 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-aware IoU for Anchor Assignment in Real-time Instance Segmentation
Oct 19, 2021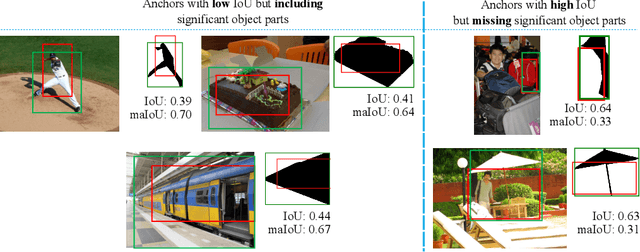
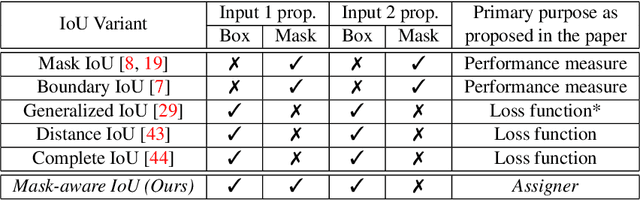
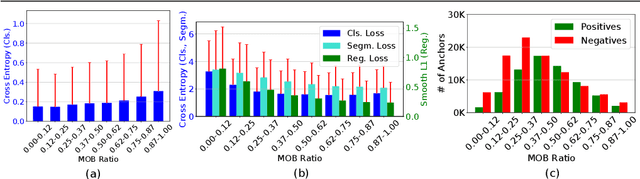
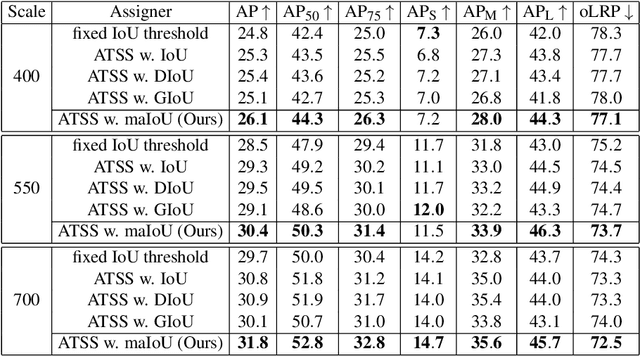
This paper presents Mask-aware Intersection-over-Union (maIoU) for assigning anchor boxes as positives and negatives during training of instance segmentation methods. Unlike conventional IoU or its variants, which only considers the proximity of two boxes; maIoU consistently measures the proximity of an anchor box with not only a ground truth box but also its associated ground truth mask. Thus, additionally considering the mask, which, in fact, represents the shape of the object, maIoU enables a more accurate supervision during training. We present the effectiveness of maIoU on a state-of-the-art (SOTA) assigner, ATSS, by replacing IoU operation by our maIoU and training YOLACT, a SOTA real-time instance segmentation method. Using ATSS with maIoU consistently outperforms (i) ATSS with IoU by $\sim 1$ mask AP, (ii) baseline YOLACT with fixed IoU threshold assigner by $\sim 2$ mask AP over different image sizes and (iii) decreases the inference time by $25 \%$ owing to using less anchors. Then, exploiting this efficiency, we devise maYOLACT, a faster and $+6$ AP more accurate detector than YOLACT. Our best model achieves $37.7$ mask AP at $25$ fps on COCO test-dev establishing a new state-of-the-art for real-time instance segmentation. Code is available at https://github.com/kemaloksuz/Mask-aware-IoU
Rank & Sort Loss for Object Detection and Instance Segmentation
Jul 24, 2021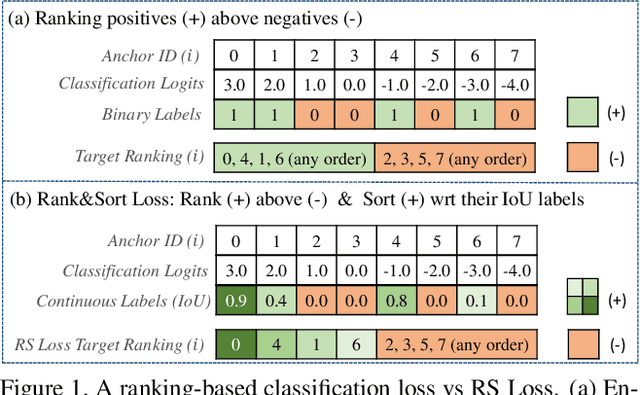
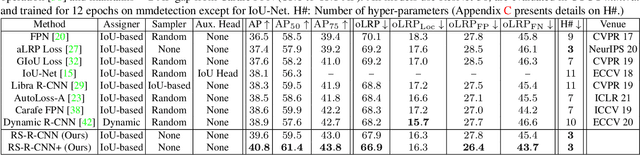
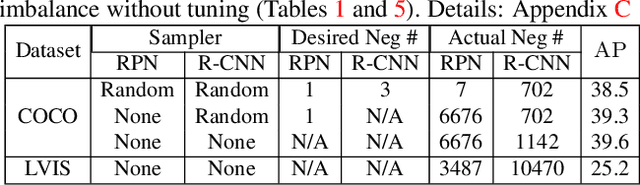
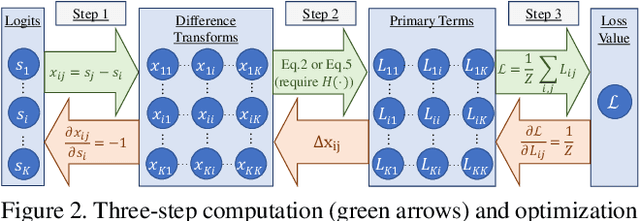
We propose Rank & Sort (RS) Loss, as a ranking-based loss function to train deep object detection and instance segmentation methods (i.e. visual detectors). RS Loss supervises the classifier, a sub-network of these methods, to rank each positive above all negatives as well as to sort positives among themselves with respect to (wrt.) their continuous localisation qualities (e.g. Intersection-over-Union - IoU). To tackle the non-differentiable nature of ranking and sorting, we reformulate the incorporation of error-driven update with backpropagation as Identity Update, which enables us to model our novel sorting error among positives. With RS Loss, we