 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer Aided Detection of Anemia-like Pallor
Mar 17, 2017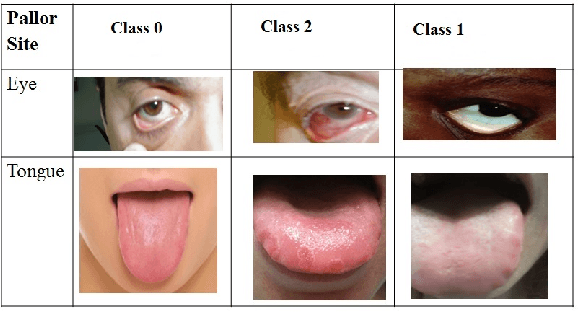
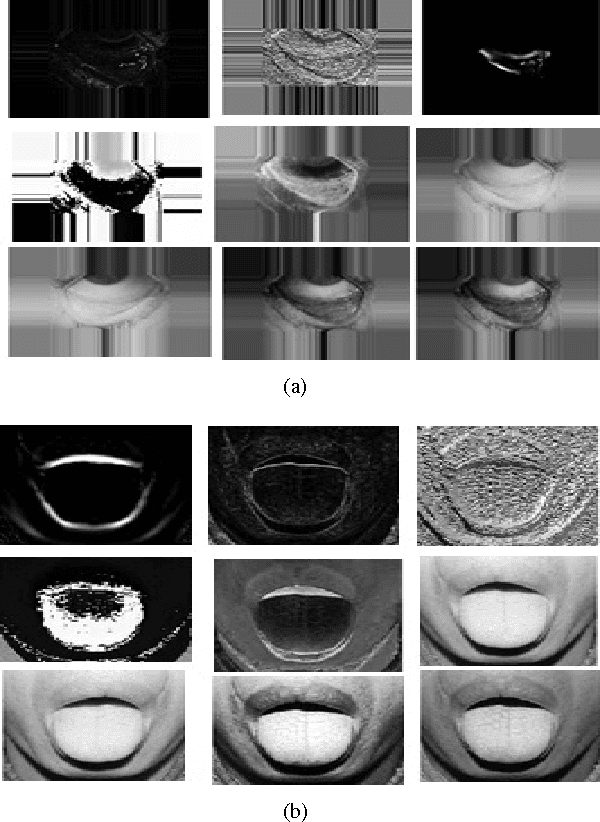
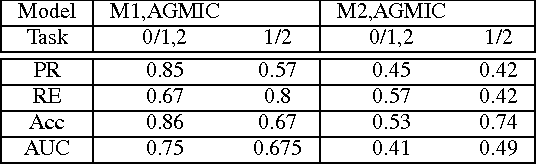
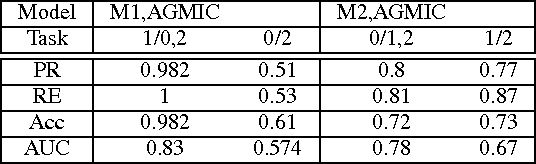
Paleness or pallor is a manifestation of blood loss or low hemoglobin concentrations in the human blood that can be caused by pathologies such as anemia. This work presents the first automated screening system that utilizes pallor site images, segments, and extracts color and intensity-based features for multi-class classification of patients with high pallor due to anemia-like pathologies, normal patients and patients with other abnormalities. This work analyzes the pallor sites of conjunctiva and tongue for anemia screening purposes. First, for the eye pallor site images, the sclera and conjunctiva regions are automatically segmented for regions of interest. Similarly, for the tongue pallor site images, the inner and outer tongue regions are segmented. Then, color-plane based feature extraction is performed followed by machine learning algorithms for feature reduction and image level classification for anemia. In this work, a suite of classification algorithms image-level classifications for normal (class 0), pallor (class 1) and other abnormalities (class 2). The proposed method achieves 86% accuracy, 85% precision and 67% recall in eye pallor site images and 98.2% accuracy and precision with 100% recall in tongue pallor site images for classification of images with pallor. The proposed pallor screening system can be further fine-tuned to detect the severity of anemia-like pathologies using controlled set of local images that can then be used for future benchmarking purposes.
