 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPAM: Online Purchasing-behavior Analysis using Machine learning
Feb 02, 2021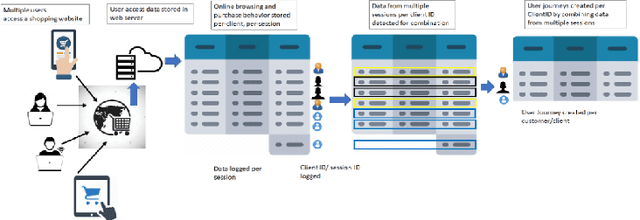

Customer purchasing behavior analysis plays a key role in developing insightful communication strategies between online vendors and their customers. To support the recent increase in online shopping trends, in this work, we present a customer purchasing behavior analysis system using supervised, unsupervised and semi-supervised learning methods. The proposed system analyzes session and user-journey level purchasing behaviors to identify customer categories/clusters that can be useful for targeted consumer insights at scale. We observe higher sensitivity to the design of online shopping portals for session-level purchasing prediction with accuracy/recall in range 91-98%/73-99%, respectively. The user-journey level analysis demonstrates five unique user clusters, wherein 'New Shoppers' are most predictable and 'Impulsive Shoppers' are most unique with low viewing and high carting behaviors for purchases. Further, cluster transformation metrics and partial label learning demonstrates the robustness of each user cluster to new/unlabelled events. Thus, customer clusters can aid strategic targeted nudge models.
Cirrus: A Long-range Bi-pattern LiDAR Dataset
Dec 05, 2020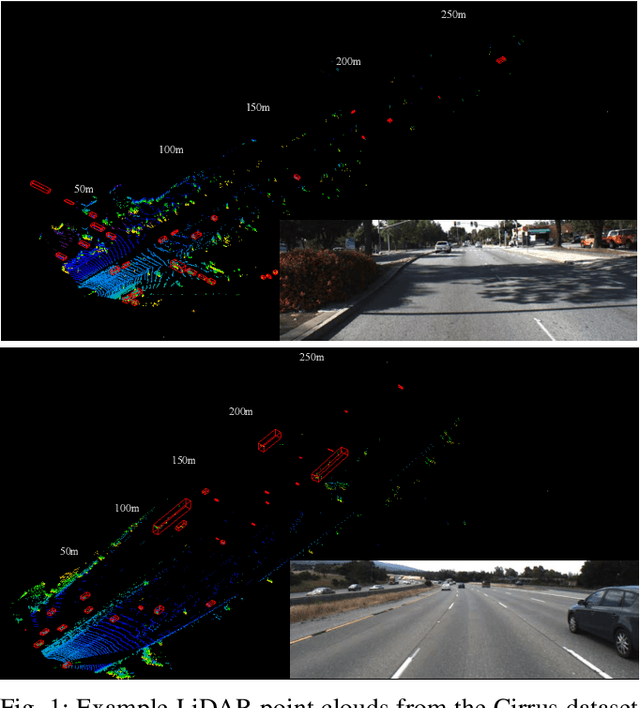
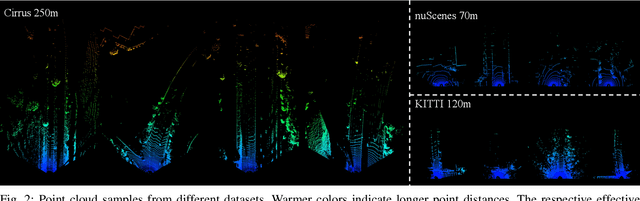
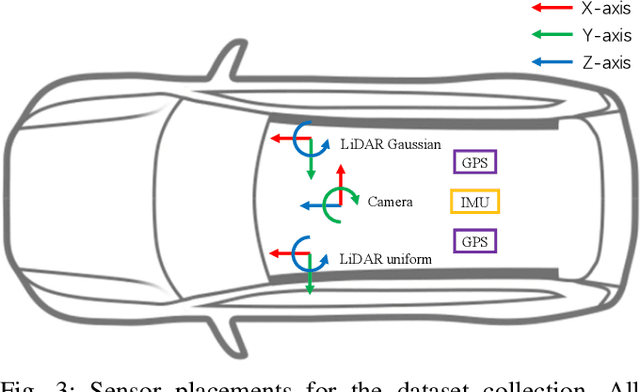
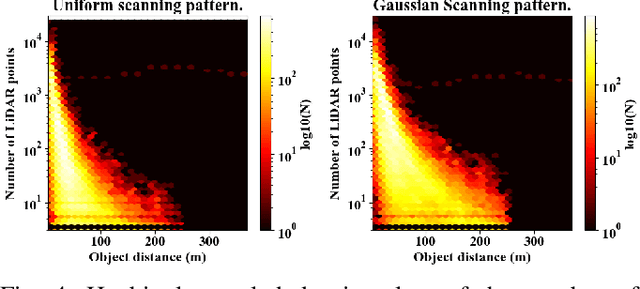
In this paper, we introduce Cirrus, a new long-range bi-pattern LiDAR public dataset for autonomous driving tasks such as 3D object detection, critical to highway driving and timely decision making. Our platform is equipped with a high-resolution video camera and a pair of LiDAR sensors with a 250-meter effective range, which is significantly longer than