 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemRefine: LLM-Guided Compression for Long-Term Agent Memory
Jun 11, 2026Large language model (LLM) agents are increasingly expected to operate over long-term interactions, where information from past dialogues must be preserved and recalled to support future tasks. However, as interactions accumulate, the memory store grows without bound and fills with redundant entries that inflate storage cost and degrade retrieval by crowding out the most useful evidence. Furthermore, this is especially limiting on resource-constrained platforms with hard memory budgets, motivating us to formulate storage-budgeted memory management, the task of keeping an already constructed memory store within a fixed budget while preserving information useful for future interactions. To this end, we then propose MemRefine, an LLM-guided framework that, since surface similarity poorly reflects factual value, uses similarity only to propose candidate pairs and defers delete, merge, and preserve decisions to an LLM judge based on factual content, iterating until the budget is met. Across multiple memory frameworks and long-term conversation benchmarks, MemRefine consistently meets target budgets while preserving downstream performance and outperforming rule-based baselines under tight budgets.
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
Jun 03, 2026Agents are widely deployed as assistants over documents, tools, and code. However, they typically act only on explicit user requests, which surface only the problems the user has noticed, while many other important problems coexist, hidden in plain sight, within the broader user context, with their total number unknown in advance. We frame this as the task of discovering multiple hidden problems from context, in which coexisting problems should be uncovered, grounded in supporting evidence, and paired with concrete actions. To this end, we introduce TIDE, a template-guided iterative framework with two complementary mechanisms. Specifically, motivated by the observation that single-pass prediction anchors on the most salient cases and yields generic claims, we propose iterative discovery, which surfaces a small batch of candidates per round while conditioning on what has already been found, so subsequent rounds extend coverage; and thought templates, reusable schemas distilled from previously solved cases that specify what contextual signals to attend to and how to connect them, anchoring each prediction in a recognizable problem class. We validate TIDE on two realistic settings, personal workspaces and software repositories, across four model backbones, showing substantial gains over single-shot and parallel multi-agent baselines on task coverage, identification, and resolution.
OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
May 28, 2026Real-world information needs require access to structurally diverse knowledge sources, from unstructured text and relational tables to knowledge graphs and property graphs. Existing retrievers, however, operate over one source at a time under a fixed query language, leaving the broader landscape of available knowledge fragmented behind incompatible interfaces. A natural attempt at unification would collapse these sources into a shared space, but this erases the structural affordances (such as schemas, ontologies, compositional operators) that give each source its expressive power. Effective retrieval over diverse knowledge, therefore, requires not homogenization but an overarching layer that meets each source on its own terms. To achieve this, we present OmniRetrieval, a framework that takes any natural-language query, identifies appropriate knowledge sources, and dispatches source-native queries to their native execution engines. Across an extensive benchmark spanning 13 datasets and 309 distinct knowledge bases over text, relational, and graph-structured sources, OmniRetrieval exceeds single-source baselines, demonstrating that it can serve as a general-purpose interface to the heterogeneous sources while preserving the structural distinctions that make each source valuable.
Adaptive Multi-Agent Response Refinement in Conversational Systems
Nov 11, 2025Large Language Models (LLMs) have demonstrated remarkable success in conversational systems by generating human-like responses. However, they can fall short, especially when required to account for personalization or specific knowledge. In real-life settings, it is impractical to rely on users to detect these errors and request a new response. One way to address this problem is to refine the response before returning it to the user. While existing approaches focus on refining responses within a single LLM, this method struggles to consider diverse aspects needed for effective conversations. In this work, we propose refining responses through a multi-agent framework, where each agent is assigned a specific role for each aspect. We focus on three key aspects crucial to conversational quality: factuality, personalization, and coherence. Each agent is responsible for reviewing and refining one of these aspects, and their feedback is then merged to improve the overall response. To enhance collaboration among them, we introduce a dynamic communication strategy. Instead of following a fixed sequence of agents, our approach adaptively selects and coordinates the most relevant agents based on the specific requirements of each query. We validate our framework on challenging conversational datasets, demonstrating that ours significantly outperforms relevant baselines, particularly in tasks involving knowledge or user's persona, or both.
Temporal Information Retrieval via Time-Specifier Model Merging
Jul 09, 2025The rapid expansion of digital information and knowledge across structured and unstructured sources has heightened the importance of Information Retrieval (IR). While dense retrieval methods have substantially improved semantic matching for general queries, they consistently underperform on queries with explicit temporal constraints--often those containing numerical expressions and time specifiers such as ``in 2015.'' Existing approaches to Temporal Information Retrieval (TIR) improve temporal reasoning but often suffer from catastrophic forgetting, leading to reduced performance on non-temporal queries. To address this, we propose Time-Specifier Model Merging (TSM), a novel method that enhances temporal retrieval while preserving accuracy on non-temporal queries. TSM trains specialized retrievers for individual time specifiers and merges them in to a unified model, enabling precise handling of temporal constraints without compromising non-temporal retrieval. Extensive experiments on both temporal and non-temporal datasets demonstrate that TSM significantly improves performance on temporally constrained queries while maintaining strong results on non-temporal queries, consistently outperforming other baseline methods. Our code is available at https://github.com/seungyoonee/TSM .
