 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpuriosity Rankings: Sorting Data for Spurious Correlation Robustness
Dec 05, 2022



We present a framework for ranking images within their class based on the strength of spurious cues present. By measuring the gap in accuracy on the highest and lowest ranked images (we call this spurious gap), we assess spurious feature reliance for $89$ diverse ImageNet models, finding that even the best models underperform in images with weak spurious presence. However, the effect of spurious cues varies far more dramatically across classes, emphasizing the crucial, often overlooked, class-dependence of the spurious correlation problem. While most spurious features we observe are clarifying (i.e. improving test-time accuracy when present, as is typically expected), we surprisingly find many cases of confusing spurious features, where models perform better when they are absent. We then close the spurious gap by training new classification heads on lowly ranked (i.e. without common spurious cues) images, resulting in improved effective robustness to distribution shifts (ObjectNet, ImageNet-R, ImageNet-Sketch). We also propose a second metric to assess feature reliability, finding that spurious features are generally less reliable than non-spurious (core) ones, though again, spurious features can be more reliable for certain classes. To enable our analysis, we annotated $5,000$ feature-class dependencies over {\it all} of ImageNet as core or spurious using minimal human supervision. Finally, we show the feature discovery and spuriosity ranking framework can be extended to other datasets like CelebA and WaterBirds in a lightweight fashion with only linear layer training, leading to discovering a previously unknown racial bias in the Celeb-A hair classification.
Towards Better Input Masking for Convolutional Neural Networks
Nov 26, 2022The ability to remove features from the input of machine learning models is very important to understand and interpret model predictions. However, this is non-trivial for vision models since masking out parts of the input image and replacing them with a baseline color like black or grey typically causes large distribution shifts. Masking may even make the model focus on the masking patterns for its prediction rather than the unmasked portions of the image. In recent work, it has been shown that vision transformers are less affected by such issues as one can simply drop the tokens corresponding to the masked image portions. They are thus more easily interpretable using techniques like LIME which rely on input perturbation. Using the same intuition, we devise a masking technique for CNNs called layer masking, which simulates running the CNN on only the unmasked input. We find that our method is (i) much less disruptive to the model's output and its intermediate activations, and (ii) much better than commonly used masking techniques for input perturbation based interpretability techniques like LIME. Thus, layer masking is able to close the interpretability gap between CNNs and transformers, and even make CNNs more interpretable in many cases.
Invariant Learning via Diffusion Dreamed Distribution Shifts
Nov 18, 2022Though the background is an important signal for image classification, over reliance on it can lead to incorrect predictions when spurious correlations between foreground and background are broken at test time. Training on a dataset where these correlations are unbiased would lead to more robust models. In this paper, we propose such a dataset called Diffusion Dreamed Distribution Shifts (D3S). D3S consists of synthetic images generated through StableDiffusion using text prompts and image guides obtained by pasting a sample foreground image onto a background template image. Using this scalable approach we generate 120K images of objects from all 1000 ImageNet classes in 10 diverse backgrounds. Due to the incredible photorealism of the diffusion model, our images are much closer to natural images than previous synthetic datasets. D3S contains a validation set of more than 17K images whose labels are human-verified in an MTurk study. Using the validation set, we evaluate several popular DNN image classifiers and find that the classification performance of models generally suffers on our background diverse images. Next, we leverage the foreground & background labels in D3S to learn a foreground (background) representation that is invariant to changes in background (foreground) by penalizing the mutual information between the foreground (background) features and the background (foreground) labels. Linear classifiers trained on these features to predict foreground (background) from foreground (background) have high accuracies at 82.9% (93.8%), while classifiers that predict these labels from background and foreground have a much lower accuracy of 2.4% and 45.6% respectively. This suggests that our foreground and background features are well disentangled. We further test the efficacy of these representations by training classifiers on a task with strong spurious correlations.