existing public datasets. We record paired point clouds simultaneously using both Gaussian and uniform scanning patterns. Point density varies significantly across such a long range, and different scanning patterns further diversify object representation in LiDAR. In Cirrus, eight categories of objects are exhaustively annotated in the LiDAR point clouds for the entire effective range. To illustrate the kind of studies supported by this new dataset, we introduce LiDAR model adaptation across different ranges, scanning patterns, and sensor devices. Promising results show the great potential of this new dataset to the robotics and computer vision communities.
Categorizing Online Shopping Behavior from Cosmetics to Electronics: An Analytical Framework
Oct 06, 2020
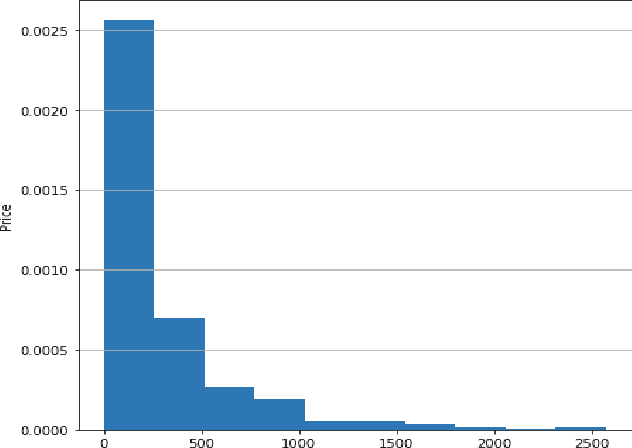
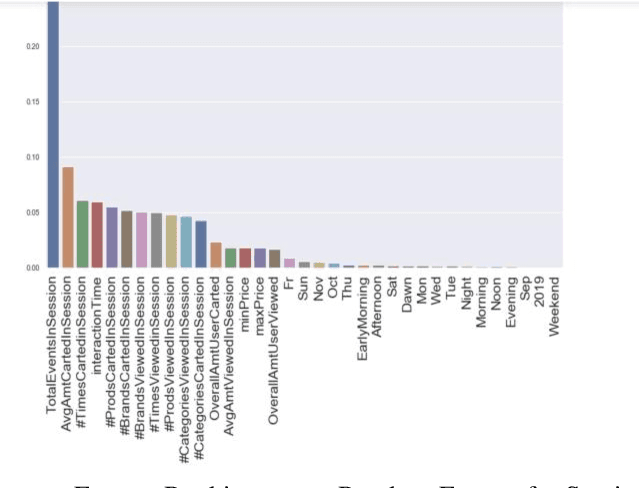
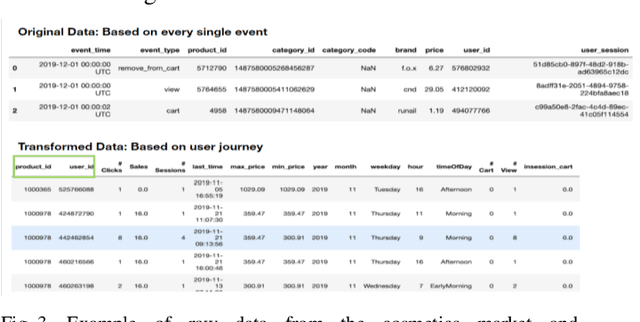
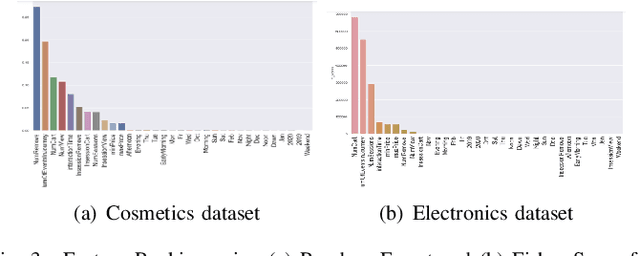
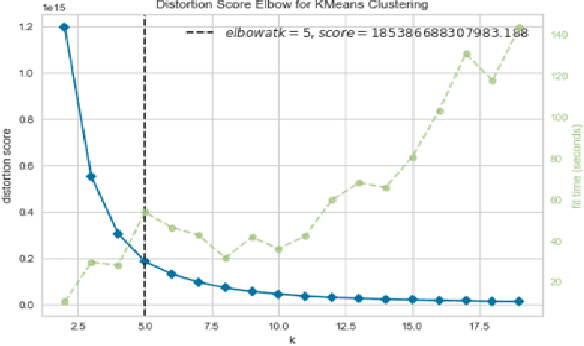
A success factor for modern companies in the age of Digital Marketing is to understand how customers think and behave based on their online shopping patterns. While the conventional method of gathering consumer insights through questionnaires and surveys still form the bases of descriptive analytics for market intelligence units, we propose a machine learning framework to automate this process. In this paper we present a modular consumer data analysis platform that processes session level interaction records between users and products to predict session level, user journey level and customer behavior specific patterns leading towards purchase events. We explore the computational framework and provide test results on two Big data sets-cosmetics and consumer electronics of size 2GB and 15GB, respectively. The proposed system achieves 97-99% classification accuracy and recall for