A generalized flow for multi-class and binary classification tasks: An Azure ML approach
Mar 26, 2016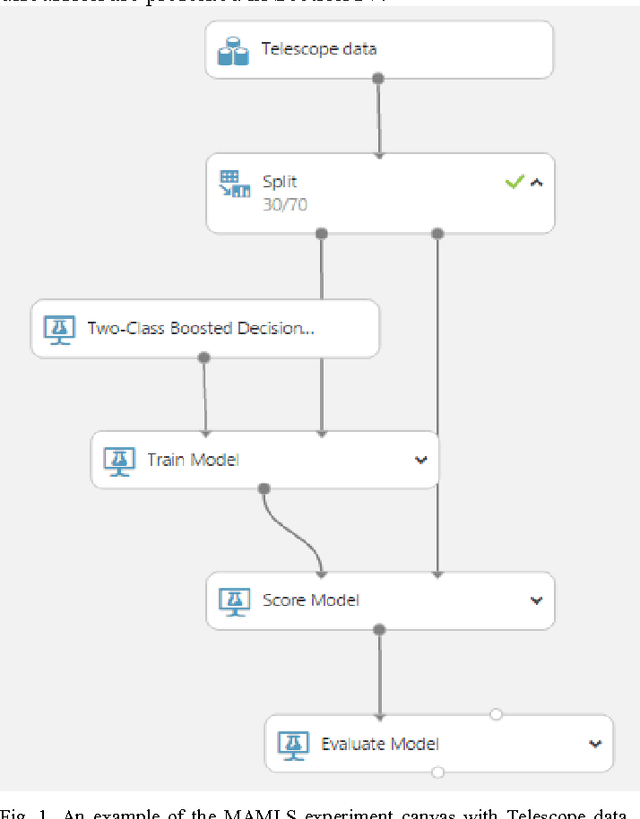
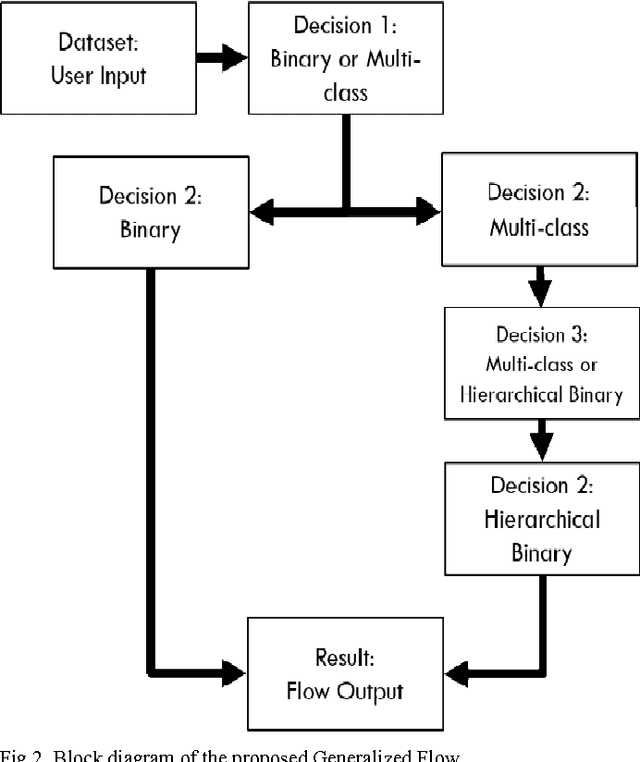
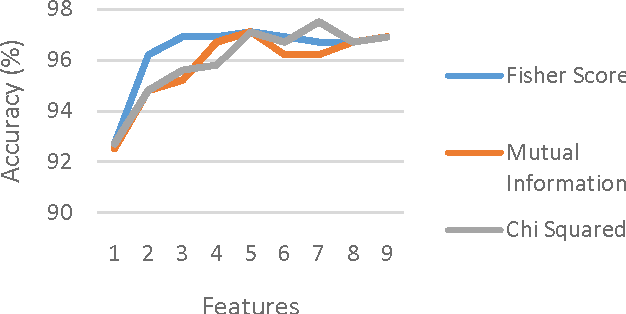
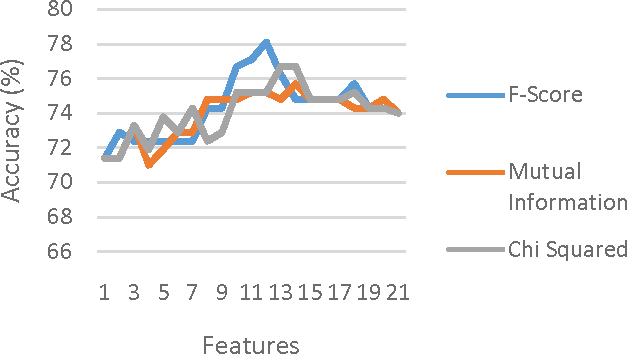
The constant growth in the present day real-world databases pose computational challenges for a single computer. Cloud-based platforms, on the other hand, are capable of handling large volumes of information manipulation tasks, thereby necessitating their use for large real-world data set computations. This work focuses on creating a novel Generalized Flow within the cloud-based computing platform: Microsoft Azure Machine Learning Studio (MAMLS) that accepts multi-class and binary classification data sets alike and processes them to maximize the overall classification accuracy. First, each data set is split into training and testing data sets, respectively. Then, linear and nonlinear classification model parameters are estimated using the training data set. Data dimensionality reduction is then performed to maximize classification accuracy. For multi-class data sets, data centric information is used to further improve overall classification accuracy by reducing the multi-class classification to a series of hierarchical binary classification tasks. Finally, the performance of optimized classification model thus achieved is evaluated and scored on the testing data set. The classification characteristics of the proposed flow are comparatively evaluated on 3 public data sets and a local data set with respect to existing state-of-the-art methods. On the 3 public data sets, the proposed flow achieves 78-97.5% classification accuracy. Also, the local data set, created using the information regarding presence of Diabetic Retinopathy lesions in fundus images, results in 85.3-95.7% average classification accuracy, which is higher than the existing methods. Thus, the proposed generalized flow can be useful for a wide range of application-oriented "big data sets".
* 10 pages, 7 figures, Conference