significantly simplify training: (i) Thanks to our sorting objective, the positives are prioritized by the classifier without an additional auxiliary head (e.g. for centerness, IoU, mask-IoU), (ii) due to its ranking-based nature, RS Loss is robust to class imbalance, and thus, no sampling heuristic is required, and (iii) we address the multi-task nature of visual detectors using tuning-free task-balancing coefficients. Using RS Loss, we train seven diverse visual detectors only by tuning the learning rate, and show that it consistently outperforms baselines: e.g. our RS Loss improves (i) Faster R-CNN by ~ 3 box AP and aLRP Loss (ranking-based baseline) by ~ 2 box AP on COCO dataset, (ii) Mask R-CNN with repeat factor sampling (RFS) by 3.5 mask AP (~ 7 AP for rare classes) on LVIS dataset; and also outperforms all counterparts. Code available at https://github.com/kemaloksuz/RankSortLoss
One Metric to Measure them All: Localisation Recall Precision for Evaluating Visual Detection Tasks
Nov 21, 2020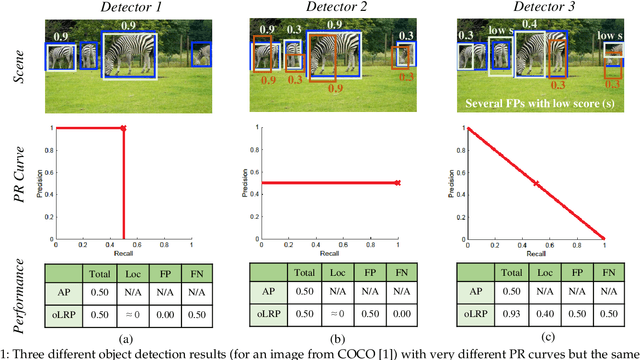

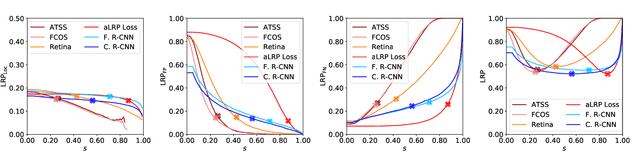
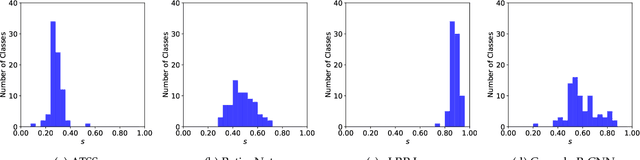
Despite being widely used as a performance measure for visual detection tasks, Average Precision (AP) is limited in (i) including localisation quality, (ii) interpretability and (iii) applicability to outputs without confidence scores. Panoptic Quality (PQ), a measure proposed for evaluating panoptic segmentation (Kirillov et al., 2019), does not suffer from these limitations but is limited to panoptic segmentation. In this paper, we propose Localisation Recall Precision (LRP) Error as the performance measure for all visual detection tasks. LRP Error, initially proposed only for object detection by Oksuz et al. (2018), does not suffer from the aforementioned limitations and is applicable to all visual detection tasks. We also introduce Optimal LRP (oLRP) Error as the minimum LRP error obtained over confidence scores to evaluate visual detectors and obtain optimal thresholds for deployment. We provide a detailed comparative analysis of LRP with AP and PQ, and use 35 state-of-the-art visual detectors from four common visual detection tasks (i.e. object detection, keypoint detection, instance segmentation and panoptic segmentation) to empirically show that LRP provides richer and more discriminative information than its counterparts. Code available at: https://github.com/kemaloksuz/LRP-Error
Spatio-Temporal Analysis of Facial Actions using Lifecycle-Aware Capsule Networks