user-journey level purchase predictions and categorizes buying behavior into 5 clusters with increasing purchase ratios for both data sets. Thus, the proposed framework is extendable to other large e-commerce data sets to obtain automated purchase predictions and descriptive consumer insights.
Few Shot Learning Framework to Reduce Inter-observer Variability in Medical Images
Aug 07, 2020Most computer aided pathology detection systems rely on large volumes of quality annotated data to aid diagnostics and follow up procedures. However, quality assuring large volumes of annotated medical image data can be subjective and expensive. In this work we present a novel standardization framework that implements three few-shot learning (FSL) models that can be iteratively trained by atmost 5 images per 3D stack to generate multiple regional proposals (RPs) per test image. These FSL models include a novel parallel echo state network (ParESN) framework and an augmented U-net model. Additionally, we propose a novel target label selection algorithm (TLSA) that measures relative agreeability between RPs and the manually annotated target labels to detect the "best" quality annotation per image. Using the FSL models, our system achieves 0.28-0.64 Dice coefficient across vendor image stacks for intra-retinal cyst segmentation. Additionally, the TLSA is capable of automatically classifying high quality target labels from their noisy counterparts for 60-97% of the images while ensuring manual supervision on remaining images. Also, the proposed framework with ParESN model minimizes manual annotation checking to 12-28% of the total number of images. The TLSA metrics further provide confidence scores for the automated annotation quality assurance. Thus, the proposed framework is flexible to extensions for quality image annotation curation of other image stacks as well.