Improved techniques for deterministic l2 robustness
Nov 15, 2022



Training convolutional neural networks (CNNs) with a strict 1-Lipschitz constraint under the $l_{2}$ norm is useful for adversarial robustness, interpretable gradients and stable training. 1-Lipschitz CNNs are usually designed by enforcing each layer to have an orthogonal Jacobian matrix (for all inputs) to prevent the gradients from vanishing during backpropagation. However, their performance often significantly lags behind that of heuristic methods to enforce Lipschitz constraints where the resulting CNN is not \textit{provably} 1-Lipschitz. In this work, we reduce this gap by introducing (a) a procedure to certify robustness of 1-Lipschitz CNNs by replacing the last linear layer with a 1-hidden layer MLP that significantly improves their performance for both standard and provably robust accuracy, (b) a method to significantly reduce the training time per epoch for Skew Orthogonal Convolution (SOC) layers (>30\% reduction for deeper networks) and (c) a class of pooling layers using the mathematical property that the $l_{2}$ distance of an input to a manifold is 1-Lipschitz. Using these methods, we significantly advance the state-of-the-art for standard and provable robust accuracies on CIFAR-10 (gains of +1.79\% and +3.82\%) and similarly on CIFAR-100 (+3.78\% and +4.75\%) across all networks. Code is available at \url{https://github.com/singlasahil14/improved_l2_robustness}.
Explicit Tradeoffs between Adversarial and Natural Distributional Robustness
Sep 15, 2022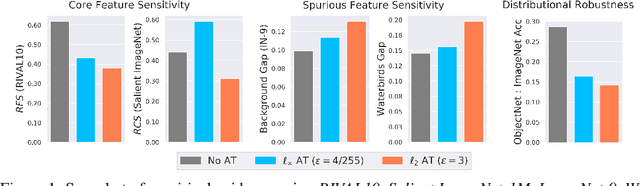
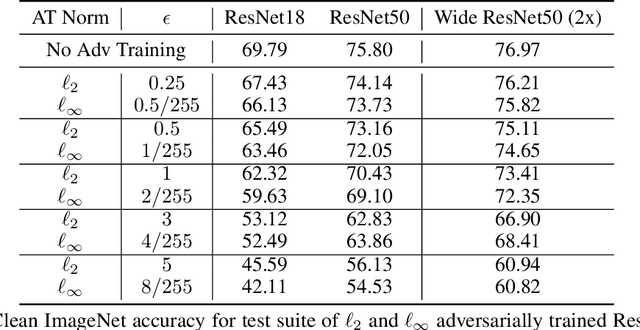
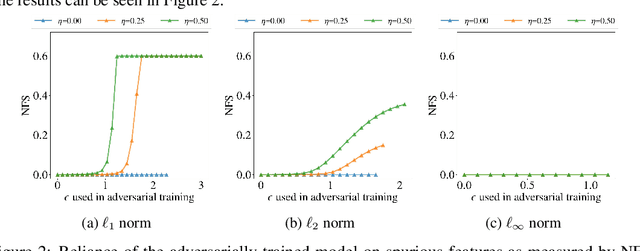

Several existing works study either adversarial or natural distributional robustness of deep neural networks separately. In practice, however, models need to enjoy both types of robustness to ensure reliability. In this work, we bridge this gap and show that in fact, explicit tradeoffs exist between adversarial and natural distributional robustness. We first consider a simple linear regression setting on Gaussian data with disjoint sets of core and spurious features. In this setting, through theoretical and empirical analysis, we show that (i) adversarial training with $\ell_1$ and $\ell_2$ norms increases the model reliance on spurious features; (ii) For $\ell_\infty$ adversarial training, spurious reliance only occurs when the scale of the spurious features is larger than that of the core features; (iii) adversarial training can have an unintended consequence in reducing distributional robustness, specifically when spurious correlations are changed in the new test domain. Next, we present extensive empirical evidence, using a test suite of twenty adversarially trained models evaluated on five benchmark datasets (ObjectNet, RIVAL10, Salient ImageNet-1M, ImageNet-9, Waterbirds), that adversarially trained classifiers rely on backgrounds more than their standardly trained counterparts, validating our theoretical results. We also show that spurious correlations in training data (when preserved in the test domain) can improve adversarial robustness, revealing that previous claims that adversarial vulnerability is rooted in spurious correlations are incomplete.