Nov 17, 2020Most state-of-the-art approaches for Facial Action Unit (AU) detection rely upon evaluating facial expressions from static frames, encoding a snapshot of heightened facial activity. In real-world interactions, however, facial expressions are usually more subtle and evolve in a temporal manner requiring AU detection models to learn spatial as well as temporal information. In this paper, we focus on both spatial and spatio-temporal features encoding the temporal evolution of facial AU activation. For this purpose, we propose the Action Unit Lifecycle-Aware Capsule Network (AULA-Caps) that performs AU detection using both frame and sequence-level features. While at the frame-level the capsule layers of AULA-Caps learn spatial feature primitives to determine AU activations, at the sequence-level, it learns temporal dependencies between contiguous frames by focusing on relevant spatio-temporal segments in the sequence. The learnt feature capsules are routed together such that the model learns to selectively focus more on spatial or spatio-temporal information depending upon the AU lifecycle. The proposed model is evaluated on the commonly used BP4D and GFT benchmark datasets obtaining state-of-the-art results on both the datasets.
Transformer-Encoder Detector Module: Using Context to Improve Robustness to Adversarial Attacks on Object Detection
Nov 13, 2020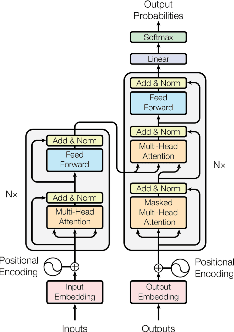
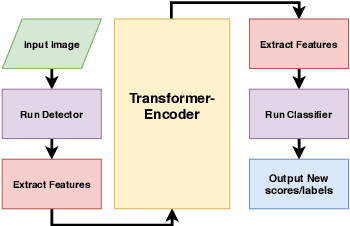


Deep neural network approaches have demonstrated high performance in object recognition (CNN) and detection (Faster-RCNN) tasks, but experiments have shown that such architectures are vulnerable to adversarial attacks (FFF, UAP): low amplitude perturbations, barely perceptible by the human eye, can lead to a drastic reduction in labeling performance. This article proposes a new context module, called \textit{Transformer-Encoder Detector Module}, that can be applied to an object detector to (i) improve the labeling of object instances; and (ii) improve the detector's robustness to adversarial attacks. The proposed model achieves higher mAP, F1 scores and AUC average score of up to 13\% compared to the baseline Faster-RCNN detector, and an mAP score 8 points higher on images subjected to FFF or UAP attacks due to the inclusion of both contextual and visual features extracted from scene and encoded into the model. The result demonstrates that a simple ad-hoc context module can improve the reliability of object detectors significantly.
