 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Aware Experiments without Cookies
Nov 03, 2022



Consider two brands that want to jointly test alternate web experiences for their customers with an A/B test. Such collaborative tests are today enabled using \textit{third-party cookies}, where each brand has information on the identity of visitors to another website. With the imminent elimination of third-party cookies, such A/B tests will become untenable. We propose a two-stage experimental design, where the two brands only need to agree on high-level aggregate parameters of the experiment to test the alternate experiences. Our design respects the privacy of customers. We propose an estimater of the Average Treatment Effect (ATE), show that it is unbiased and theoretically compute its variance. Our demonstration describes how a marketer for a brand can design such an experiment and analyze the results. On real and simulated data, we show that the approach provides valid estimate of the ATE with low variance and is robust to the proportion of visitors overlapping across the brands.
Unifying Causal Inference and Reinforcement Learning using Higher-Order Category Theory
Sep 13, 2022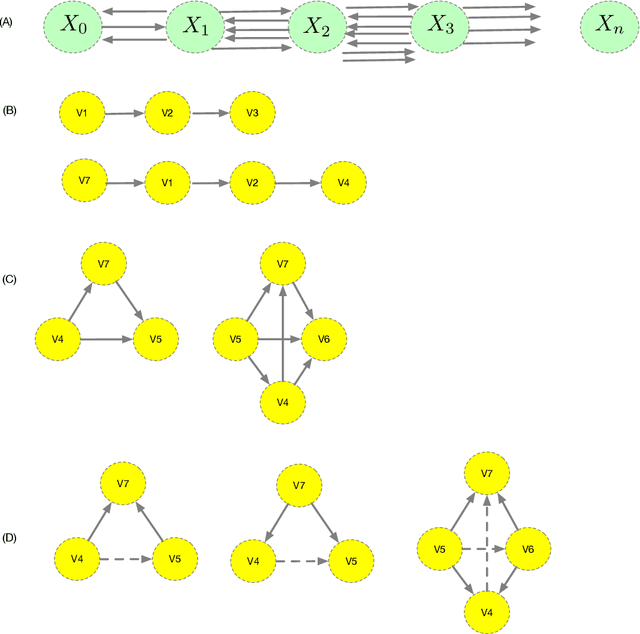
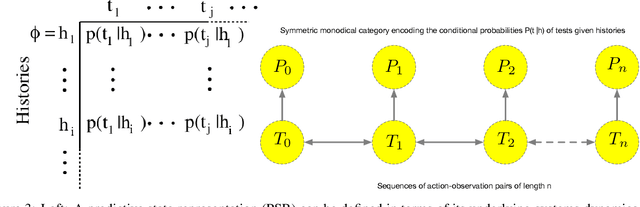
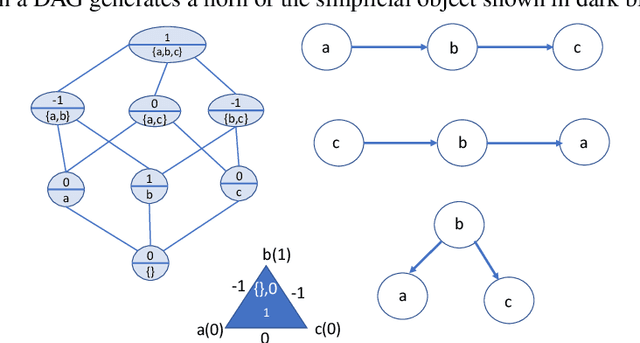
We present a unified formalism for structure discovery of causal models and predictive state representation (PSR) models in reinforcement learning (RL) using higher-order category theory. Specifically, we model structure discovery in both settings using simplicial objects, contravariant functors from the category of ordinal numbers into any category. Fragments of causal models that are equivalent under conditional independence -- defined as causal horns -- as well as subsequences of potential tests in a predictive state representation -- defined as predictive horns -- are both special cases of horns of a simplicial object, subsets resulting from the removal of the interior and the face opposite a particular vertex. Latent structure discovery in both settings involve the same fundamental mathematical problem of finding extensions of horns of simplicial objects through solving lifting problems in commutative diagrams, and exploiting weak homotopies that define higher-order symmetries. Solutions to the problem of filling "inner" vs "outer" horns leads to various notions of higher-order categories, including weak Kan complexes and quasicategories. We define the abstract problem of structure discovery in both settings in terms of adjoint functors between the category of universal causal models or universal decision models and its simplicial object representation.
