 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks
Jun 16, 2025Recent advances in Large Language Models (LLMs) have showcased impressive reasoning abilities in structured tasks like mathematics and programming, largely driven by Reinforcement Learning with Verifiable Rewards (RLVR), which uses outcome-based signals that are scalable, effective, and robust against reward hacking. However, applying similar techniques to open-ended long-form reasoning tasks remains challenging due to the absence of generic, verifiable reward signals. To address this, we propose Direct Reasoning Optimization (DRO), a reinforcement learning framework for fine-tuning LLMs on open-ended, particularly long-form, reasoning tasks, guided by a new reward signal: the Reasoning Reflection Reward (R3). At its core, R3 selectively identifies and emphasizes key tokens in the reference outcome that reflect the influence of the model's preceding chain-of-thought reasoning, thereby capturing the consistency between reasoning and reference outcome at a fine-grained level. Crucially, R3 is computed internally using the same model being optimized, enabling a fully self-contained training setup. Additionally, we introduce a dynamic data filtering strategy based on R3 for open-ended reasoning tasks, reducing cost while improving downstream performance. We evaluate DRO on two diverse datasets -- ParaRev, a long-form paragraph revision task, and FinQA, a math-oriented QA benchmark -- and show that it consistently outperforms strong baselines while remaining broadly applicable across both open-ended and structured domains.
RLTHF: Targeted Human Feedback for LLM Alignment
Feb 19, 2025



Fine-tuning large language models (LLMs) to align with user preferences is challenging due to the high cost of quality human annotations in Reinforcement Learning from Human Feedback (RLHF) and the generalizability limitations of AI Feedback. To address these challenges, we propose RLTHF, a human-AI hybrid framework that combines LLM-based initial alignment with selective human annotations to achieve full-human annotation alignment with minimal effort. RLTHF identifies hard-to-annotate samples mislabeled by LLMs using a reward model's reward distribution and iteratively enhances alignment by integrating strategic human corrections while leveraging LLM's correctly labeled samples. Evaluations on HH-RLHF and TL;DR datasets show that RLTHF reaches full-human annotation-level alignment with only 6-7% of the human annotation effort. Furthermore, models trained on RLTHF's curated datasets for downstream tasks outperform those trained on fully human-annotated datasets, underscoring the effectiveness of RLTHF's strategic data curation.
Steering Large Language Models between Code Execution and Textual Reasoning
Oct 04, 2024