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection
Oct 23, 2020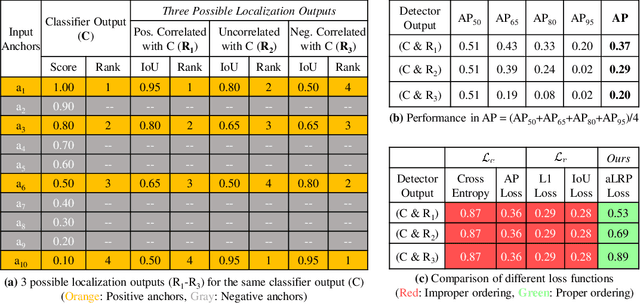

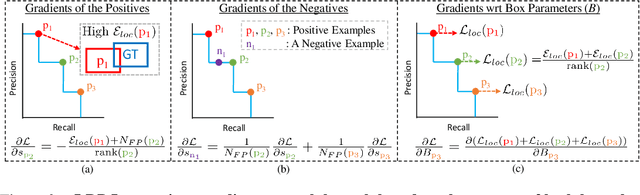

We propose \textit{average Localisation-Recall-Precision} (aLRP), a unified, bounded, balanced and ranking-based loss function for both classification and localisation tasks in object detection. aLRP extends the Localisation-Recall-Precision (LRP) performance metric (Oksuz et al., 2018) inspired from how Average Precision (AP) Loss extends precision to a ranking-based loss function for classification (Chen et al., 2020). aLRP has the following distinct advantages: (i) aLRP is the first ranking-based loss function for both classification and localisation tasks. (ii) Thanks to using ranking for both tasks, aLRP naturally enforces high-quality localisation for high-precision classification. (iii) aLRP provides provable balance between positives and negatives. (iv) Compared to on average $\sim$6 hyperparameters in the loss functions of state-of-the-art detectors, aLRP Loss has only one hyperparameter, which we did not tune in practice. On the COCO dataset, aLRP Loss improves its ranking-based predecessor, AP Loss, up to around $5$ AP points, achieves $48.9$ AP without test time augmentation and outperforms all one-stage detectors. Code available at: https://github.com/kemaloksuz/aLRPLoss .
Investigating Bias and Fairness in Facial Expression Recognition
Aug 21, 2020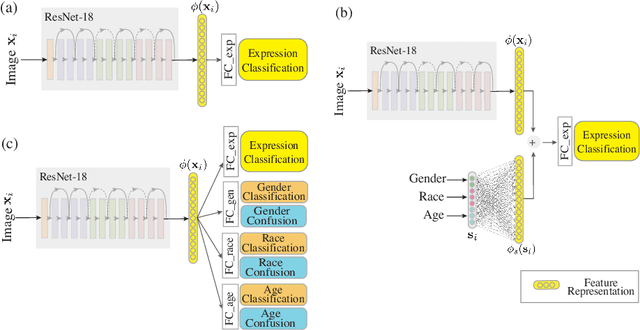
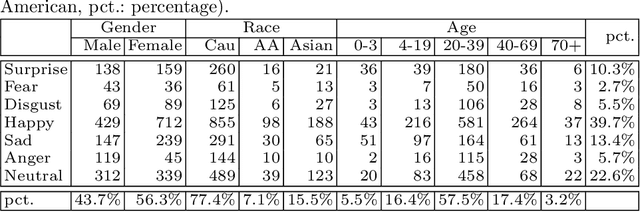
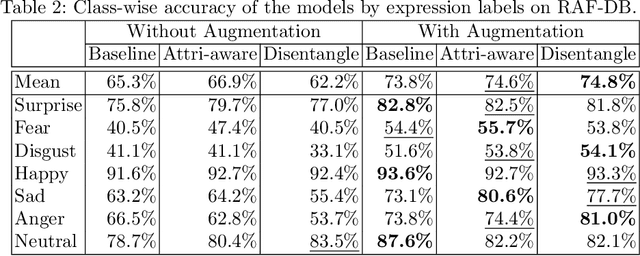
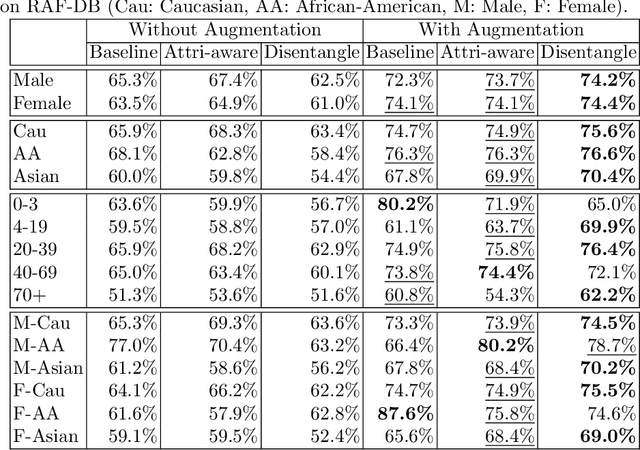