* 8 pages, 8 figures, 4 tables
FuSSI-Net: Fusion of Spatio-temporal Skeletons for Intention Prediction Network
May 15, 2020

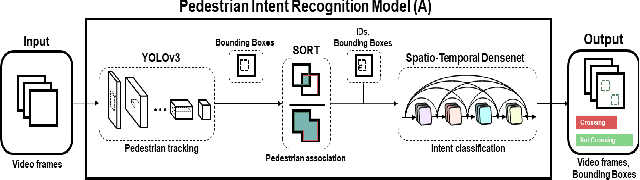

Pedestrian intention recognition is very important to develop robust and safe autonomous driving (AD) and advanced driver assistance systems (ADAS) functionalities for urban driving. In this work, we develop an end-to-end pedestrian intention framework that performs well on day- and night- time scenarios. Our framework relies on objection detection bounding boxes combined with skeletal features of human pose. We study early, late, and combined (early and late) fusion mechanisms to exploit the skeletal features and reduce false positives as well to improve the intention prediction performance. The early fusion mechanism results in AP of 0.89 and precision/recall of 0.79/0.89 for pedestrian intention classification. Furthermore, we propose three new metrics to properly evaluate the pedestrian intention systems. Under these new evaluation metrics for the intention prediction, the proposed end-to-end network offers accurate pedestrian intention up to half a second ahead of the actual risky maneuver.
Range Adaptation for 3D Object Detection in LiDAR
Sep 26, 2019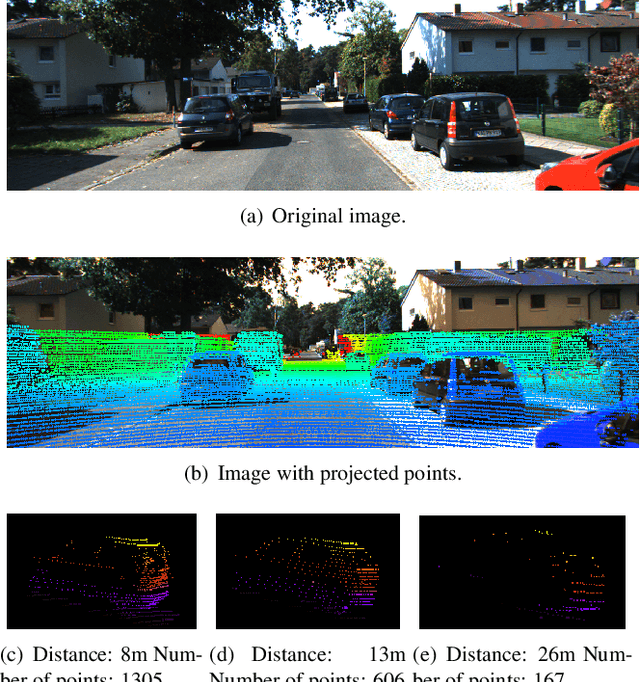
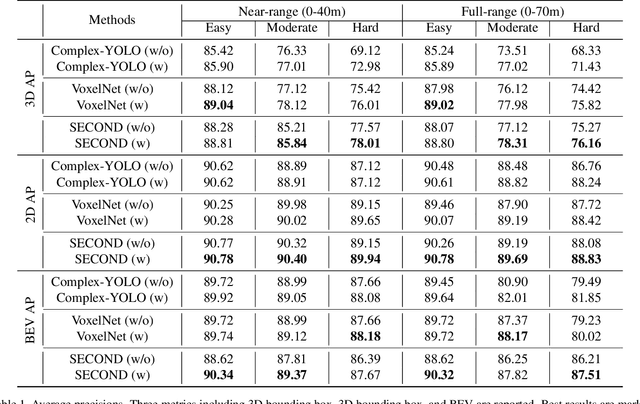
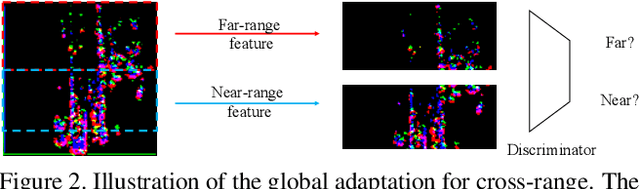

LiDAR-based 3D object detection plays a crucial role in modern autonomous driving systems. LiDAR data often exhibit severe changes in properties across different observation ranges. In this paper, we explore cross-range adaptation for 3D object detection using LiDAR, i.e., far-range observations are adapted to near-range. This way, far-range detection is optimized for similar performance to near-range one. We adopt a bird-eyes view (BEV) detection framework to perform the proposed model adaptation. Our model adaptation consists of an adversarial global adaptation, and a fine-grained local adaptation. The proposed cross range adaptation framework is validated on three state-of-the-art LiDAR based object detection