 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatch Me If You Can: Semi-supervised Graph Learning for Spotting Money Laundering
Feb 24, 2023



Money laundering is the process where criminals use financial services to move massive amounts of illegal money to untraceable destinations and integrate them into legitimate financial systems. It is very crucial to identify such activities accurately and reliably in order to enforce an anti-money laundering (AML). Despite tremendous efforts to AML only a tiny fraction of illicit activities are prevented. From a given graph of money transfers between accounts of a bank, existing approaches attempted to detect money laundering. In particular, some approaches employ structural and behavioural dynamics of dense subgraph detection thereby not taking into consideration that money laundering involves high-volume flows of funds through chains of bank accounts. Some approaches model the transactions in the form of multipartite graphs to detect the complete flow of money from source to destination. However, existing approaches yield lower detection accuracy, making them less reliable. In this paper, we employ semi-supervised graph learning techniques on graphs of financial transactions in order to identify nodes involved in potential money laundering. Experimental results suggest that our approach can sport money laundering from real and synthetic transaction graphs.
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Feb 17, 2023



Africa is home to over 2000 languages from over six language families and has the highest linguistic diversity among all continents. This includes 75 languages with at least one million speakers each. Yet, there is little NLP research conducted on African languages. Crucial in enabling such research is the availability of high-quality annotated datasets. In this paper, we introduce AfriSenti, which consists of 14 sentiment datasets of 110,000+ tweets in 14 African languages (Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a) from four language families annotated by native speakers. The data is used in SemEval 2023 Task 12, the first Afro-centric SemEval shared task. We describe the data collection methodology, annotation process, and related challenges when curating each of the datasets. We conduct experiments with different sentiment classification baselines and discuss their usefulness. We hope AfriSenti enables new work on under-represented languages. The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023 and can also be loaded as a huggingface datasets (https://huggingface.co/datasets/shmuhammad/AfriSenti).
Interpreting Black-box Machine Learning Models for High Dimensional Datasets
Aug 29, 2022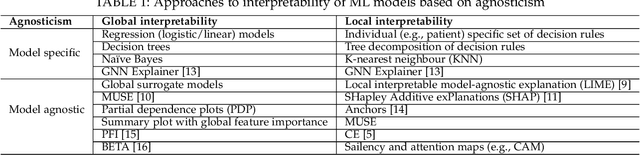
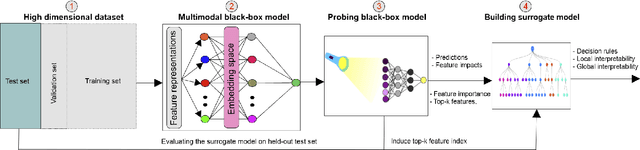
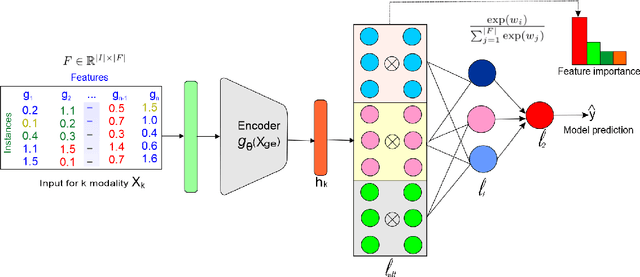
Deep neural networks (DNNs) have been shown to outperform traditional machine learning algorithms in a broad variety of application domains due to their effectiveness in modeling intricate problems and handling high-dimensional datasets. Many real-life datasets, however, are of increasingly high dimensionality, where a large number of features may be irrelevant to the task at hand. The inclusion of such features would not only introduce unwanted noise but also increase computational complexity. Furthermore, due to high non-linearity and dependency among a large number of features, DNN models tend to be unavoidably opaque and perceived as black-box methods because of their not well-understood internal functioning. A well-interpretable model can identify statistically significant features and explain the way they affect the model's outcome. In this paper, we propose an efficient method to improve the interpretability of black-box models for classification tasks in the case of high-dimensional datasets. To this end, we first train a black-box model on a high-dimensional dataset to learn the embeddings on which the classification is performed. To decompose the inner working principles of the black-box model and to identify top-k important features, we employ different probing and perturbing techniques. We then approximate the behavior of the black-box model by means of an interpretable surrogate model on the top-k feature space. Finally, we derive decision rules and local explanations from the surrogate model to explain individual decisions. Our approach outperforms and competes with state-of-the-art methods such as TabNet, XGboost, and SHAP-based interpretability techniques when tested on different datasets with varying dimensionality between 50 and 20,000.