Goal-Conditioned Q-Learning as Knowledge Distillation
Aug 28, 2022

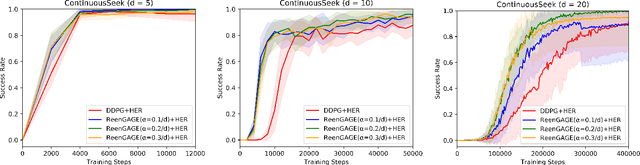

Many applications of reinforcement learning can be formalized as goal-conditioned environments, where, in each episode, there is a "goal" that affects the rewards obtained during that episode but does not affect the dynamics. Various techniques have been proposed to improve performance in goal-conditioned environments, such as automatic curriculum generation and goal relabeling. In this work, we explore a connection between off-policy reinforcement learning in goal-conditioned settings and knowledge distillation. In particular: the current Q-value function and the target Q-value estimate are both functions of the goal, and we would like to train the Q-value function to match its target for all goals. We therefore apply Gradient-Based Attention Transfer (Zagoruyko and Komodakis 2017), a knowledge distillation technique, to the Q-function update. We empirically show that this can improve the performance of goal-conditioned off-policy reinforcement learning when the space of goals is high-dimensional. We also show that this technique can be adapted to allow for efficient learning in the case of multiple simultaneous sparse goals, where the agent can attain a reward by achieving any one of a large set of objectives, all specified at test time. Finally, to provide theoretical support, we give examples of classes of environments where (under some assumptions) standard off-policy algorithms require at least O(d^2) observed transitions to learn an optimal policy, while our proposed technique requires only O(d) transitions, where d is the dimensionality of the goal and state space.
Lethal Dose Conjecture on Data Poisoning
Aug 05, 2022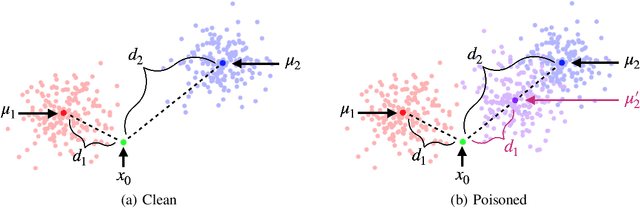
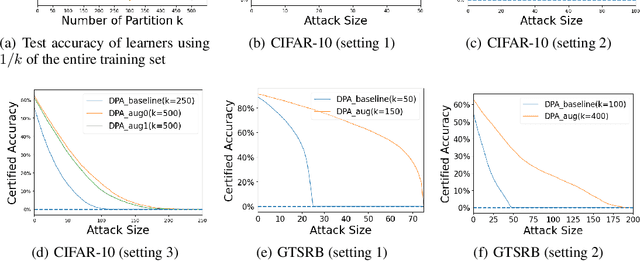
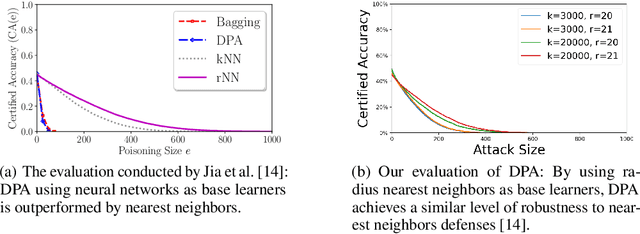
Data poisoning considers an adversary that distorts the training set of machine learning algorithms for malicious purposes. In this work, we bring to light one conjecture regarding the fundamentals of data poisoning, which we call the Lethal Dose Conjecture. The conjecture states: If $n$ clean training samples are needed for accurate predictions, then in a size-$N$ training set, only $\Theta(N/n)$ poisoned samples can be tolerated while ensuring accuracy. Theoretically, we verify this conjecture in multiple cases. We also offer a more general perspective of this conjecture through distribution discrimination. Deep Partition Aggregation (DPA) and its extension, Finite Aggregation (FA) are recent approaches for provable defenses against data poisoning, where they predict through the majority vote of many base models trained from different subsets of training set using a given learner. The conjecture implies that both DPA and FA are (asymptotically) optimal -- if we have the most data-efficient learner, they can turn it into one of the most robust defenses against data poisoning. This outlines a practical approach to developing stronger defenses against poisoning via finding data-efficient learners. Empirically, as a proof of concept, we show that by simply using different data augmentations for base learners, we can respectively double and triple the certified robustness of DPA on CIFAR-10 and GTSRB without sacrificing accuracy.