Categoroids: Universal Conditional Independence
Aug 24, 2022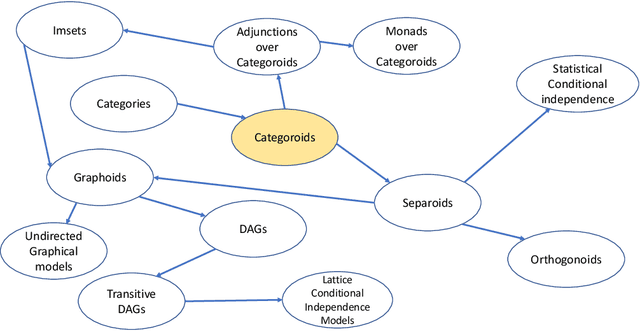
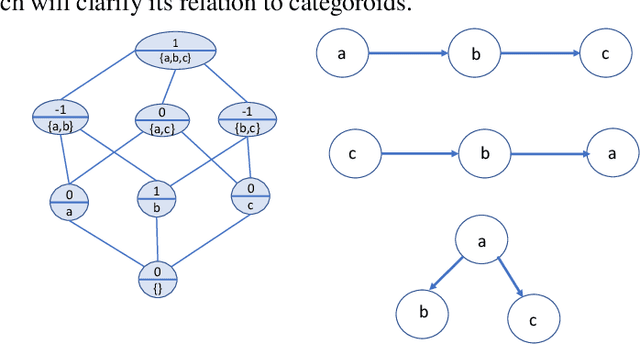
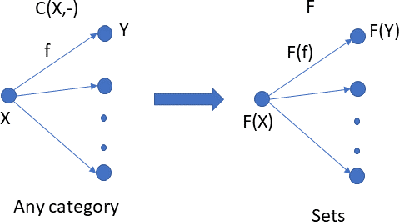
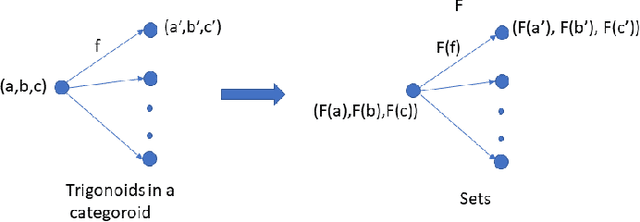
Conditional independence has been widely used in AI, causal inference, machine learning, and statistics. We introduce categoroids, an algebraic structure for characterizing universal properties of conditional independence. Categoroids are defined as a hybrid of two categories: one encoding a preordered lattice structure defined by objects and arrows between them; the second dual parameterization involves trigonoidal objects and morphisms defining a conditional independence structure, with bridge morphisms providing the interface between the binary and ternary structures. We illustrate categoroids using three well-known examples of axiom sets: graphoids, integer-valued multisets, and separoids. Functoroids map one categoroid to another, preserving the relationships defined by all three types of arrows in the co-domain categoroid. We describe a natural transformation across functoroids, which is natural across regular objects and trigonoidal objects, to construct universal representations of conditional independence.. We use adjunctions and monads between categoroids to abstractly characterize faithfulness of graphical and non-graphical representations of conditional independence.