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
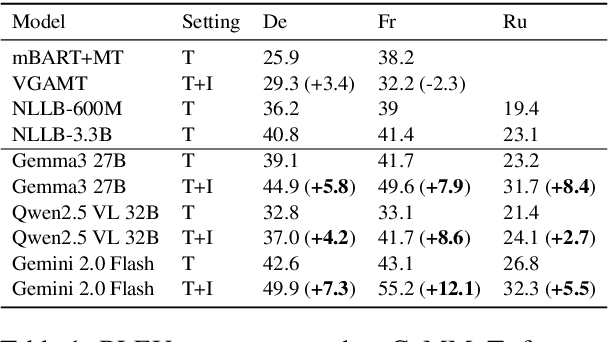

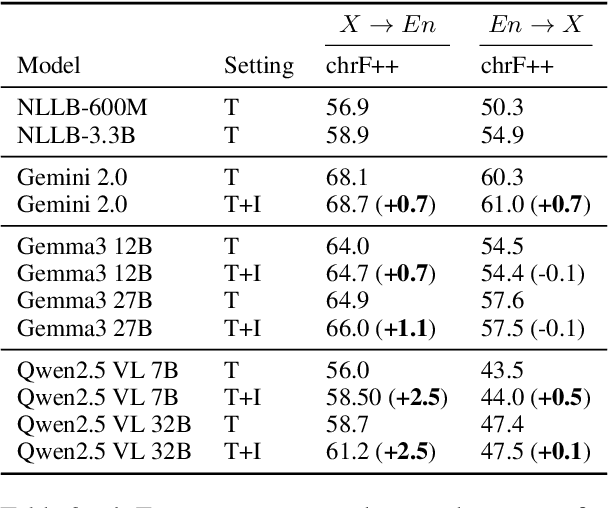
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities
Apr 29, 2025


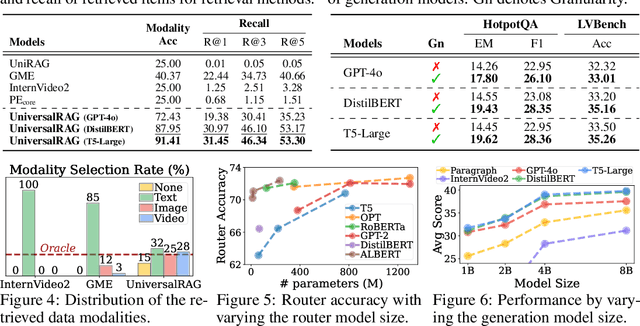
Retrieval-Augmented Generation (RAG) has shown substantial promise in improving factual accuracy by grounding model responses with external knowledge relevant to queries. However, most existing RAG approaches are limited to a text-only corpus, and while recent efforts have extended RAG to other modalities such as images and videos, they typically operate over a single modality-specific corpus. In contrast, real-world queries vary widely in the type of knowledge they require, which a single type of knowledge source cannot address. To address this, we introduce UniversalRAG, a novel RAG framework designed to retrieve and integrate knowledge from heterogeneous sources with diverse modalities and granularities. Specifically, motivated by the observation that forcing all modalities into a unified representation space derived from a single combined corpus causes a modality gap, where the retrieval tends to favor items from the same modality as the query, we propose a modality-aware routing mechanism that dynamically identifies the most appropriate modality-specific corpus and performs targeted retrieval within it. Also, beyond modality, we organize each modality into multiple granularity levels, enabling fine-tuned retrieval tailored to the complexity and scope of the query. We validate UniversalRAG on 8 benchmarks spanning multiple modalities, showing its superiority over modality-specific and unified baselines.
The RAG Paradox: A Black-Box Attack Exploiting Unintentional Vulnerabilities in Retrieval-Augmented Generation Systems
Feb 28, 2025



With the growing adoption of retrieval-augmented generation (RAG) systems, recent studies have introduced attack methods aimed at degrading their performance. However, these methods rely on unrealistic white-box assumptions, such as attackers having access to RAG systems' internal processes. To address this issue, we introduce a realistic black-box attack scenario based on the RAG paradox, where RAG systems inadvertently expose vulnerabilities while attempting to enhance trustworthiness. Because RAG systems reference external documents during response generation, our attack targets these sources without requiring internal access. Our approach first identifies the external sources disclosed by RAG systems and then automatically generates poisoned documents with misinformation designed to match these sources. Finally, these poisoned documents are newly published on the disclosed sources, disrupting the RAG system's response generation process. Both offline and online experiments confirm that this attack significantly reduces RAG performance without requiring internal access. Furthermore, from an insider perspective within the RAG system, we propose a re-ranking method that acts as a fundamental safeguard, offering minimal protection against unforeseen attacks.
