Scalable Semantic Parsing
Apr 19, 2019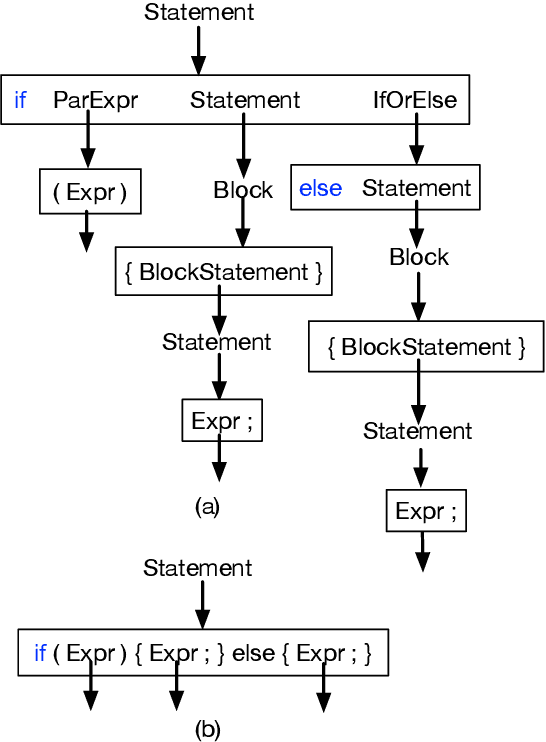
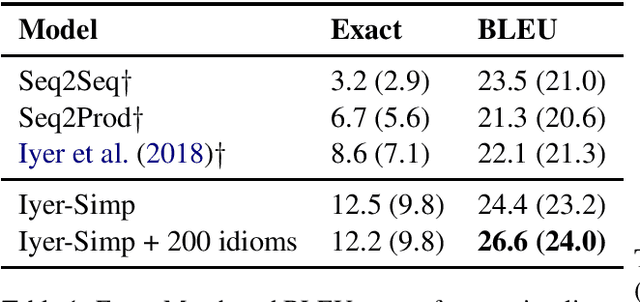
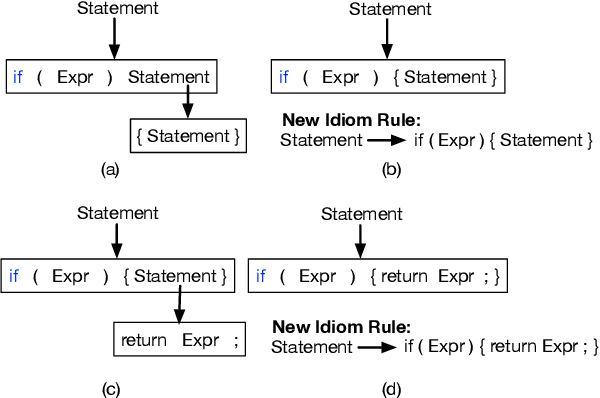
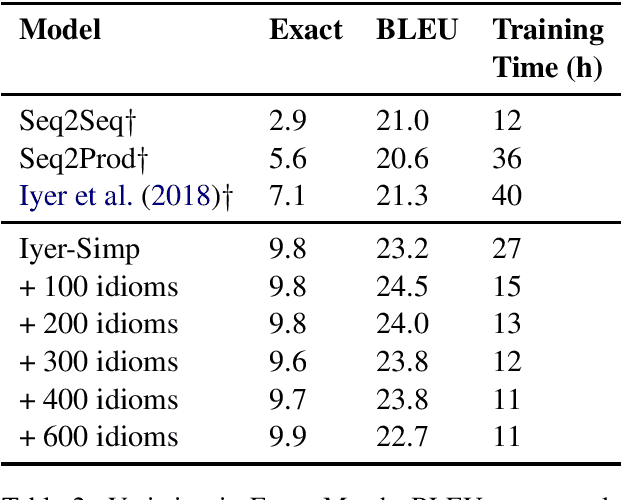
Programmers typically organize executable source code using high-level coding patterns or idiomatic structures such as nested loops, exception handlers and recursive blocks, rather than as individual code tokens. In contrast, state of the art semantic parsers still map natural language instructions to source code by building the code syntax tree one node at a time. In this paper, we introduce an iterative method to extract code idioms from large source code corpora by repeatedly collapsing most-frequent depth-2 subtrees of their syntax trees, and we train semantic parsers to apply these idioms during decoding. We apply this idiom-based code generation to a recent context-dependent semantic parsing task, and improve the state of the art by 2.2% BLEU score while reducing training time by more than 50%. This improved speed enables us to scale up the model by training on an extended training set that is 5x times larger, to further move up the state of the art by an additional 2.3% BLEU and 0.9% exact match.