On The Universality of Diagrams for Causal Inference and The Causal Reproducing Property
Jul 06, 2022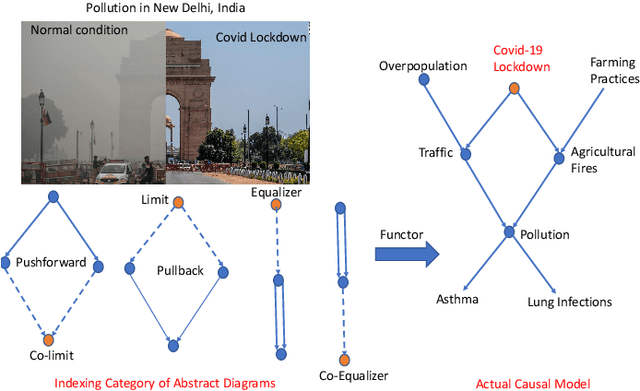
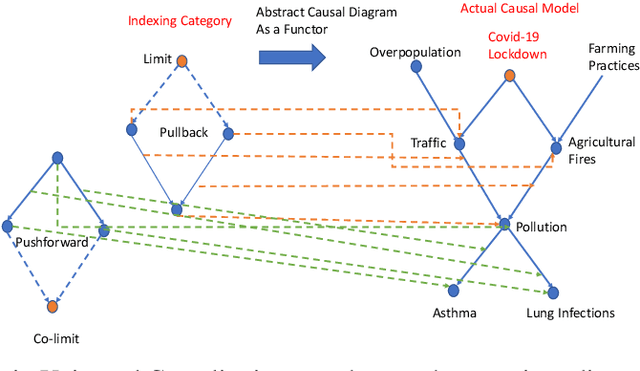
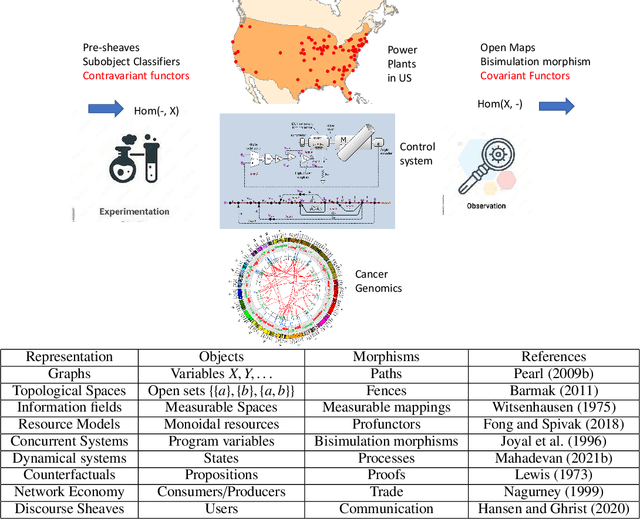
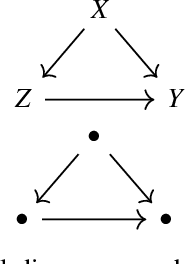
We propose Universal Causality, an overarching framework based on category theory that defines the universal property that underlies causal inference independent of the underlying representational formalism used. More formally, universal causal models are defined as categories consisting of objects and morphisms between them representing causal influences, as well as structures for carrying out interventions (experiments) and evaluating their outcomes (observations). Functors map between categories, and natural transformations map between a pair of functors across the same two categories. Abstract causal diagrams in our framework are built using universal constructions from category theory, including the limit or co-limit of an abstract causal diagram, or more generally, the Kan extension. We present two foundational results in universal causal inference. The first result, called the Universal Causality Theorem (UCT), pertains to the universality of diagrams, which are viewed as functors mapping both objects and relationships from an indexing category of abstract causal diagrams to an actual causal model whose nodes are labeled by random variables, and edges represent functional or probabilistic relationships. UCT states that any causal inference can be represented in a canonical way as the co-limit of an abstract causal diagram of representable objects. UCT follows from a basic result in the theory of sheaves. The second result, the Causal Reproducing Property (CRP), states that any causal influence of a object X on another object Y is representable as a natural transformation between two abstract causal diagrams. CRP follows from the Yoneda Lemma, one of the deepest results in category theory. The CRP property is analogous to the reproducing property in Reproducing Kernel Hilbert Spaces that served as the foundation for kernel methods in machine learning.