While a lot of recent research focuses on enhancing the textual reasoning capabilities of Large Language Models (LLMs) by optimizing the multi-agent framework or reasoning chains, several benchmark tasks can be solved with 100% success through direct coding, which is more scalable and avoids the computational overhead associated with textual iterating and searching. Textual reasoning has inherent limitations in solving tasks with challenges in math, logics, optimization, and searching, which is unlikely to be solved by simply scaling up the model and data size. The recently released OpenAI GPT Code Interpreter and multi-agent frameworks such as AutoGen have demonstrated remarkable proficiency of integrating code generation and execution to solve complex tasks using LLMs. However, based on our experiments on 7 existing popular methods for steering code/text generation in both single- and multi-turn settings with 14 tasks and 6 types of LLMs (including the new O1-preview), currently there is no optimal method to correctly steer LLMs to write code when needed. We discover some interesting patterns on when models use code vs. textual reasoning with the evolution to task complexity and model sizes, which even result in an astonishingly inverse scaling law. We also discover that results from LLM written code are not always better than using textual reasoning, even if the task could be solved through code. To mitigate the above issues, we propose three methods to better steer LLM code/text generation and achieve a notable improvement. The costs of token lengths and runtime are thoroughly discussed for all the methods. We believe the problem of steering LLM code/text generation is critical for future research and has much space for further improvement. Project Page, Datasets, and Codes are available at https://yongchao98.github.io/CodeSteer/.
Counterfactual Augmentation for Multimodal Learning Under Presentation Bias
May 23, 2023In real-world machine learning systems, labels are often derived from user behaviors that the system wishes to encourage. Over time, new models must be trained as new training examples and features become available. However, feedback loops between users and models can bias future user behavior, inducing a presentation bias in the labels that compromises the ability to train new models. In this paper, we propose counterfactual augmentation, a novel causal method for correcting presentation bias using generated counterfactual labels. Our empirical evaluations demonstrate that counterfactual augmentation yields better downstream performance compared to both uncorrected models and existing bias-correction methods. Model analyses further indicate that the generated counterfactuals align closely with true counterfactuals in an oracle setting.
MetaXT: Meta Cross-Task Transfer between Disparate Label Spaces
Sep 09, 2021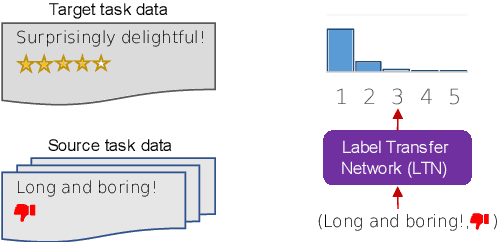
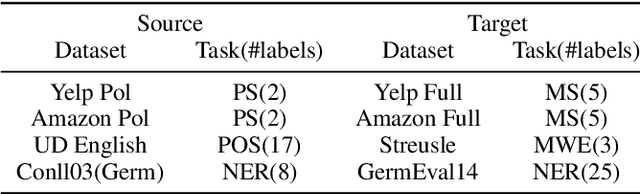
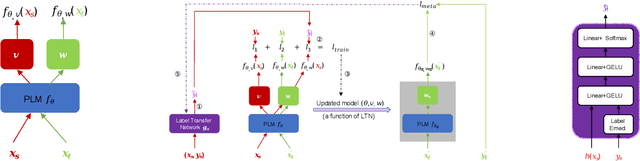
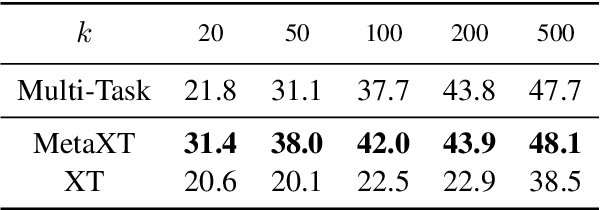
Albeit the universal representational power of pre-trained language models, adapting them onto a specific NLP task still requires a considerably large amount of labeled data. Effective task fine-tuning meets challenges when only a few labeled examples are present for the task. In this paper, we aim to the address of the problem of few shot task learning by exploiting and transferring from a different task which admits a related but disparate label space. Specifically, we devise a label transfer network (LTN) to transform the labels from source task to the target task of interest for training. Both the LTN and the model for task prediction are learned via a bi-level optimization framework, which we term as MetaXT. MetaXT offers a principled solution to best adapt a pre-trained language model to the target task by transferring knowledge from the source task. Empirical evaluations on cross-task transfer settings for four NLP tasks, from two different types of label space disparities, demonstrate the effectiveness of MetaXT, especially when the labeled data in the target task is limited.
A Generalization Error Bound for Multi-class Domain Generalization
May 24, 2019
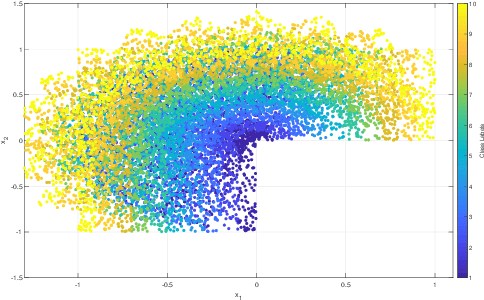
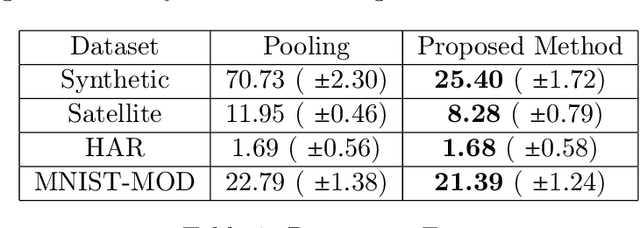

Domain generalization is the problem of assigning labels to an unlabeled data set, given several similar data sets for which labels have been provided. Despite considerable interest in this problem over the last decade, there has been no theoretical analysis in the setting of multi-class classification. In this work, we study a kernel-based learning algorithm and establish a generalization error bound that scales logarithmically in the number of classes, matching state-of-the-art bounds for multi-class classification in the conventional learning setting. We also demonstrate empirically that the proposed algorithm achieves significant performance gains compared to a pooling strategy.
Simple Regret Minimization for Contextual Bandits
Oct 17, 2018