Recognition of expressions of emotions and affect from facial images is a well-studied research problem in the fields of affective computing and computer vision with a large number of datasets available containing facial images and corresponding expression labels. However, virtually none of these datasets have been acquired with consideration of fair distribution across the human population. Therefore, in this work, we undertake a systematic investigation of bias and fairness in facial expression recognition by comparing three different approaches, namely a baseline, an attribute-aware and a disentangled approach, on two well-known datasets, RAF-DB and CelebA. Our results indicate that: (i) data augmentation improves the accuracy of the baseline model, but this alone is unable to mitigate the bias effect; (ii) both the attribute-aware and the disentangled approaches fortified with data augmentation perform better than the baseline approach in terms of accuracy and fairness; (iii) the disentangled approach is the best for mitigating demographic bias; and (iv) the bias mitigation strategies are more suitable in the existence of uneven attribute distribution or imbalanced number of subgroup data.
Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition
Aug 19, 2020


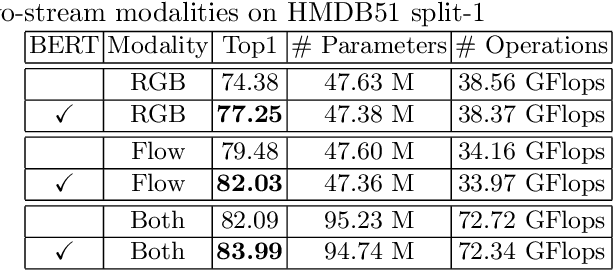
In this work, we combine 3D convolution with late temporal modeling for action recognition. For this aim, we replace the conventional Temporal Global Average Pooling (TGAP) layer at the end of 3D convolutional architecture with the Bidirectional Encoder Representations from Transformers (BERT) layer in order to better utilize the temporal information with BERT's attention mechanism. We show that this replacement improves the performances of many popular 3D convolution architectures for action recognition, including ResNeXt, I3D, SlowFast and R(2+1)D. Moreover, we provide the-state-of-the-art results on both HMDB51 and UCF101 datasets with 85.10% and 98.69% top-1 accuracy, respectively. The code is publicly available.
