 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRE-CoG: Conversational Recommendation of Entities using Constrained Generation
Nov 14, 2023



End-to-end conversational recommendation systems (CRS) generate responses by leveraging both dialog history and a knowledge base (KB). A CRS mainly faces three key challenges: (1) at each turn, it must decide if recommending a KB entity is appropriate; if so, it must identify the most relevant KB entity to recommend; and finally, it must recommend the entity in a fluent utterance that is consistent with the conversation history. Recent CRSs do not pay sufficient attention to these desiderata, often generating unfluent responses or not recommending (relevant) entities at the right turn. We introduce a new CRS we call CoRE-CoG. CoRE-CoG addresses the limitations in prior systems by implementing (1) a recommendation trigger that decides if the system utterance should include an entity, (2) a type pruning module that improves the relevance of recommended entities, and (3) a novel constrained response generator to make recommendations while maintaining fluency. Together, these modules ensure simultaneous accurate recommendation decisions and fluent system utterances. Experiments with recent benchmarks show the superiority particularly on conditional generation sub-tasks with close to 10 F1 and 4 Recall@1 percent points gain over baselines.
CRUSH4SQL: Collective Retrieval Using Schema Hallucination For Text2SQL
Nov 02, 2023



Existing Text-to-SQL generators require the entire schema to be encoded with the user text. This is expensive or impractical for large databases with tens of thousands of columns. Standard dense retrieval techniques are inadequate for schema subsetting of a large structured database, where the correct semantics of retrieval demands that we rank sets of schema elements rather than individual elements. In response, we propose a two-stage process for effective coverage during retrieval. First, we instruct an LLM to hallucinate a minimal DB schema deemed adequate to answer the query. We use the hallucinated schema to retrieve a subset of the actual schema, by composing the results from multiple dense retrievals. Remarkably, hallucination $\unicode{x2013}$ generally considered a nuisance $\unicode{x2013}$ turns out to be actually useful as a bridging mechanism. Since no existing benchmarks exist for schema subsetting on large databases, we introduce three benchmarks. Two semi-synthetic datasets are derived from the union of schemas in two well-known datasets, SPIDER and BIRD, resulting in 4502 and 798 schema elements respectively. A real-life benchmark called SocialDB is sourced from an actual large data warehouse comprising 17844 schema elements. We show that our method1 leads to significantly higher recall than SOTA retrieval-based augmentation methods.
Small Language Models Fine-tuned to Coordinate Larger Language Models improve Complex Reasoning
Oct 21, 2023



Large Language Models (LLMs) prompted to generate chain-of-thought (CoT) exhibit impressive reasoning capabilities. Recent attempts at prompt decomposition toward solving complex, multi-step reasoning problems depend on the ability of the LLM to simultaneously decompose and solve the problem. A significant disadvantage is that foundational LLMs are typically not available for fine-tuning, making adaptation computationally prohibitive. We believe (and demonstrate) that problem decomposition and solution generation are distinct capabilites, better addressed in separate modules, than by one monolithic LLM. We introduce DaSLaM, which uses a decomposition generator to decompose complex problems into subproblems that require fewer reasoning steps. These subproblems are answered by a solver. We use a relatively small (13B parameters) LM as the decomposition generator, which we train using policy gradient optimization to interact with a solver LM (regarded as black-box) and guide it through subproblems, thereby rendering our method solver-agnostic. Evaluation on multiple different reasoning datasets reveal that with our method, a 175 billion parameter LM (text-davinci-003) can produce competitive or even better performance, compared to its orders-of-magnitude larger successor, GPT-4. Additionally, we show that DaSLaM is not limited by the solver's capabilities as a function of scale; e.g., solver LMs with diverse sizes give significant performance improvement with our solver-agnostic decomposition technique. Exhaustive ablation studies evince the superiority of our modular finetuning technique over exorbitantly large decomposer LLMs, based on prompting alone.