Certifiably Robust Policy Learning against Adversarial Communication in Multi-agent Systems
Jul 02, 2022
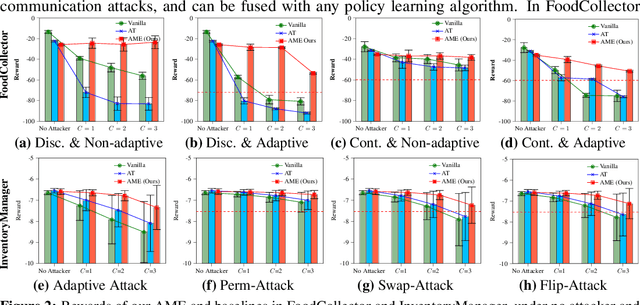
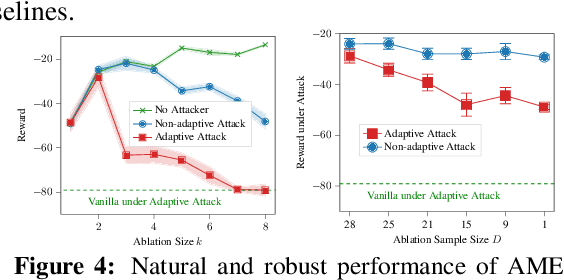
Communication is important in many multi-agent reinforcement learning (MARL) problems for agents to share information and make good decisions. However, when deploying trained communicative agents in a real-world application where noise and potential attackers exist, the safety of communication-based policies becomes a severe issue that is underexplored. Specifically, if communication messages are manipulated by malicious attackers, agents relying on untrustworthy communication may take unsafe actions that lead to catastrophic consequences. Therefore, it is crucial to ensure that agents will not be misled by corrupted communication, while still benefiting from benign communication. In this work, we consider an environment with $N$ agents, where the attacker may arbitrarily change the communication from any $C<\frac{N-1}{2}$ agents to a victim agent. For this strong threat model, we propose a certifiable defense by constructing a message-ensemble policy that aggregates multiple randomly ablated message sets. Theoretical analysis shows that this message-ensemble policy can utilize benign communication while being certifiably robust to adversarial communication, regardless of the attacking algorithm. Experiments in multiple environments verify that our defense significantly improves the robustness of trained policies against various types of attacks.
Interpretable Mixture of Experts for Structured Data
Jun 05, 2022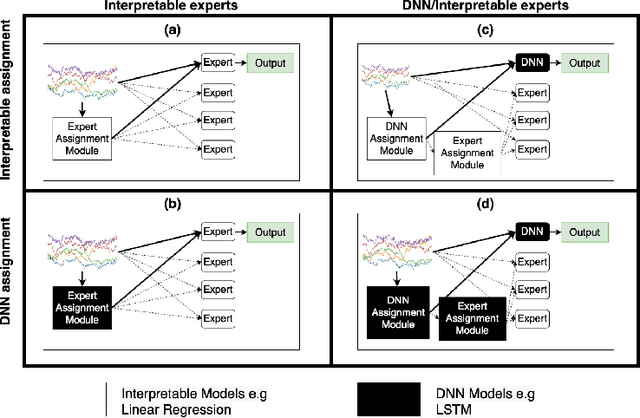
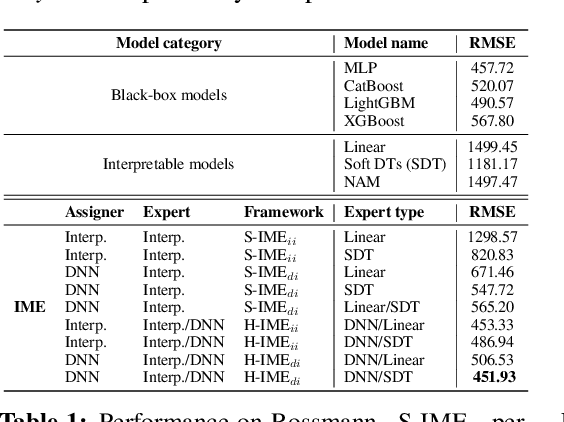
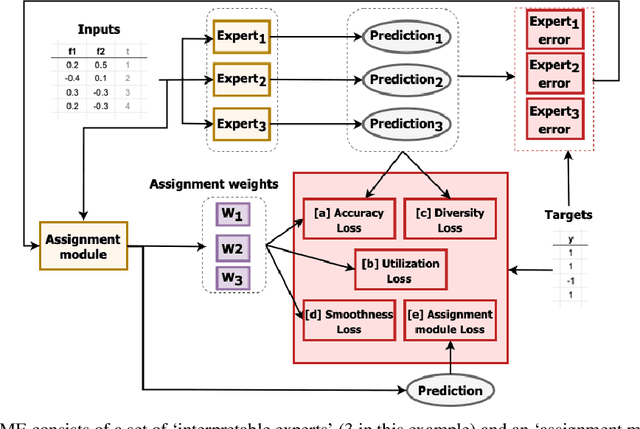
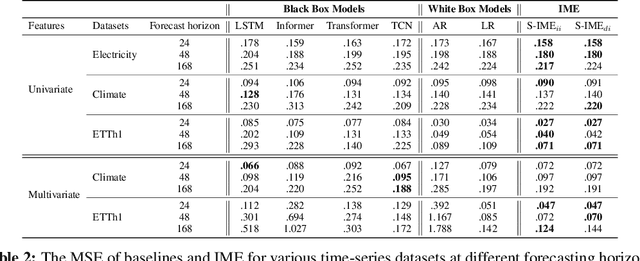
With the growth of machine learning for structured data, the need for reliable model explanations is essential, especially in high-stakes applications. We introduce a novel framework, Interpretable Mixture of Experts (IME), that provides interpretability for structured data while preserving accuracy. IME consists of an assignment module and a mixture of interpretable experts such as linear models where