 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Artificial Time-Delay Control with Barrier Lyapunov Constraints for Euler-Lagrange Robots
May 29, 2026This paper addresses the challenge of simultaneously compensating for state-dependent uncertainties and enforcing time-varying state constraints in Euler-Lagrange systems, a common requirement in robotics that remains underserved by existing control designs. A novel adaptive control framework is developed that combines an artificial time-delay-based uncertainty estimation strategy, also known as time-delay estimation, with a barrier Lyapunov function to enforce constraint-aware control design. Specifically, a state-dependent upper bound on the time-delay estimation approximation error is analytically formulated, and an adaptive law is constructed to estimate its parameters online, enabling real-time state-dependent uncertainty compensation without relying on prior model knowledge. To ensure constraint compliance, the barrier Lyapunov function-based controller enforces time-varying bounds on both position and velocity. The resulting architecture is provably stable via Lyapunov analysis. Experimental results on a five-degree-of-freedom robotic manipulator validate the framework's capability, compared with the state of the art, in maintaining strict adherence to safety-critical constraints under dynamic uncertainties.
Dodging the Moose: Experimental Insights in Real-Life Automated Collision Avoidance
Feb 19, 2026The sudden appearance of a static obstacle on the road, i.e. the moose test, is a well-known emergency scenario in collision avoidance for automated driving. Model Predictive Control (MPC) has long been employed for planning and control of automated vehicles in the state of the art. However, real-time implementation of automated collision avoidance in emergency scenarios such as the moose test remains unaddressed due to the high computational demand of MPC for evasive action in such hazardous scenarios. This paper offers new insights into real-time collision avoidance via the experimental imple- mentation of MPC for motion planning after a sudden and unexpected appearance of a static obstacle. As the state-of-the-art nonlinear MPC shows limited capability to provide an acceptable solution in real-time, we propose a human-like feed-forward planner to assist when the MPC optimization problem is either infeasible or unable to find a suitable solution due to the poor quality of its initial guess. We introduce the concept of maximum steering maneuver to design the feed-forward planner and mimic a human-like reaction after detecting the static obstacle on the road. Real-life experiments are conducted across various speeds and level of emergency using FPEV2-Kanon electric vehicle. Moreover, we demonstrate the effectiveness of our planning strategy via comparison with the state-of- the-art MPC motion planner.
Modular Adaptive Aerial Manipulation under Unknown Dynamic Coupling Forces
Oct 10, 2024



Successful aerial manipulation largely depends on how effectively a controller can tackle the coupling dynamic forces between the aerial vehicle and the manipulator. However, this control problem has remained largely unsolved as the existing control approaches either require precise knowledge of the aerial vehicle/manipulator inertial couplings, or neglect the state-dependent uncertainties especially arising during the interaction phase. This work proposes an adaptive control solution to overcome this long standing control challenge without any a priori knowledge of the coupling dynamic terms. Additionally, in contrast to the existing adaptive control solutions, the proposed control framework is modular, that is, it allows independent tuning of the adaptive gains for the vehicle position sub-dynamics, the vehicle attitude sub-dynamics, and the manipulator sub-dynamics. Stability of the closed loop under the proposed scheme is derived analytically, and real-time experiments validate the effectiveness of the proposed scheme over the state-of-the-art approaches.
Think Too Fast Nor Too Slow: The Computational Trade-off Between Planning And Reinforcement Learning
May 15, 2020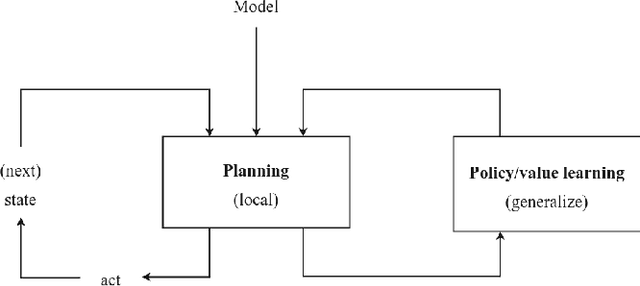

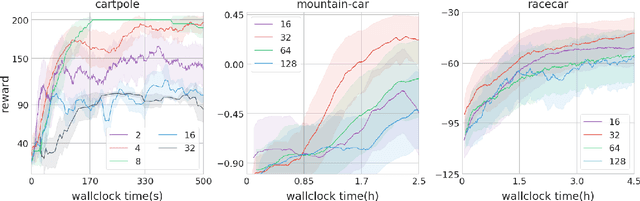
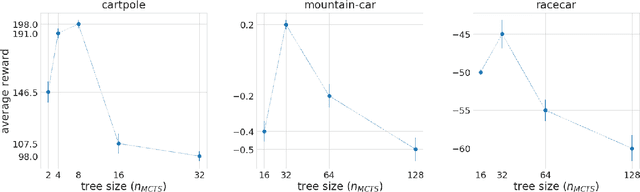
Planning and reinforcement learning are two key approaches to sequential decision making. Multi-step approximate real-time dynamic programming, a recently successful algorithm class of which AlphaZero [Silver et al., 2018] is an example, combines both by nesting planning within a learning loop. However, the combination of planning and learning introduces a new question: how should we balance time spend on planning, learning and acting? The importance of this trade-off has not been explicitly studied before. We show that it is actually of key importance, with computational results indicating that we should neither plan too long nor too short. Conceptually, we identify a new spectrum of planning-learning algorithms which ranges from exhaustive search (long planning) to model-free RL (no planning), with optimal performance achieved midway.