Structured Case-based Reasoning for Inference-time Adaptation of Text-to-SQL parsers
Jan 10, 2023



Inference-time adaptation methods for semantic parsing are useful for leveraging examples from newly-observed domains without repeated fine-tuning. Existing approaches typically bias the decoder by simply concatenating input-output example pairs (cases) from the new domain at the encoder's input in a Seq-to-Seq model. Such methods cannot adequately leverage the structure of logical forms in the case examples. We propose StructCBR, a structured case-based reasoning approach, which leverages subtree-level similarity between logical forms of cases and candidate outputs, resulting in better decoder decisions. For the task of adapting Text-to-SQL models to unseen schemas, we show that exploiting case examples in a structured manner via StructCBR offers consistent performance improvements over prior inference-time adaptation methods across five different databases. To the best of our knowledge, we are the first to attempt inference-time adaptation of Text-to-SQL models, and harness trainable structured similarity between subqueries.
mOKB6: A Multilingual Open Knowledge Base Completion Benchmark
Nov 13, 2022Automated completion of open knowledge bases (KBs), which are constructed from triples of the form (subject phrase, relation phrase, object phrase) obtained via open information extraction (IE) from text, is useful for discovering novel facts that may not directly be present in the text. However, research in open knowledge base completion (KBC) has so far been limited to resource-rich languages like English. Using the latest advances in multilingual open IE, we construct the first multilingual open KBC dataset, called mOKB6, that contains facts from Wikipedia in six languages (including English). Improving the previous open KB construction pipeline by doing multilingual coreference resolution and keeping only entity-linked triples, we create a dense open KB. We experiment with several baseline models that have been proposed for both open and closed KBs and observe a consistent benefit of using knowledge gained from other languages. The dataset and accompanying code will be made publicly available.
TwiRGCN: Temporally Weighted Graph Convolution for Question Answering over Temporal Knowledge Graphs
Oct 12, 2022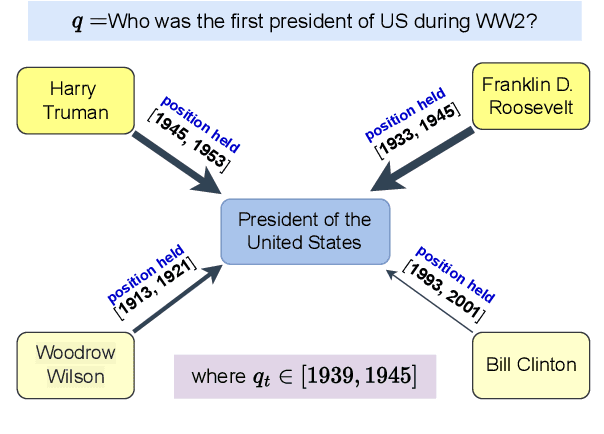

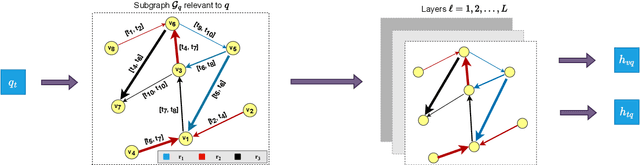
Recent years have witnessed much interest in temporal reasoning over knowledge graphs (KG) for complex question answering (QA), but there remains a substantial gap in human capabilities. We explore how to generalize relational graph convolutional networks (RGCN) for temporal KGQA. Specifically, we propose a novel, intuitive and interpretable scheme to modulate the messages passed through a KG edge during convolution, based on the relevance of its associated time period to the question. We also introduce a gating device to predict if the answer to a complex temporal question is likely to be a KG entity or time and use this prediction to guide our scoring mechanism. We evaluate the resulting system, which we call TwiRGCN, on TimeQuestions, a recently released, challenging dataset for multi-hop complex temporal QA. We show that TwiRGCN significantly outperforms state-of-the-art systems on this dataset across diverse question types. Notably, TwiRGCN improves accuracy by 9--10 percentage points for the most difficult ordinal and implicit question types.