Smoothed Online Combinatorial Optimization Using Imperfect Predictions
Apr 23, 2022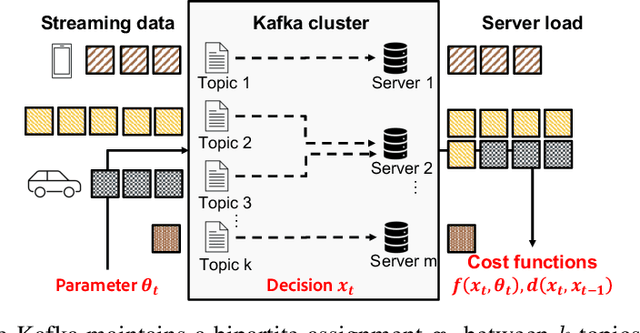

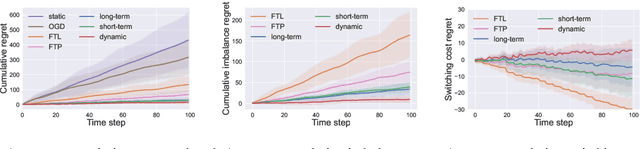
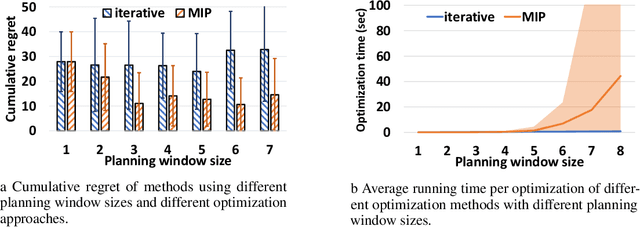
Smoothed online combinatorial optimization considers a learner who repeatedly chooses a combinatorial decision to minimize an unknown changing cost function with a penalty on switching decisions in consecutive rounds. We study smoothed online combinatorial optimization problems when an imperfect predictive model is available, where the model can forecast the future cost functions with uncertainty. We show that using predictions to plan for a finite time horizon leads to regret dependent on the total predictive uncertainty and an additional switching cost. This observation suggests choosing a suitable planning window to balance between uncertainty and switching cost, which leads to an online algorithm with guarantees on the upper and lower bounds of the cumulative regret. Lastly, we provide an iterative algorithm to approximately solve the planning problem in real-time. Empirically, our algorithm shows a significant improvement in cumulative regret compared to other baselines in synthetic online distributed streaming problems.
Universal Decision Models
Oct 28, 2021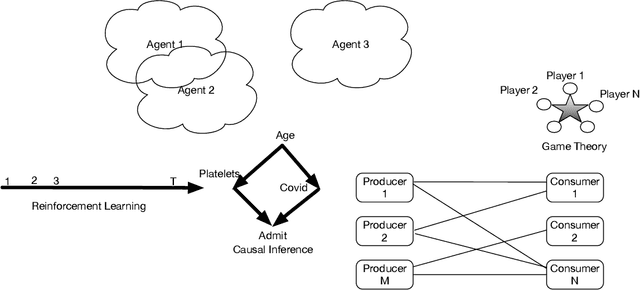
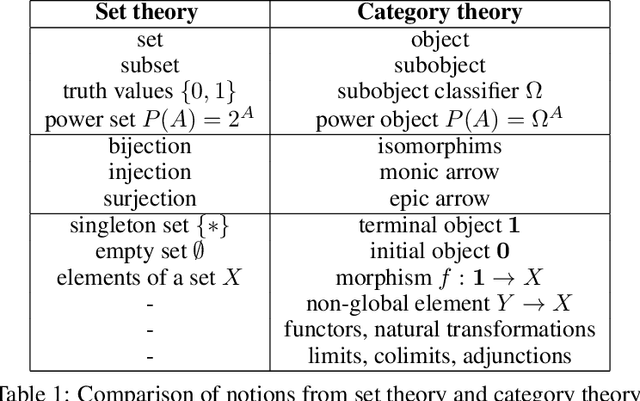


Humans are universal decision makers: we reason causally to understand the world; we act competitively to gain advantage in commerce, games, and war; and we are able to learn to make better decisions through trial and error. In this paper, we propose Universal Decision Model (UDM), a mathematical formalism based on category theory. Decision objects in a UDM correspond to instances of decision tasks, ranging from causal models and dynamical systems such as Markov decision processes and predictive state representations, to network multiplayer games and Witsenhausen's intrinsic models, which generalizes all these previous formalisms. A UDM is a category of objects, which include decision objects, observation objects, and