 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-KAST: Top-K Always Sparse Training
Jun 07, 2021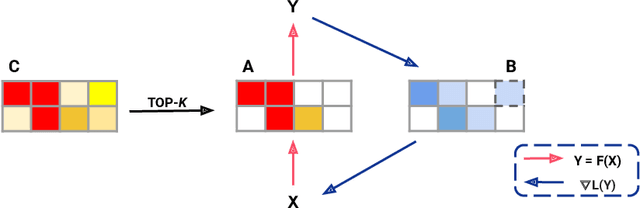
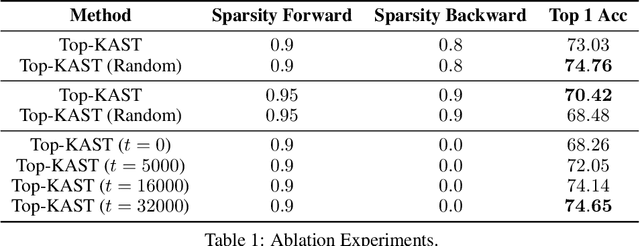
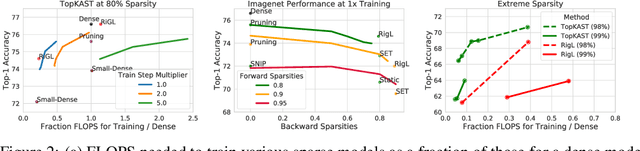
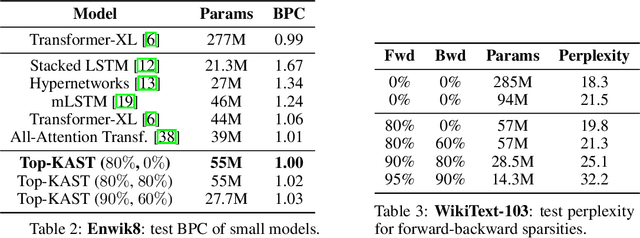
Sparse neural networks are becoming increasingly important as the field seeks to improve the performance of existing models by scaling them up, while simultaneously trying to reduce power consumption and computational footprint. Unfortunately, most existing methods for inducing performant sparse models still entail the instantiation of dense parameters, or dense gradients in the backward-pass, during training. For very large models this requirement can be prohibitive. In this work we propose Top-KAST, a method that preserves constant sparsity throughout training (in both the forward and backward-passes). We demonstrate the efficacy of our approach by showing that it performs comparably to or better than previous works when training models on the established ImageNet benchmark, whilst fully maintaining sparsity. In addition to our ImageNet results, we also demonstrate our approach in the domain of language modeling where the current best performing architectures tend to have tens of billions of parameters and scaling up does not yet seem to have saturated performance. Sparse versions of these architectures can be run with significantly fewer resources, making them more widely accessible and applicable. Furthermore, in addition to being effective, our approach is straightforward and can easily be implemented in a wide range of existing machine learning frameworks with only a few additional lines of code. We therefore hope that our contribution will help enable the broader community to explore the potential held by massive models, without incurring massive computational cost.