Semi-supervised Stance Detection of Tweets Via Distant Network Supervision
Jan 05, 2022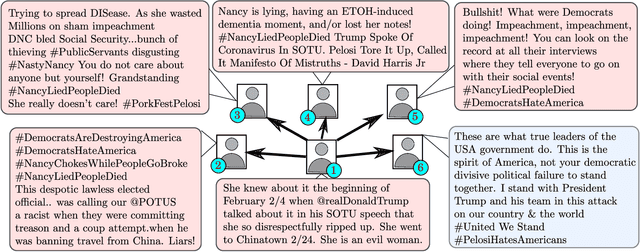
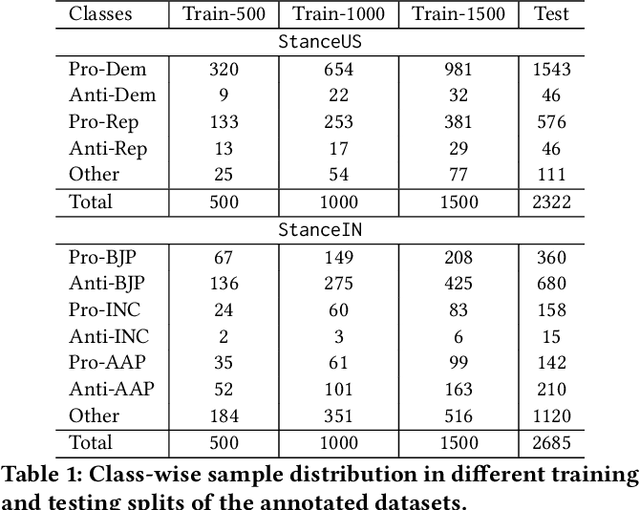
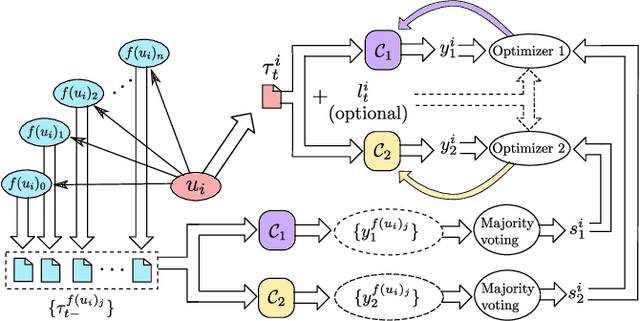
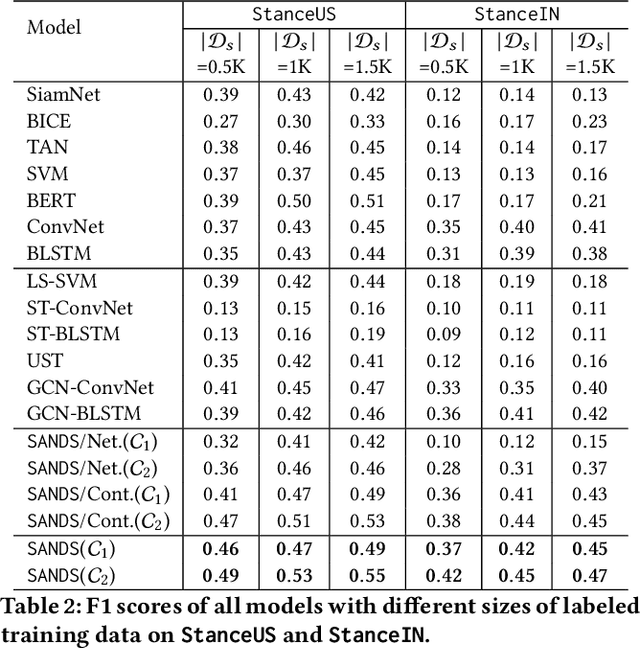
Detecting and labeling stance in social media text is strongly motivated by hate speech detection, poll prediction, engagement forecasting, and concerted propaganda detection. Today's best neural stance detectors need large volumes of training data, which is difficult to curate given the fast-changing landscape of social media text and issues on which users opine. Homophily properties over the social network provide strong signal of coarse-grained user-level stance. But semi-supervised approaches for tweet-level stance detection fail to properly leverage homophily. In light of this, We present SANDS, a new semi-supervised stance detector. SANDS starts from very few labeled tweets. It builds multiple deep feature views of tweets. It also uses a distant supervision signal from the social network to provide a surrogate loss signal to the component learners. We prepare two new tweet datasets comprising over 236,000 politically tinted tweets from two demographics (US and India) posted by over 87,000 users, their follower-followee graph, and over 8,000 tweets annotated by linguists. SANDS achieves a macro-F1 score of 0.55 (0.49) on US (India)-based datasets, outperforming 17 baselines (including variants of SANDS) substantially, particularly for minority stance labels and noisy text. Numerous ablation experiments on SANDS disentangle the dynamics of textual and network-propagated stance signals.