Mapping Language to Code in Programmatic Context
Aug 29, 2018
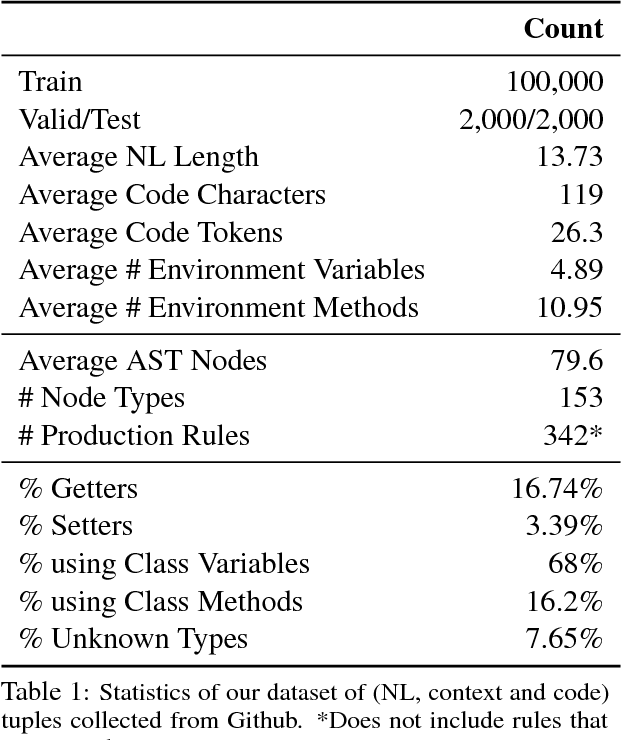

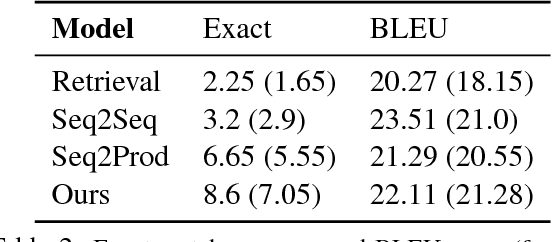
Source code is rarely written in isolation. It depends significantly on the programmatic context, such as the class that the code would reside in. To study this phenomenon, we introduce the task of generating class member functions given English documentation and the programmatic context provided by the rest of the class. This task is challenging because the desired code can vary greatly depending on the functionality the class provides (e.g., a sort function may or may not be available when we are asked to "return the smallest element" in a particular member variable list). We introduce CONCODE, a new large dataset with over 100,000 examples consisting of Java classes from online code repositories, and develop a new encoder-decoder architecture that models the interaction between the method documentation and the class environment. We also present a detailed error analysis suggesting that there is significant room for future work on this task.