Generative Art Using Neural Visual Grammars and Dual Encoders
May 04, 2021


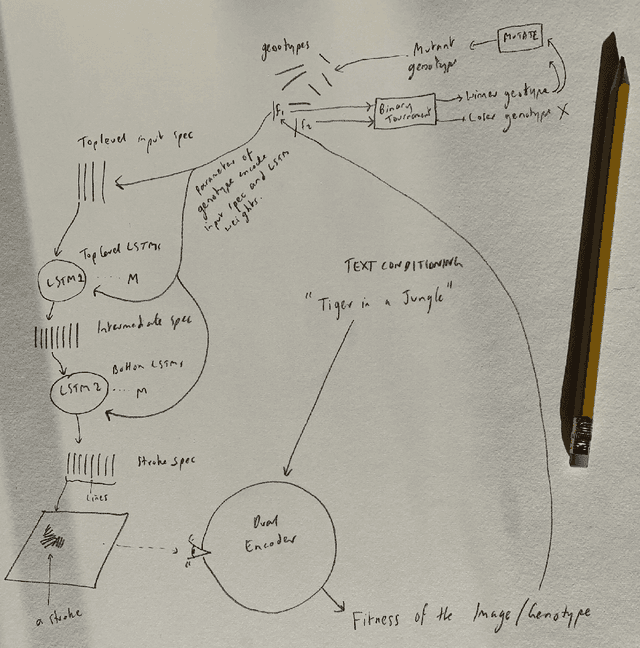
Whilst there are perhaps only a few scientific methods, there seem to be almost as many artistic methods as there are artists. Artistic processes appear to inhabit the highest order of open-endedness. To begin to understand some of the processes of art making it is helpful to try to automate them even partially. In this paper, a novel algorithm for producing generative art is described which allows a user to input a text string, and which in a creative response to this string, outputs an image which interprets that string. It does so by evolving images using a hierarchical neural Lindenmeyer system, and evaluating these images along the way using an image text dual encoder trained on billions of images and their associated text from the internet. In doing so we have access to and control over an instance of an artistic process, allowing analysis of which aspects of the artistic process become the task of the algorithm, and which elements remain the responsibility of the artist.
Contrastive Topographic Models: Energy-based density models applied to the understanding of sensory coding and cortical topography
Nov 05, 2020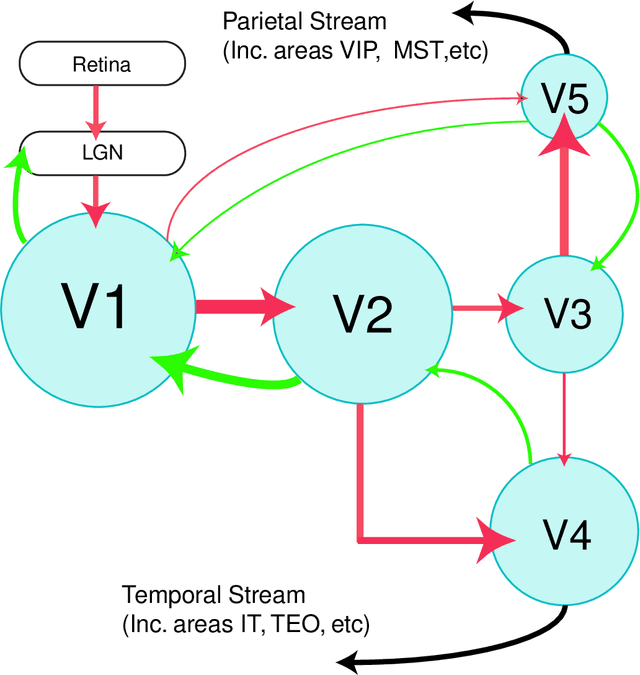
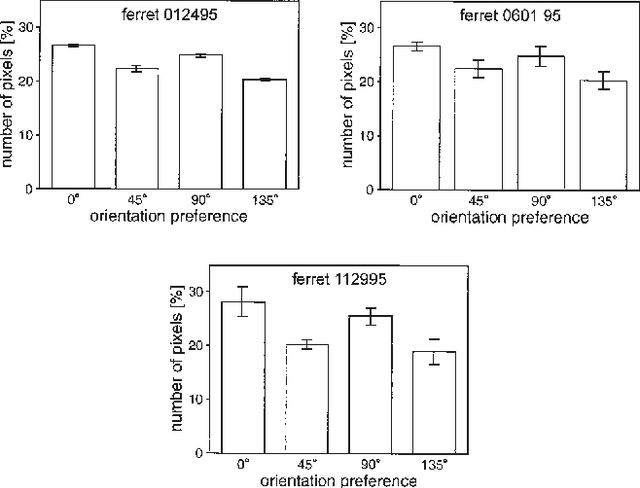
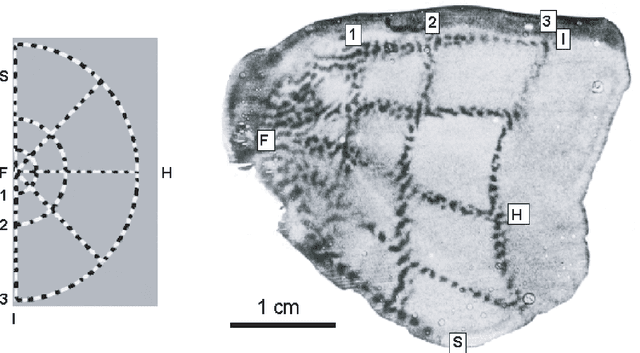
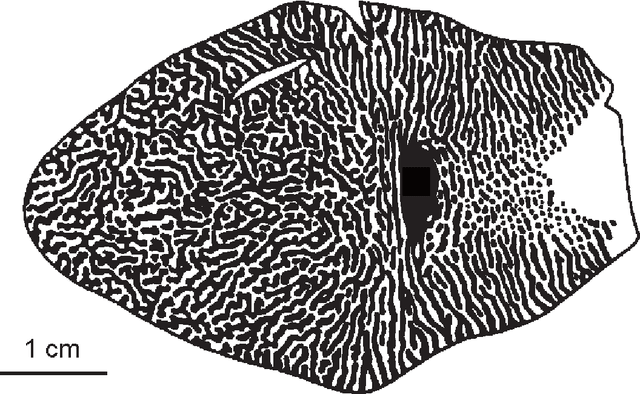
We address the problem of building theoretical models that help elucidate the function of the visual brain at computational/algorithmic and structural/mechanistic levels. We seek to understand how the receptive fields and topographic maps found in visual cortical areas relate to underlying computational desiderata. We view the development of sensory systems from the popular perspective of probability density estimation; this is motivated by the notion that an effective internal representational scheme is likely to reflect the statistical structure of the environment in which an organism lives. We apply biologically based constraints on elements of the model. The thesis begins by surveying the relevant literature from the fields of neurobiology, theoretical neuroscience, and machine learning. After this review we present our main theoretical and algorithmic developments: we propose a class of probabilistic models, which we refer to as "energy-based models", and show equivalences between this framework and various other types of probabilistic model such as Markov random fields and factor graphs; we also develop and discuss approximate algorithms for performing maximum likelihood learning and inference in our energy based models. The rest of the thesis is then concerned with exploring specific instantiations of such models. By performing constrained optimisation of model parameters to maximise the likelihood of appropriate, naturalistic datasets we are able to qualitatively reproduce many of the receptive field and map properties found in vivo, whilst simultaneously learning about statistical regularities in the data.