solution objects. Bisimulation morphisms map between decision objects that capture structure-preserving abstractions. We formulate universal properties of UDMs, including information integration, decision solvability, and hierarchical abstraction. We describe universal functorial representations of UDMs, and propose an algorithm for computing the minimal object in a UDM using algebraic topology. We sketch out an application of UDMs to causal inference in network economics, using a complex multiplayer producer-consumer two-sided marketplace.
Causal Inference in Network Economics
Sep 20, 2021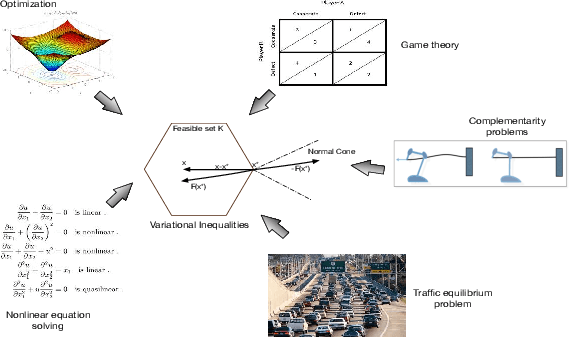
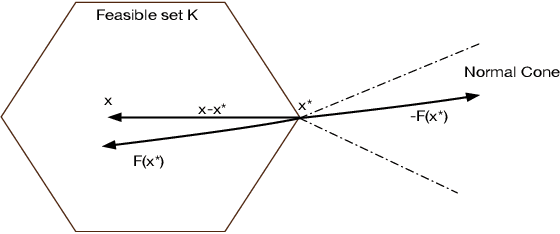
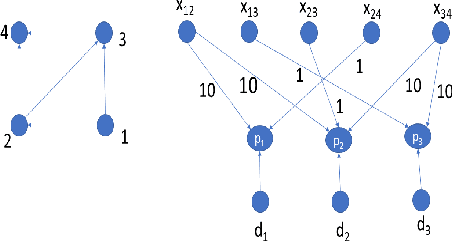
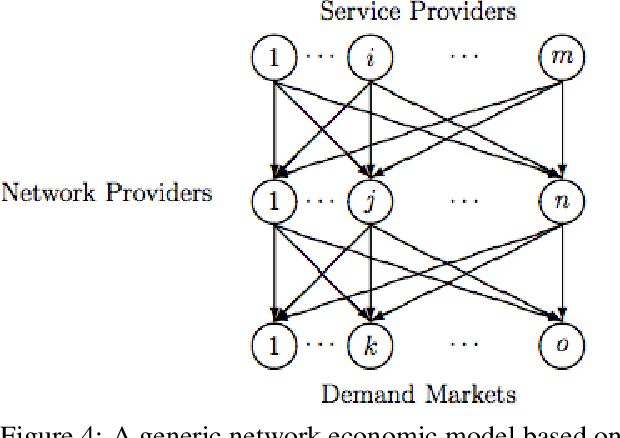
Network economics is the study of a rich class of equilibrium problems that occur in the real world, from traffic management to supply chains and two-sided online marketplaces. In this paper we explore causal inference in network economics, building on the mathematical framework of variational inequalities, which is a generalization of classical optimization. Our framework can be viewed as a synthesis of the well-known variational inequality formalism with the broad principles of causal inference
Asymptotic Causal Inference
Sep 20, 2021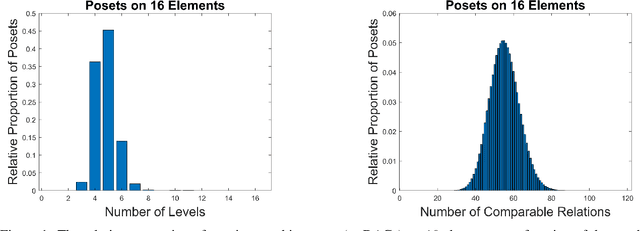


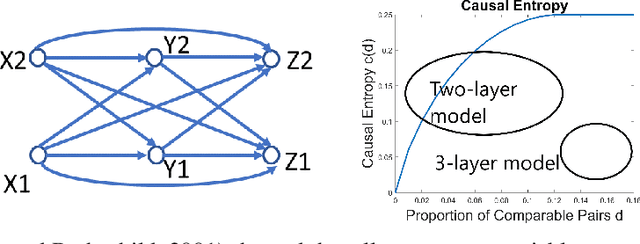
We investigate causal inference in the asymptotic regime as the number of variables approaches infinity using an information-theoretic framework. We define structural entropy of a causal model in terms of its description complexity measured by the logarithmic growth rate, measured in bits, of all directed acyclic graphs (DAGs), parameterized by the edge density d. Structural entropy yields non-intuitive predictions. If we randomly sample a DAG from the space of all models, in the range d = (0, 1/8), almost surely the model is a two-layer DAG! Semantic entropy quantifies the reduction in entropy where edges are removed by causal intervention. Semantic causal entropy is defined as the f-divergence