Learning to Map Context-Dependent Sentences to Executable Formal Queries
Apr 25, 2018

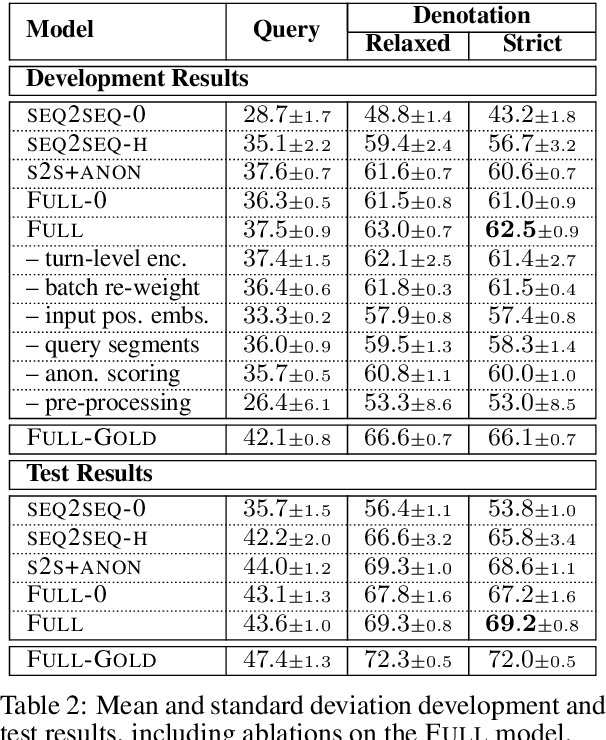
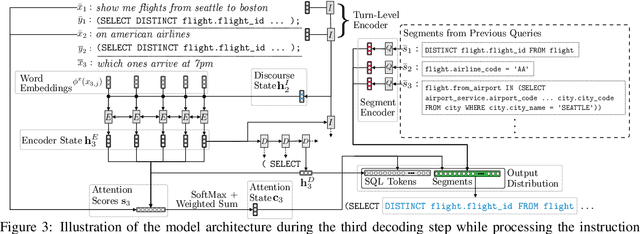
We propose a context-dependent model to map utterances within an interaction to executable formal queries. To incorporate interaction history, the model maintains an interaction-level encoder that updates after each turn, and can copy sub-sequences of previously predicted queries during generation. Our approach combines implicit and explicit modeling of references between utterances. We evaluate our model on the ATIS flight planning interactions, and demonstrate the benefits of modeling context and explicit references.
Neural AMR: Sequence-to-Sequence Models for Parsing and Generation
Aug 18, 2017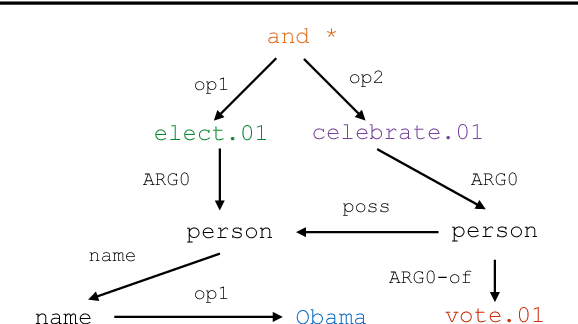
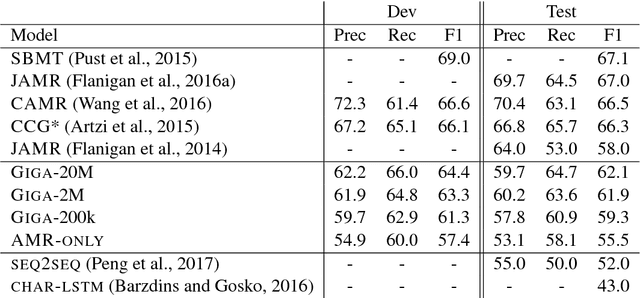


Sequence-to-sequence models have shown strong performance across a broad range of applications. However, their application to parsing and generating text usingAbstract Meaning Representation (AMR)has been limited, due to the relatively limited amount of labeled data and the non-sequential nature of the AMR graphs. We present a novel training procedure that can lift this limitation using millions of unlabeled sentences and careful preprocessing of the AMR graphs. For AMR parsing, our model achieves competitive results of 62.1SMATCH, the current best score reported without significant use of external semantic resources. For AMR generation, our model establishes a new state-of-the-art performance of BLEU 33.8. We present extensive ablative and qualitative analysis including strong evidence that sequence-based AMR models are robust against ordering variations of graph-to-sequence conversions.
