 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiLSTM and Attention-Based Modulation Classification of Realistic Wireless Signals
Aug 14, 2024This work proposes a novel and efficient quadstream BiLSTM-Attention network, abbreviated as QSLA network, for robust automatic modulation classification (AMC) of wireless signals. The proposed model exploits multiple representations of the wireless signal as inputs to the network and the feature extraction process combines convolutional and BiLSTM layers for processing the spatial and temporal features of the signal, respectively. An attention layer is used after the BiLSTM layer to emphasize the important temporal features. The experimental results on the recent and realistic RML22 dataset demonstrate the superior performance of the proposed model with an accuracy up to around 99%. The model is compared with other benchmark models in the literature in terms of classification accuracy, computational complexity, memory usage, and training time to show the effectiveness of our proposed approach.
Responsible AI (RAI) Games and Ensembles
Oct 28, 2023Several recent works have studied the societal effects of AI; these include issues such as fairness, robustness, and safety. In many of these objectives, a learner seeks to minimize its worst-case loss over a set of predefined distributions (known as uncertainty sets), with usual examples being perturbed versions of the empirical distribution. In other words, aforementioned problems can be written as min-max problems over these uncertainty sets. In this work, we provide a general framework for studying these problems, which we refer to as Responsible AI (RAI) games. We provide two classes of algorithms for solving these games: (a) game-play based algorithms, and (b) greedy stagewise estimation algorithms. The former class is motivated by online learning and game theory, whereas the latter class is motivated by the classical statistical literature on boosting, and regression. We empirically demonstrate the applicability and competitive performance of our techniques for solving several RAI problems, particularly around subpopulation shift.
Multi-Instance Training for Question Answering Across Table and Linked Text
Dec 14, 2021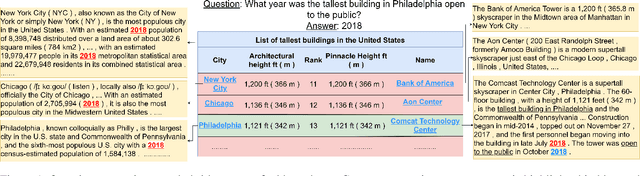
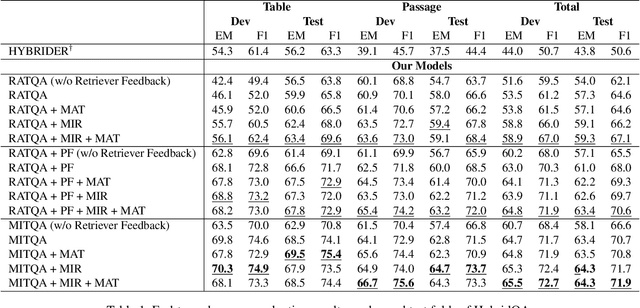
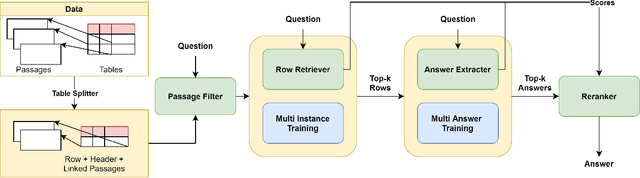