networks, and we consistently observe performance improvement on the far-range objects, without adding any auxiliary parameters to the model. To the best of our knowledge, this paper is the first attempt to study cross-range LiDAR adaptation for object detection in point clouds. To demonstrate the generality of the proposed adaptation framework, experiments on more challenging cross-device adaptation are further conducted, and a new LiDAR dataset with high-quality annotated point clouds is released to promote future research.
Computer Aided Detection of Anemia-like Pallor
Mar 17, 2017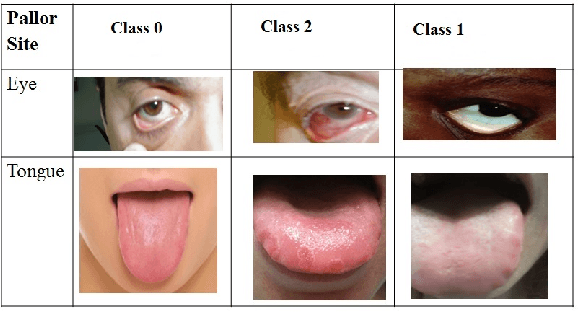
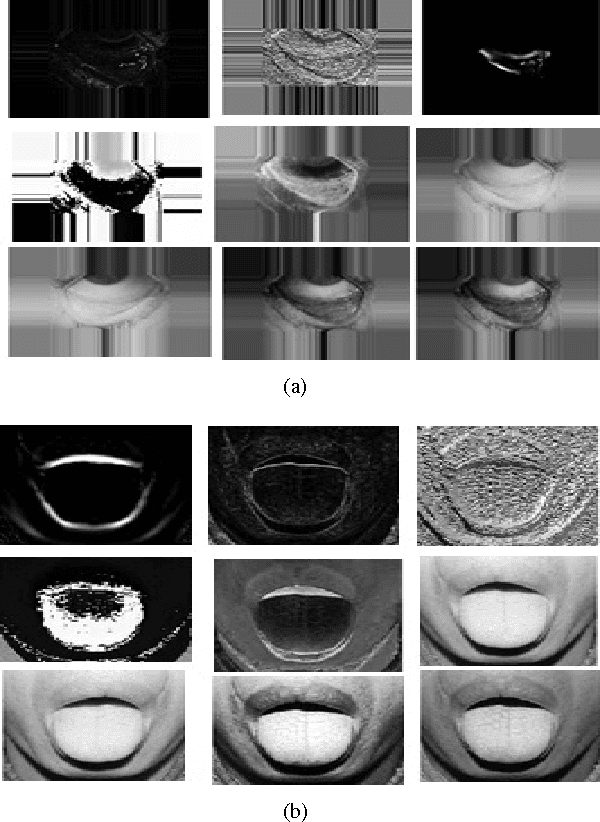
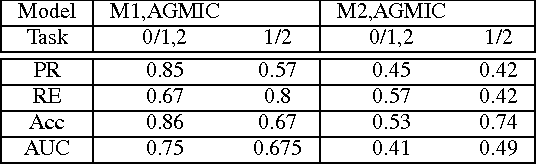
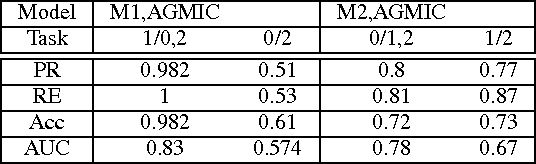
Paleness or pallor is a manifestation of blood loss or low hemoglobin concentrations in the human blood that can be caused by pathologies such as anemia. This work presents the first automated screening system that utilizes pallor site images, segments, and extracts color and intensity-based features for multi-class classification of patients with high pallor due to anemia-like pathologies, normal patients and patients with other abnormalities. This work analyzes the pallor sites of conjunctiva and tongue for anemia screening purposes. First, for the eye pallor site images, the sclera and conjunctiva regions are automatically segmented for regions of interest. Similarly, for the tongue pallor site images, the inner and outer tongue regions are segmented. Then, color-plane based feature extraction is performed followed by machine learning algorithms for feature reduction and image level classification for anemia. In this work, a suite of classification algorithms image-level classifications for normal (class 0), pallor (class 1) and other abnormalities (class 2). The proposed method achieves 86% accuracy, 85% precision and 67% recall in eye pallor site images and 98.2% accuracy and precision with 100% recall in tongue pallor site images for classification of images with pallor. The proposed pallor screening system can be further fine-tuned to detect the severity of anemia-like pathologies using controlled set of local images that can then be used for future benchmarking purposes.