Multi-Instance Training for Question Answering Across Table and Linked Text
Dec 14, 2021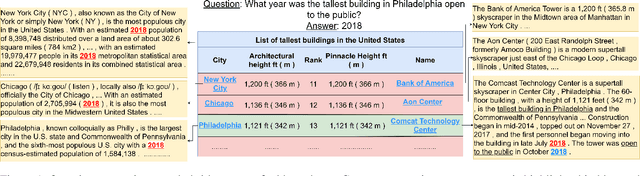
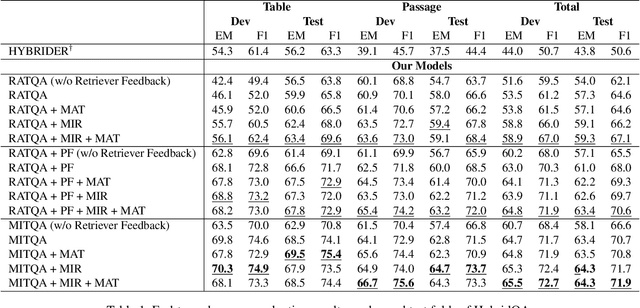
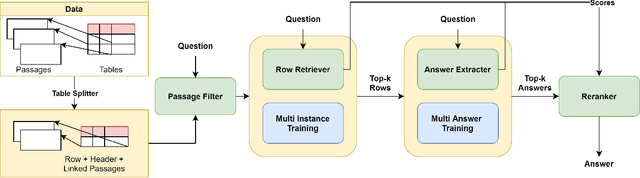

Answering natural language questions using information from tables (TableQA) is of considerable recent interest. In many applications, tables occur not in isolation, but embedded in, or linked to unstructured text. Often, a question is best answered by matching its parts to either table cell contents or unstructured text spans, and extracting answers from either source. This leads to a new space of TextTableQA problems that was introduced by the HybridQA dataset. Existing adaptations of table representation to transformer-based reading comprehension (RC) architectures fail to tackle the diverse modalities of the two representations through a single system. Training such systems is further challenged by the need for distant supervision. To reduce cognitive burden, training instances usually include just the question and answer, the latter matching multiple table rows and text passages. This leads to a noisy multi-instance training regime involving not only rows of the table, but also spans of linked text. We respond to these challenges by proposing MITQA, a new TextTableQA system that explicitly models the different but closely-related probability spaces of table row selection and text span selection. Our experiments indicate the superiority of our approach compared to recent baselines. The proposed method is currently at the top of the HybridQA leaderboard with a held out test set, achieving 21 % absolute improvement on both EM and F1 scores over previous published results.
A Data Bootstrapping Recipe for Low Resource Multilingual Relation Classification
Oct 18, 2021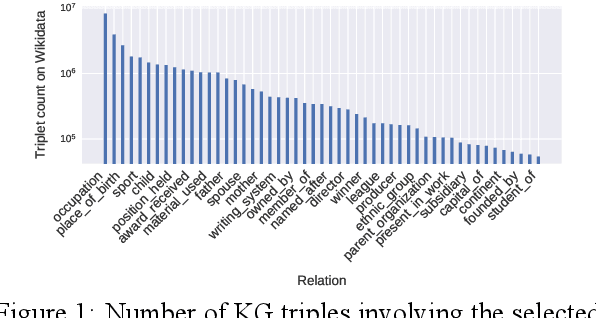

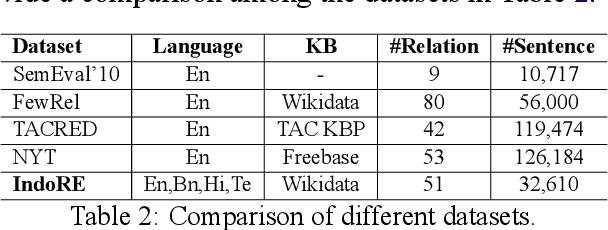
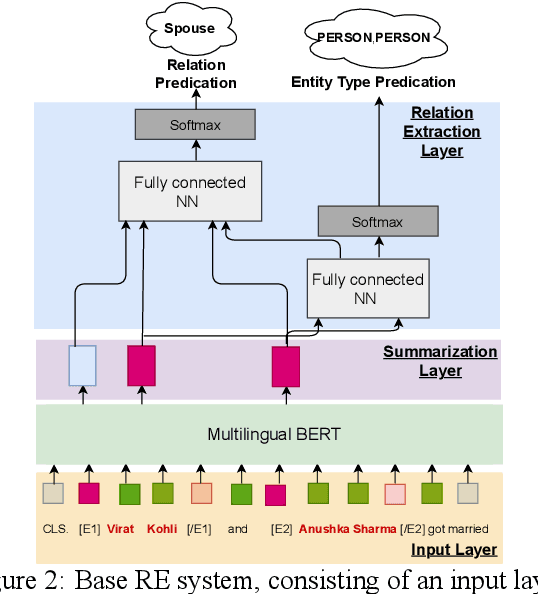
Relation classification (sometimes called 'extraction') requires trustworthy datasets for fine-tuning large language models, as well as for evaluation. Data collection is challenging for Indian languages, because they are syntactically and morphologically diverse, as well as different from resource-rich languages like English. Despite recent interest in deep generative models for Indian languages, relation classification is still not well served by public data sets. In response, we present IndoRE, a dataset with 21K entity and relation tagged gold sentences in three Indian languages, plus English. We start with a multilingual BERT (mBERT) based system that captures entity span positions and type information and provides competitive monolingual relation classification. Using this system, we explore and compare transfer mechanisms between languages. In particular, we study the accuracy efficiency tradeoff between expensive gold instances vs. translated and aligned 'silver' instances. We release the dataset for future research.