Mind Your Manners! A Dataset and A Continual Learning Approach for Assessing Social Appropriateness of Robot Actions
Jul 24, 2020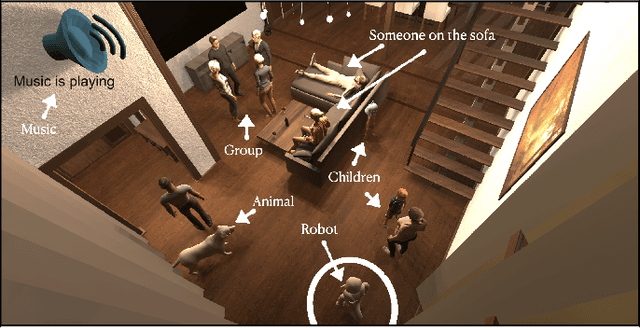
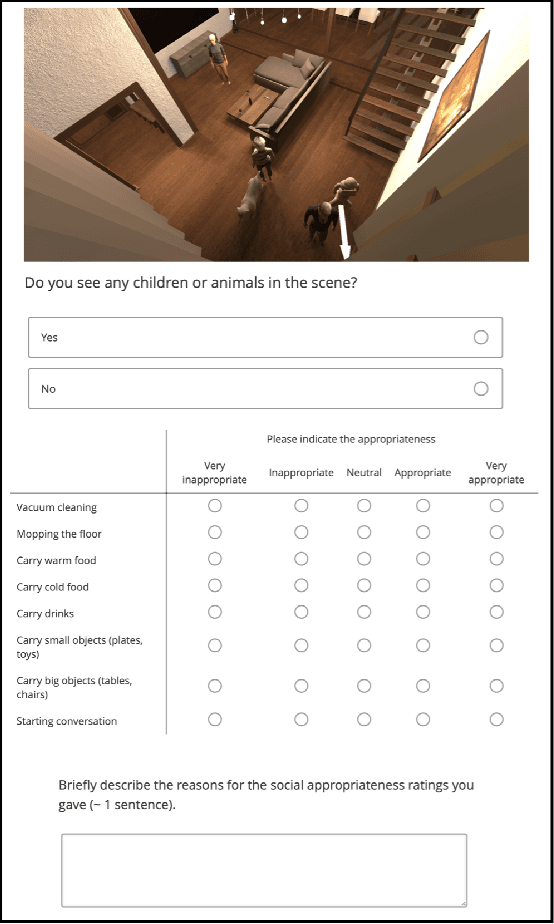
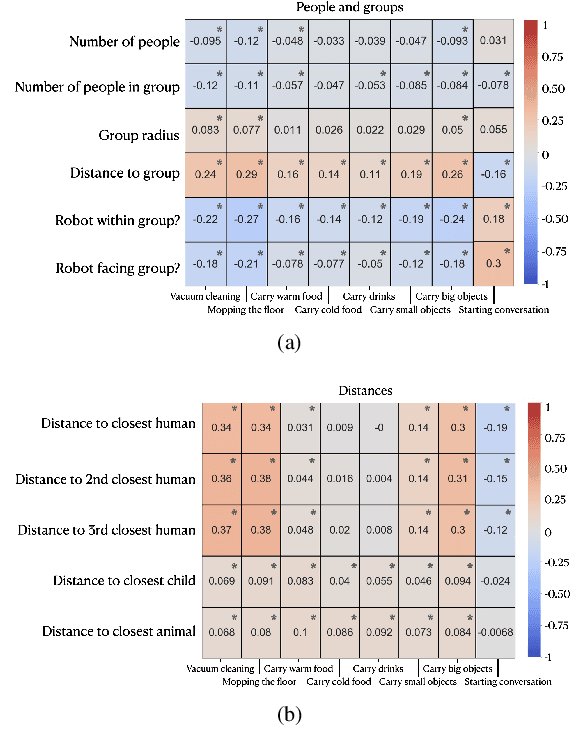
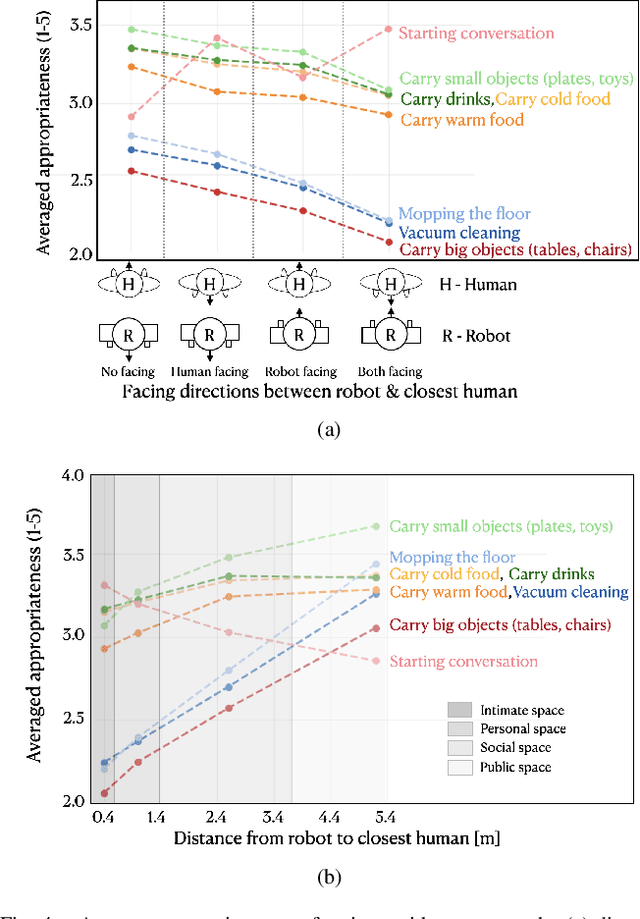
To date, endowing robots with an ability to assess social appropriateness of their actions has not been possible. This has been mainly due to (i) the lack of relevant and labelled data, and (ii) the lack of formulations of this as a lifelong learning problem. In this paper, we address these two issues. We first introduce the Socially Appropriate Domestic Robot Actions dataset (MANNERS-DB), which contains appropriateness labels of robot actions annotated by humans. To be able to control but vary the configurations of the scenes and the social settings, MANNERS-DB has been created utilising a simulation environment by uniformly sampling relevant contextual attributes. Secondly, we train and evaluate a baseline Bayesian Neural Network (BNN) that estimates social appropriateness of actions in the MANNERS-DB. Finally, we formulate learning social appropriateness of actions as a continual learning problem using the uncertainty of the BNN parameters. The experimental results show that the social appropriateness of robot actions can be predicted with a satisfactory level of precision. Our work takes robots one step closer to a human-like understanding of (social) appropriateness of actions, with respect to the social context they operate in. To facilitate reproducibility and further progress in this area, the MANNERS-DB, the trained models and the relevant code will be made publicly available.
