 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing for the Future in Non-Stationary MDPs
Paper and Code
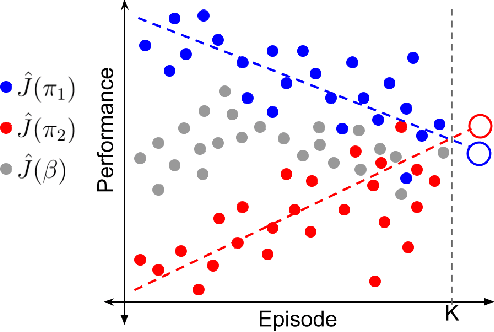
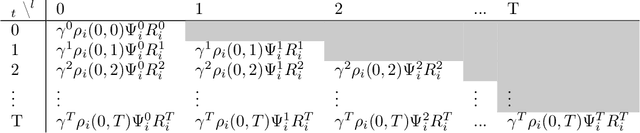
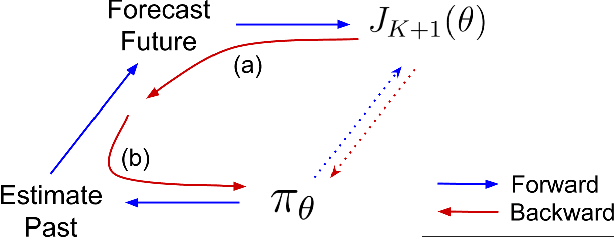
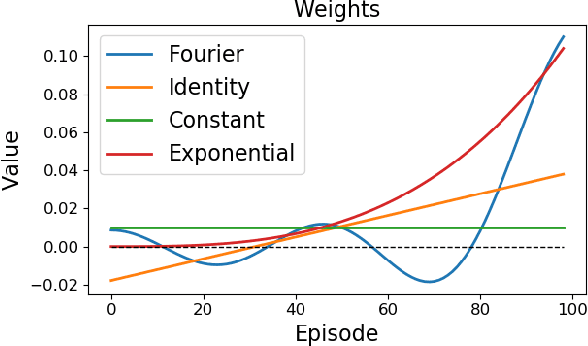
Most reinforcement learning methods are based upon the key assumption that the transition dynamics and reward functions are fixed, that is, the underlying Markov decision process (MDP) is stationary. However, in many practical real-world applications, this assumption is often violated. We discuss how current methods can have inherent limitations for non-stationary MDPs, and therefore searching for a policy that is good for the future, unknown MDP, requires rethinking the optimization paradigm. To address this problem, we develop a method that builds upon ideas from both counter-factual reasoning and curve-fitting to proactively search for a good future policy, without ever modeling the underlying non-stationarity. Interestingly, we observe that minimizing performance over some of the data from past episodes might be beneficial when searching for a policy that maximizes future performance. The effectiveness of the proposed method is demonstrated on problems motivated by real-world applications.