Learning a Neural Semantic Parser from User Feedback
Apr 27, 2017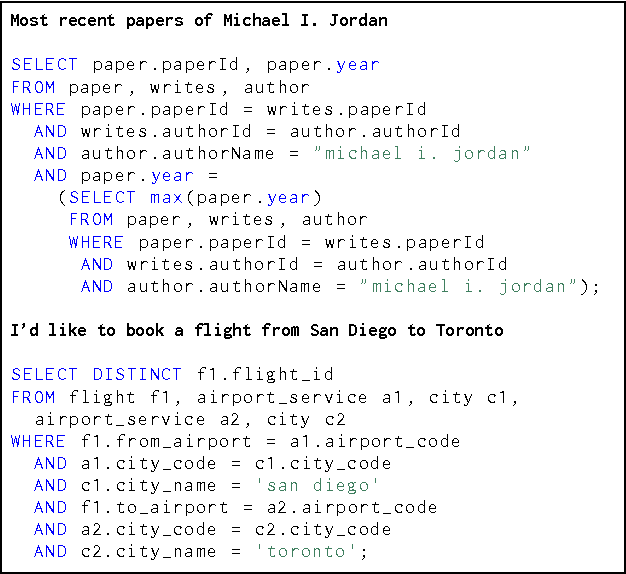
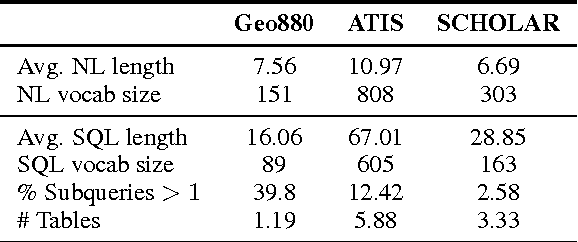
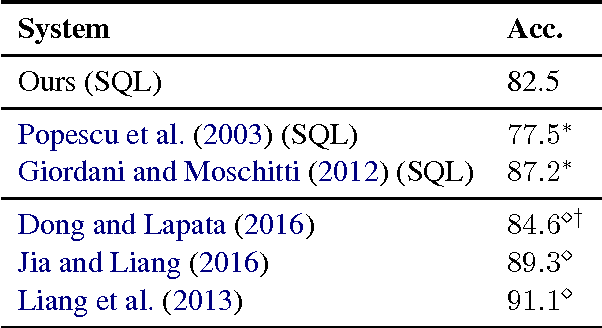
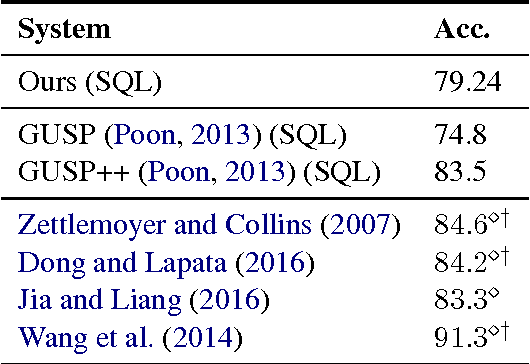
We present an approach to rapidly and easily build natural language interfaces to databases for new domains, whose performance improves over time based on user feedback, and requires minimal intervention. To achieve this, we adapt neural sequence models to map utterances directly to SQL with its full expressivity, bypassing any intermediate meaning representations. These models are immediately deployed online to solicit feedback from real users to flag incorrect queries. Finally, the popularity of SQL facilitates gathering annotations for incorrect predictions using the crowd, which is directly used to improve our models. This complete feedback loop, without intermediate representations or database specific engineering, opens up new ways of building high quality semantic parsers. Experiments suggest that this approach can be deployed quickly for any new target domain, as we show by learning a semantic parser for an online academic database from scratch.