between the observational distribution and the interventional distribution P', where a subset S of edges are intervened on to determine their causal influence. We compare the decomposability properties of semantic entropy for different choices of f-divergences, including KL-divergence, squared Hellinger distance, and total variation distance. We apply our framework to generalize a recently popular bipartite experimental design for studying causal inference on large datasets, where interventions are carried out on one set of variables (e.g., power plants, items in an online store), but outcomes are measured on a disjoint set of variables (residents near power plants, or shoppers). We generalize bipartite designs to k-partite designs, and describe an optimization framework for finding the optimal k-level DAG architecture for any value of d \in (0, 1/2). As edge density increases, a sequence of phase transitions occur over disjoint intervals of d, with deeper DAG architectures emerging for larger values of d. We also give a quantitative bound on the number of samples needed to reliably test for average causal influence for a k-partite design.
Multiscale Manifold Warping
Sep 19, 2021

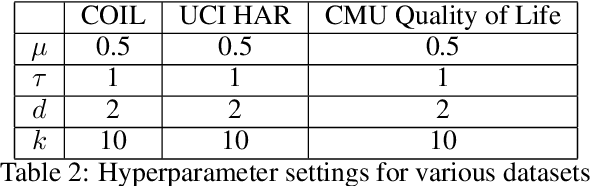
Many real-world applications require aligning two temporal sequences, including bioinformatics, handwriting recognition, activity recognition, and human-robot coordination. Dynamic Time Warping (DTW) is a popular alignment method, but can fail on high-dimensional real-world data where the dimensions of aligned sequences are often unequal. In this paper, we show that exploiting the multiscale manifold latent structure of real-world data can yield improved alignment. We introduce a novel framework called Warping on Wavelets (WOW) that integrates DTW with a a multi-scale manifold learning framework called Diffusion Wavelets. We present a theoretical analysis of the WOW family of algorithms and show that it outperforms previous state of the art methods, such as canonical time warping (CTW) and manifold warping, on several real-world datasets.