Automated OCT Segmentation for Images with DME
Oct 24, 2016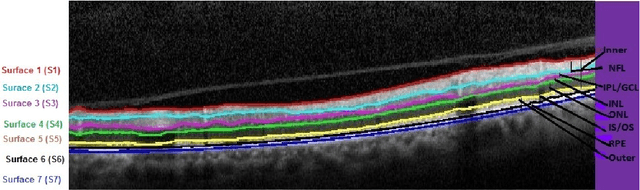
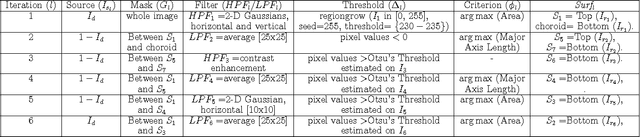
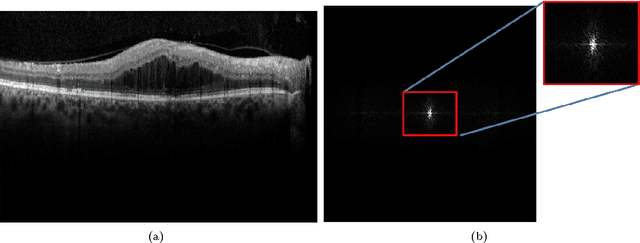
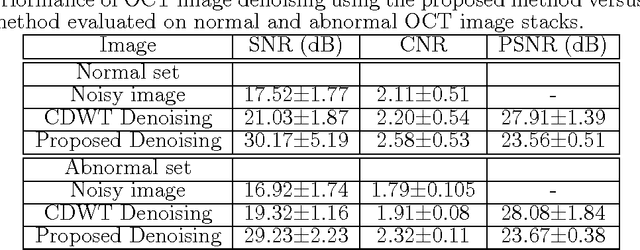
This paper presents a novel automated system that segments six sub-retinal layers from optical coherence tomography (OCT) image stacks of healthy patients and patients with diabetic macular edema (DME). First, each image in the OCT stack is denoised using a Wiener deconvolution algorithm that estimates the additive speckle noise variance using a novel Fourier-domain based structural error. This denoising method enhances the image SNR by an average of 12dB. Next, the denoised images are subjected to an iterative multi-resolution high-pass filtering algorithm that detects seven sub-retinal surfaces in six iterative steps. The thicknesses of each sub-retinal layer for all scans from a particular OCT stack are then compared to the manually marked groundtruth. The proposed system uses adaptive thresholds for denoising and segmenting each image and hence it is robust to disruptions in the retinal micro-structure due to DME. The proposed denoising and segmentation system has an average error of 1.2-5.8 $\mu m$ and 3.5-26$\mu m$ for segmenting sub-retinal surfaces in normal and abnormal images with DME, respectively. For estimating the sub-retinal layer thicknesses, the proposed system has an average error of 0.2-2.5 $\mu m$ and 1.8-18 $\mu m$ in normal and abnormal images, respectively. Additionally, the average inner sub-retinal layer thickness in abnormal images is estimated as 275$\mu m (r=0.92)$ with an average error of 9.3 $\mu m$, while the average thickness of the outer layers in abnormal images is estimated as 57.4$\mu m (r=0.74)$ with an average error of 3.5 $\mu m$. The proposed system can be useful for tracking the disease progression for DME over a period of time.