Answering natural language questions using information from tables (TableQA) is of considerable recent interest. In many applications, tables occur not in isolation, but embedded in, or linked to unstructured text. Often, a question is best answered by matching its parts to either table cell contents or unstructured text spans, and extracting answers from either source. This leads to a new space of TextTableQA problems that was introduced by the HybridQA dataset. Existing adaptations of table representation to transformer-based reading comprehension (RC) architectures fail to tackle the diverse modalities of the two representations through a single system. Training such systems is further challenged by the need for distant supervision. To reduce cognitive burden, training instances usually include just the question and answer, the latter matching multiple table rows and text passages. This leads to a noisy multi-instance training regime involving not only rows of the table, but also spans of linked text. We respond to these challenges by proposing MITQA, a new TextTableQA system that explicitly models the different but closely-related probability spaces of table row selection and text span selection. Our experiments indicate the superiority of our approach compared to recent baselines. The proposed method is currently at the top of the HybridQA leaderboard with a held out test set, achieving 21 % absolute improvement on both EM and F1 scores over previous published results.
Stateful Detection of Model Extraction Attacks
Jul 12, 2021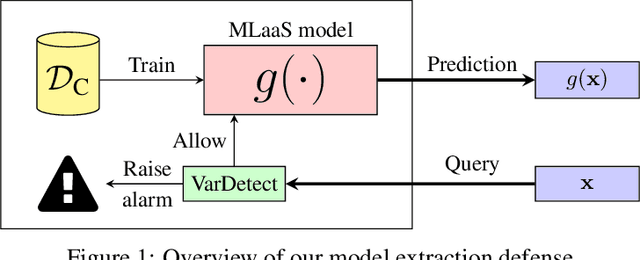
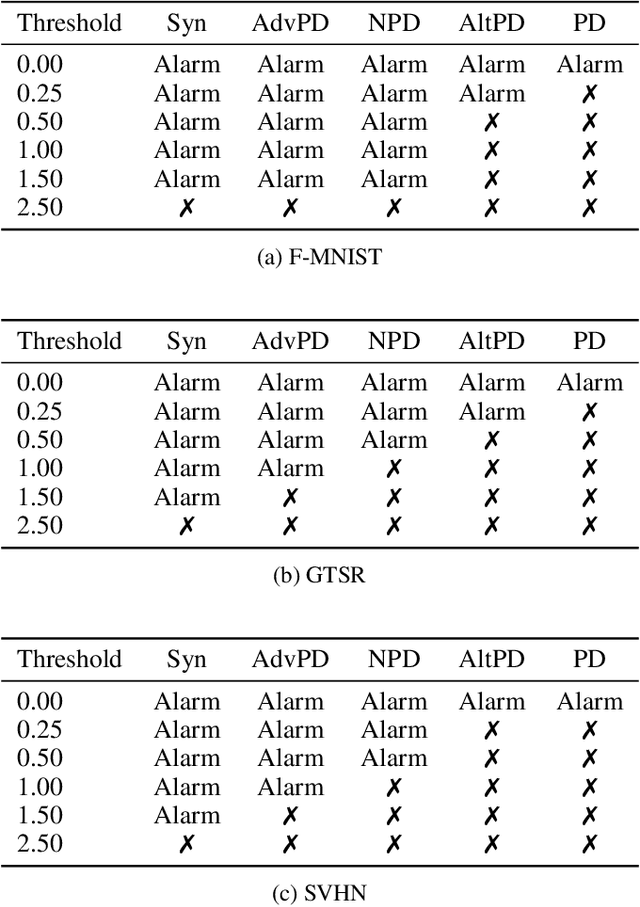

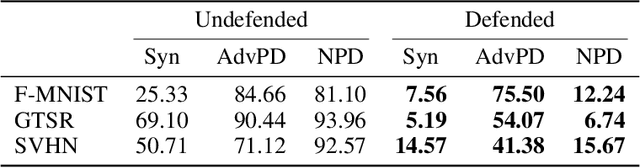
Machine-Learning-as-a-Service providers expose machine learning (ML) models through application programming interfaces (APIs) to developers. Recent work has shown that attackers can exploit these APIs to extract good approximations of such ML models, by querying them with samples of their choosing. We propose VarDetect, a stateful monitor that tracks the distribution of queries made by users of such a service, to detect model extraction attacks. Harnessing the latent distributions learned by a modified variational autoencoder, VarDetect robustly separates three types of attacker samples from benign samples, and successfully raises an alarm for each. Further, with VarDetect deployed as an automated defense mechanism, the extracted substitute models are found to exhibit poor performance and transferability, as intended. Finally, we demonstrate that even adaptive attackers with prior knowledge of the deployment of VarDetect, are detected by it.
A framework for the extraction of Deep Neural Networks by leveraging public data
May 22, 2019


Machine learning models trained on confidential datasets are increasingly being deployed for profit. Machine Learning as a Service (MLaaS) has made such models easily accessible to end-users. Prior work has developed model extraction attacks, in which an adversary extracts an approximation of MLaaS models by making black-box queries to it. However, none of these works is able to satisfy all the three essential criteria for practical model extraction: (1) the ability to work on deep learning models, (2) the non-requirement of domain knowledge and (3) the ability to work with a limited query budget. We design a model extraction framework that makes use of active learning and large public datasets to satisfy them. We demonstrate that it is possible to use this framework to steal deep classifiers trained on a variety of datasets from image and text domains. By querying a model via black-box access for its top prediction, our framework improves performance on an average over a uniform noise baseline by 4.70x for image tasks and 2.11x for text tasks respectively, while using only 30% (30,000 samples) of the public dataset at its disposal.