Redesigning the Transformer Architecture with Insights from Multi-particle Dynamical Systems
Oct 03, 2021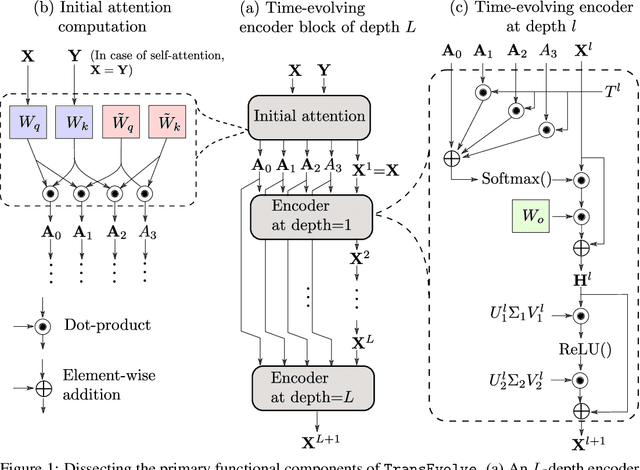
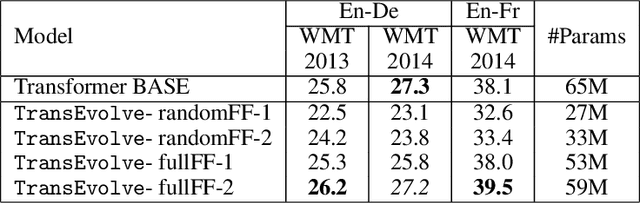
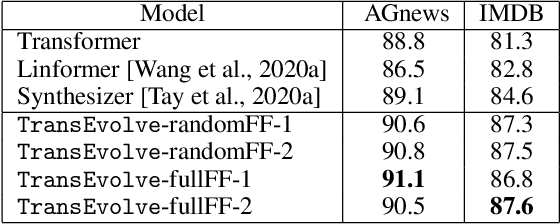
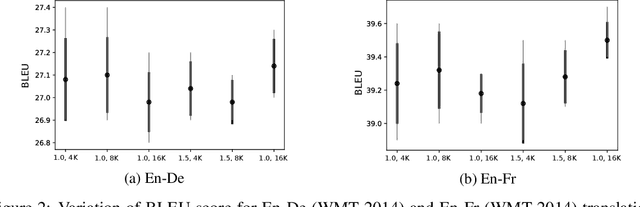
The Transformer and its variants have been proven to be efficient sequence learners in many different domains. Despite their staggering success, a critical issue has been the enormous number of parameters that must be trained (ranging from $10^7$ to $10^{11}$) along with the quadratic complexity of dot-product attention. In this work, we investigate the problem of approximating the two central components of the Transformer -- multi-head self-attention and point-wise feed-forward transformation, with reduced parameter space and computational complexity. We build upon recent developments in analyzing deep neural networks as numerical solvers of ordinary differential equations. Taking advantage of an analogy between Transformer stages and the evolution of a dynamical system of multiple interacting particles, we formulate a temporal evolution scheme, TransEvolve, to bypass costly dot-product attention over multiple stacked layers. We perform exhaustive experiments with TransEvolve on well-known encoder-decoder as well as encoder-only tasks. We observe that the degree of approximation (or inversely, the degree of parameter reduction) has different effects on the performance, depending on the task. While in the encoder-decoder regime, TransEvolve delivers performances comparable to the original Transformer, in encoder-only tasks it consistently outperforms Transformer along with several subsequent variants.