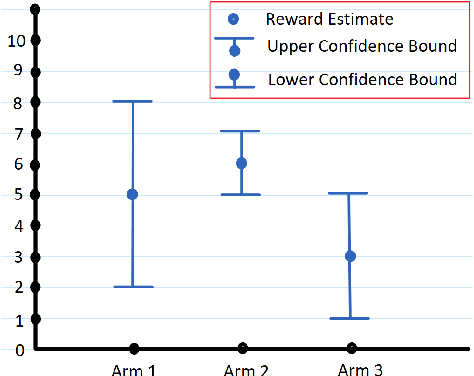
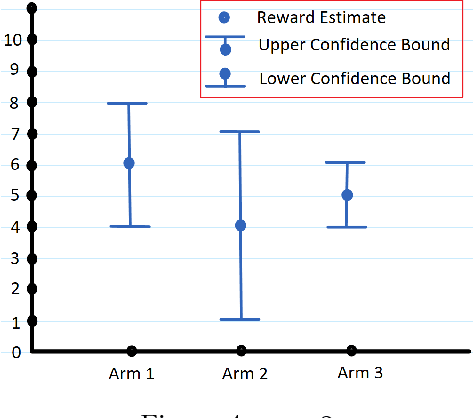
There are two variants of the classical multi-armed bandit (MAB) problem that have received considerable attention from machine learning researchers in recent years: contextual bandits and simple regret minimization. Contextual bandits are a sub-class of MABs where, at every time step, the learner has access to side information that is predictive of the best arm. Simple regret minimization assumes that the learner only incurs regret after a pure exploration phase. In this work, we study simple regret minimization for contextual bandits. Motivated by applications where the learner has separate training and autonomous modes, we assume that, the learner experiences a pure exploration phase, where feedback is received after every action but no regret is incurred, followed by a pure exploitation phase in which regret is incurred but there is no feedback. We present the Contextual-Gap algorithm and establish performance guarantees on the simple regret, i.e., the regret during the pure exploitation phase. Our experiments examine a novel application to adaptive sensor selection for magnetic field estimation in interplanetary spacecraft, and demonstrate considerable improvement over algorithms designed to minimize the cumulative regret.
Kernel Embedding Approaches to Orbit Determination of Spacecraft Clusters
Mar 01, 2018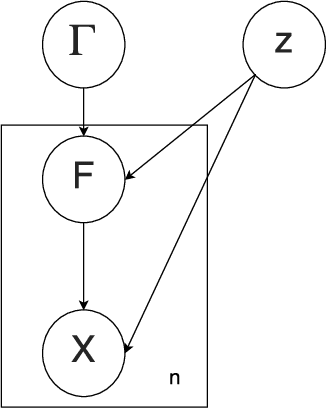

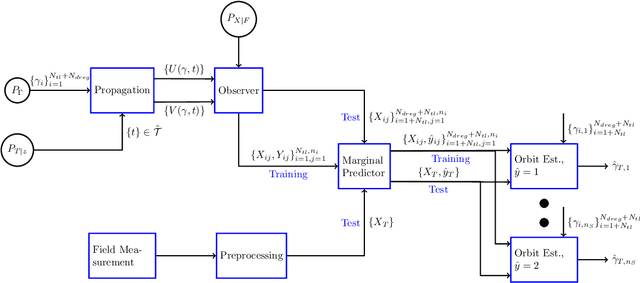

This paper presents a novel formulation and solution of orbit determination over finite time horizons as a learning problem. We present an approach to orbit determination under very broad conditions that are satisfied for n-body problems. These weak conditions allow us to perform orbit determination with noisy and highly non-linear observations such as those presented by range-rate only (Doppler only) observations. We show that domain generalization and distribution regression techniques can learn to estimate orbits of a group of satellites and identify individual satellites especially with prior understanding of correlations between orbits and provide asymptotic convergence conditions. The approach presented requires only visibility and observability of the underlying state from observations and is particularly useful for autonomous spacecraft operations using low-cost ground stations or sensors. We validate the orbit determination approach using observations of two spacecraft (GRIFEX and MCubed-2) along with synthetic datasets of multiple spacecraft deployments and lunar orbits. We also provide a comparison with the standard techniques (EKF) under highly noisy conditions.