Finite-Sample Analysis of Proximal Gradient TD Algorithms
Jul 03, 2020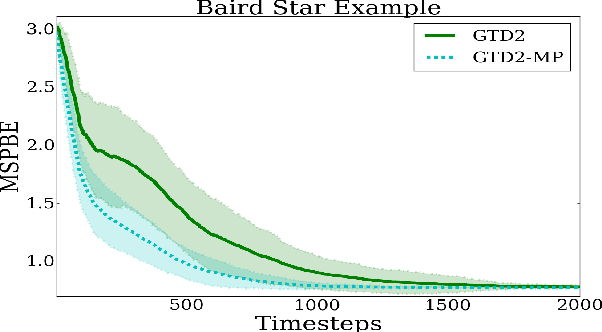
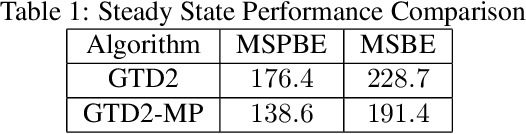
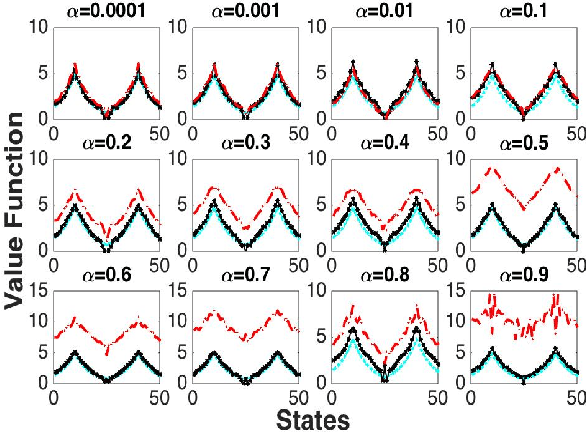
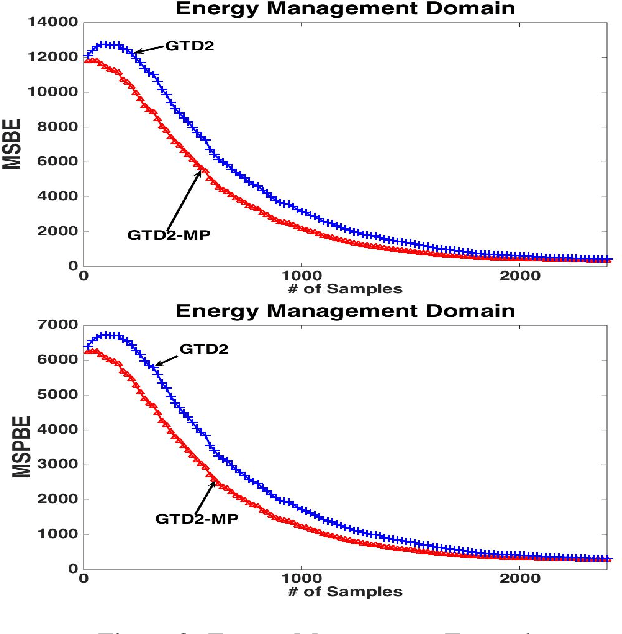
In this paper, we analyze the convergence rate of the gradient temporal difference learning (GTD) family of algorithms. Previous analyses of this class of algorithms use ODE techniques to prove asymptotic convergence, and to the best of our knowledge, no finite-sample analysis has been done. Moreover, there has been not much work on finite-sample analysis for convergent off-policy reinforcement learning algorithms. In this paper, we formulate GTD methods as stochastic gradient algorithms w.r.t.~a primal-dual saddle-point objective function, and then conduct a saddle-point error analysis to obtain finite-sample bounds on their performance. Two revised algorithms are also proposed, namely projected GTD2 and GTD2-MP, which offer improved convergence guarantees and acceleration, respectively. The results of our theoretical analysis show that the GTD family of algorithms are indeed comparable to the existing LSTD methods in off-policy learning scenarios.