ALET : A Dataset, a Baseline and a Usecase for Tool Detection in the Wild
Oct 25, 2019
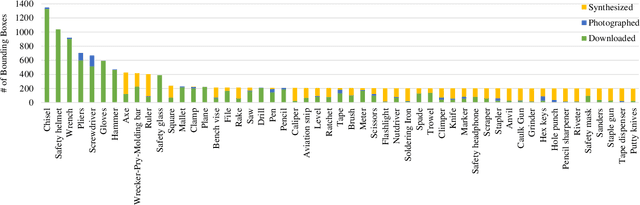

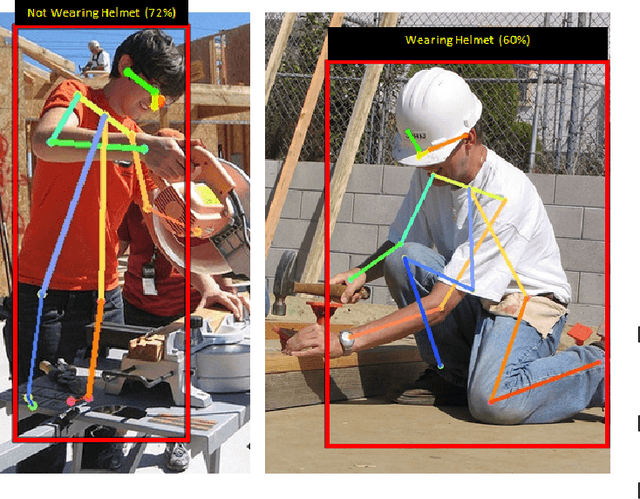
Robots collaborating with humans in realistic environments will need to be able to detect the tools that can be used and manipulated. However, there is no available dataset or study that addresses this challenge in real settings. In this paper, we fill this gap by providing an extensive dataset (METU-ALET) for detecting farming, gardening, office, stonemasonry, vehicle, woodworking and workshop tools. The scenes correspond to sophisticated environments with or without humans using the tools. The scenes we consider introduce several challenges for object detection, including the small scale of the tools, their articulated nature, occlusion, inter-class invariance, etc. Moreover, we train and compare several state of the art deep object detectors (including Faster R-CNN, YOLO and RetinaNet) on our dataset. We observe that the detectors have difficulty in detecting especially small-scale tools or tools that are visually similar to parts of other tools. This in turn supports the importance of our dataset and paper. With the dataset, the code and the trained models, our work provides a basis for further research into tools and their use in robotics applications.