Automated Selection of Uniform Regions for CT Image Quality Detection
Aug 19, 2016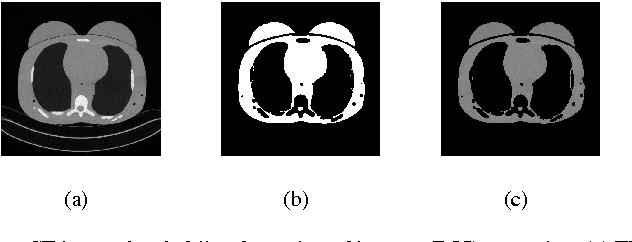

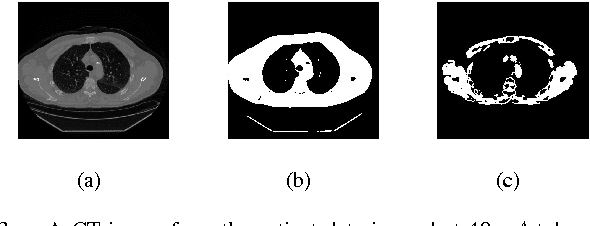

CT images are widely used in pathology detection and follow-up treatment procedures. Accurate identification of pathological features requires diagnostic quality CT images with minimal noise and artifact variation. In this work, a novel Fourier-transform based metric for image quality (IQ) estimation is presented that correlates to additive CT image noise. In the proposed method, two windowed CT image subset regions are analyzed together to identify the extent of variation in the corresponding Fourier-domain spectrum. The two square windows are chosen such that their center pixels coincide and one window is a subset of the other. The Fourier-domain spectral difference between these two sub-sampled windows is then used to isolate spatial regions-of-interest (ROI) with low signal variation (ROI-LV) and high signal variation (ROI-HV), respectively. Finally, the spatial variance ($var$), standard deviation ($std$), coefficient of variance ($cov$) and the fraction of abdominal ROI pixels in ROI-LV ($\nu'(q)$), are analyzed with respect to CT image noise. For the phantom CT images, $var$ and $std$ correlate to CT image noise ($|r|>0.76$ ($p\ll0.001$)), though not as well as $\nu'(q)$ ($r=0.96$ ($p\ll0.001$)). However, for the combined phantom and patient CT images, $var$ and $std$ do not correlate well with CT image noise ($|r|<0.46$ ($p\ll0.001$)) as compared to $\nu'(q)$ ($r=0.95$ ($p\ll0.001$)). Thus, the proposed method and the metric, $\nu'(q)$, can be useful to quantitatively estimate CT image noise.