Lossless Acceleration of Large Language Models with Hierarchical Drafting based on Temporal Locality in Speculative Decoding
Feb 08, 2025Accelerating inference in Large Language Models (LLMs) is critical for real-time interactions, as they have been widely incorporated into real-world services. Speculative decoding, a fully algorithmic solution, has gained attention for improving inference speed by drafting and verifying tokens, thereby generating multiple tokens in a single forward pass. However, current drafting strategies usually require significant fine-tuning or have inconsistent performance across tasks. To address these challenges, we propose Hierarchy Drafting (HD), a novel lossless drafting approach that organizes various token sources into multiple databases in a hierarchical framework based on temporal locality. In the drafting step, HD sequentially accesses multiple databases to obtain draft tokens from the highest to the lowest locality, ensuring consistent acceleration across diverse tasks and minimizing drafting latency. Our experiments on Spec-Bench using LLMs with 7B and 13B parameters demonstrate that HD outperforms existing database drafting methods, achieving robust inference speedups across model sizes, tasks, and temperatures.
VideoRAG: Retrieval-Augmented Generation over Video Corpus
Jan 10, 2025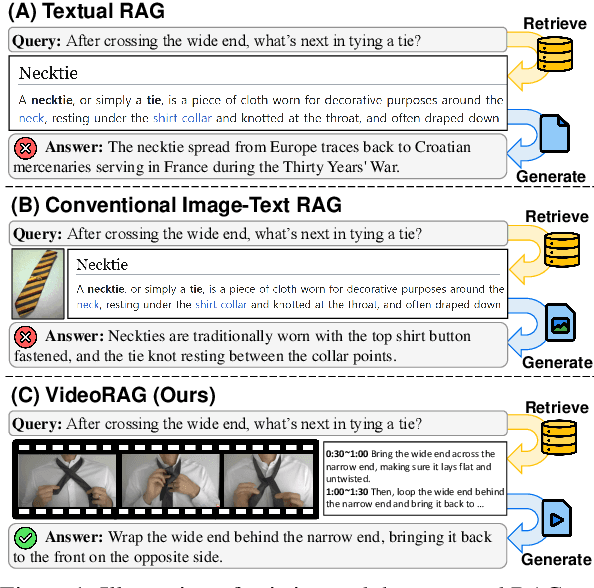
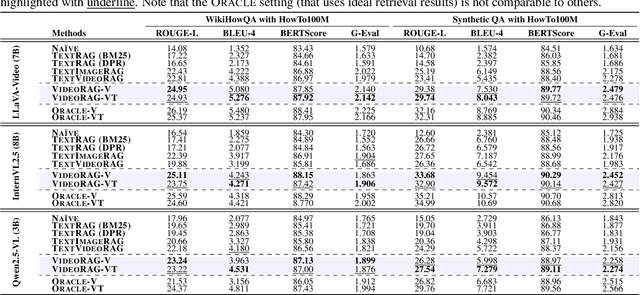
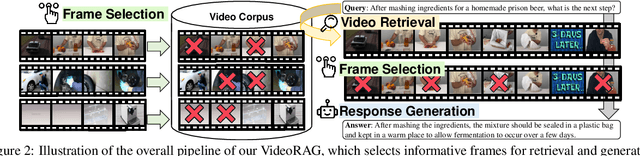
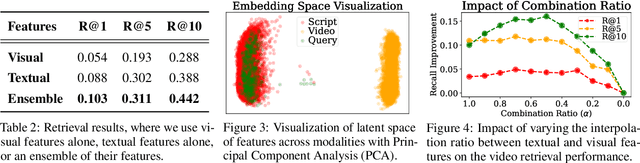
Retrieval-Augmented Generation (RAG) is a powerful strategy to address the issue of generating factually incorrect outputs in foundation models by retrieving external knowledge relevant to queries and incorporating it into their generation process. However, existing RAG approaches have primarily focused on textual information, with some recent advancements beginning to consider images, and they largely overlook videos, a rich source of multimodal knowledge capable of representing events, processes, and contextual details more effectively than any other modality. While a few recent studies explore the integration of videos in the response generation process, they either predefine query-associated videos without retrieving them according to queries, or convert videos into the textual descriptions without harnessing their multimodal richness. To tackle these, we introduce VideoRAG, a novel framework that not only dynamically retrieves relevant videos based on their relevance with queries but also utilizes both visual and textual information of videos in the output generation. Further, to operationalize this, our method revolves around the recent advance of Large Video Language Models (LVLMs), which enable the direct processing of video content to represent it for retrieval and seamless integration of the retrieved videos jointly with queries. We experimentally validate the effectiveness of VideoRAG, showcasing that it is superior to relevant baselines.