each sample is assigned to a single interpretable expert. This results in an inherently-interpretable architecture where the explanations produced by IME are the exact descriptions of how the prediction is computed. In addition to constituting a standalone inherently-interpretable architecture, an additional IME capability is that it can be integrated with existing Deep Neural Networks (DNNs) to offer interpretability to a subset of samples while maintaining the accuracy of the DNNs. Experiments on various structured datasets demonstrate that IME is more accurate than a single interpretable model and performs comparably to existing state-of-the-art deep learning models in terms of accuracy while providing faithful explanations.
Core Risk Minimization using Salient ImageNet
Mar 28, 2022


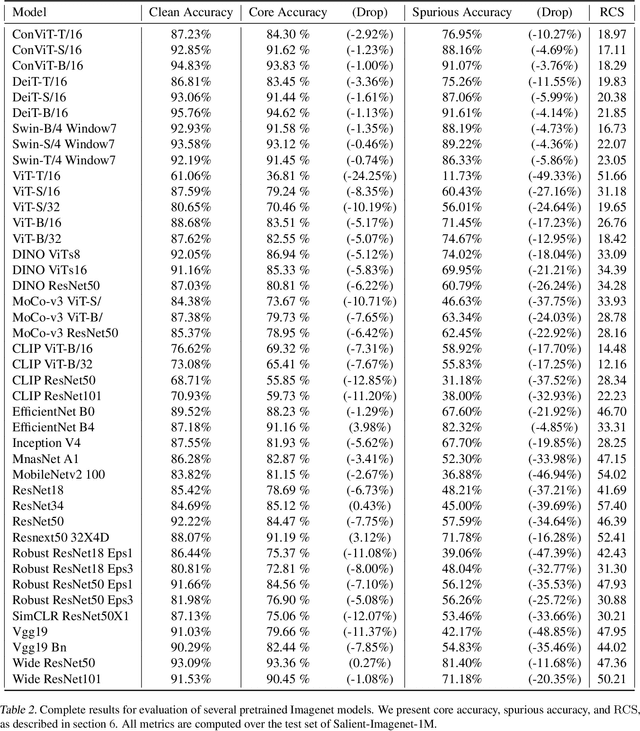
Deep neural networks can be unreliable in the real world especially when they heavily use spurious features for their predictions. Recently, Singla & Feizi (2022) introduced the Salient Imagenet dataset by annotating and localizing core and spurious features of ~52k samples from 232 classes of Imagenet. While this dataset is useful for evaluating the reliance of pretrained models on spurious features, its small size limits its usefulness for training models. In this work, we first introduce the Salient Imagenet-1M dataset with more than 1 million soft masks localizing core and spurious features for all 1000 Imagenet classes. Using this dataset, we first evaluate the reliance of several Imagenet pretrained models (42 total) on spurious features and observe that: (i) transformers are more sensitive to spurious features compared to Convnets, (ii) zero-shot CLIP transformers are highly susceptible to spurious features. Next, we introduce a new learning paradigm called Core Risk Minimization (CoRM) whose objective ensures that the model predicts a class using its core features. We evaluate different computational approaches for solving CoRM and achieve significantly higher (+12%) core accuracy (accuracy when non-core regions corrupted using noise) with no drop in clean accuracy compared to models trained via Empirical Risk Minimization.