Blind Analysis of CT Image Noise Using Residual Denoised Images
May 24, 2016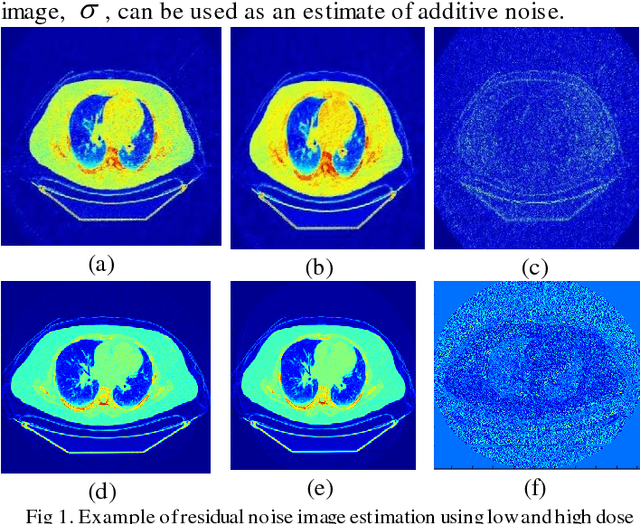
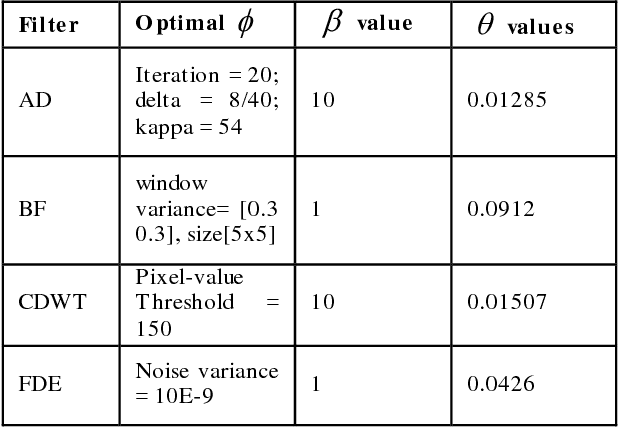
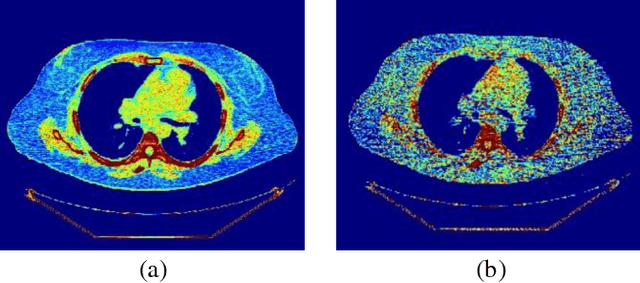
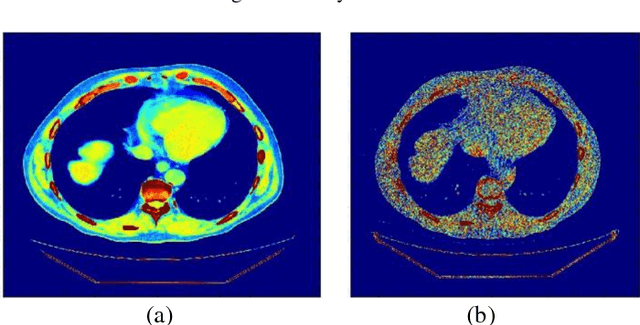
CT protocol design and quality control would benefit from automated tools to estimate the quality of generated CT images. These tools could be used to identify erroneous CT acquisitions or refine protocols to achieve certain signal to noise characteristics. This paper investigates blind estimation methods to determine global signal strength and noise levels in chest CT images. Methods: We propose novel performance metrics corresponding to the accuracy of noise and signal estimation. We implement and evaluate the noise estimation performance of six spatial- and frequency- based methods, derived from conventional image filtering algorithms. Algorithms were tested on patient data sets from whole-body repeat CT acquisitions performed with a higher and lower dose technique over the same scan region. Results: The proposed performance metrics can evaluate the relative tradeoff of filter parameters and noise estimation performance. The proposed automated methods tend to underestimate CT image noise at low-flux levels. Initial application of methodology suggests that anisotropic diffusion and Wavelet-transform based filters provide optimal estimates of noise. Furthermore, methodology does not provide accurate estimates of absolute noise levels, but can provide estimates of relative change and/or trends in noise levels.