From Language Games to Drawing Games
Oct 06, 2020
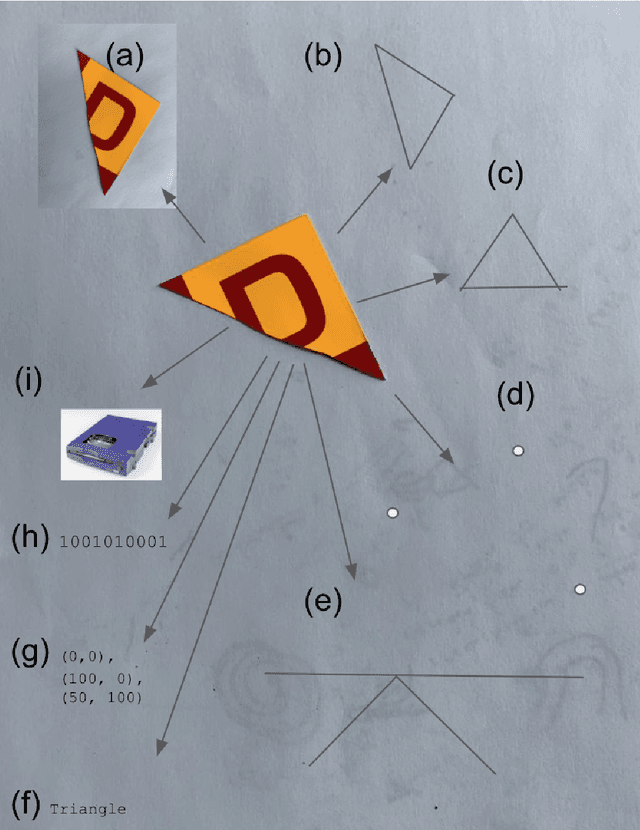
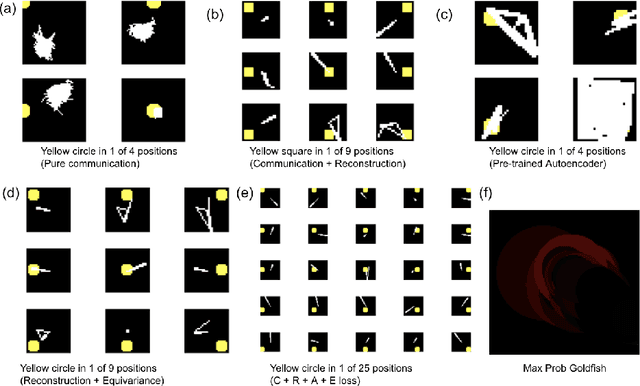

We attempt to automate various artistic processes by inventing a set of drawing games, analogous to the approach taken by emergent language research in inventing communication games. A critical difference is that drawing games demand much less effort from the receiver than do language games. Artists must work with pre-trained viewers who spend little time learning artist specific representational conventions, but who instead have a pre-trained visual system optimized for behaviour in the world by understanding to varying extents the environment's visual affordances. After considering various kinds of drawing game we present some preliminary experiments which have generated images by closing the generative-critical loop.
Small Data, Big Decisions: Model Selection in the Small-Data Regime
Sep 26, 2020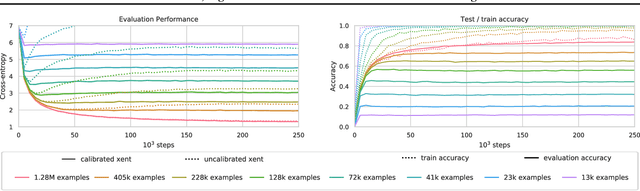

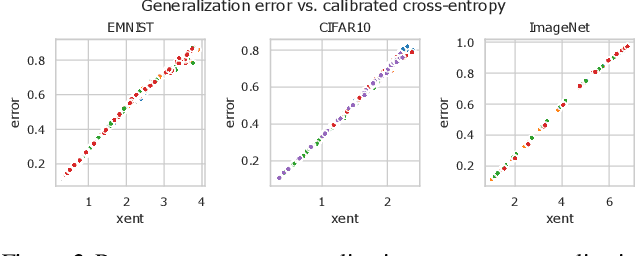

Highly overparametrized neural networks can display curiously strong generalization performance - a phenomenon that has recently garnered a wealth of theoretical and empirical research in order to better understand it. In contrast to most previous work, which typically considers the performance as a function of the model size, in this paper we empirically study the generalization performance as the size of the training set varies over multiple orders of magnitude. These systematic experiments lead to some interesting and potentially very useful observations; perhaps most notably that training on smaller subsets of the data can lead to more reliable model selection decisions whilst simultaneously enjoying smaller computational costs. Our experiments furthermore allow us to estimate Minimum Description Lengths for common datasets given modern neural network architectures, thereby paving the way for principled model selection taking into account Occams-razor.
AlgebraNets
Jun 16, 2020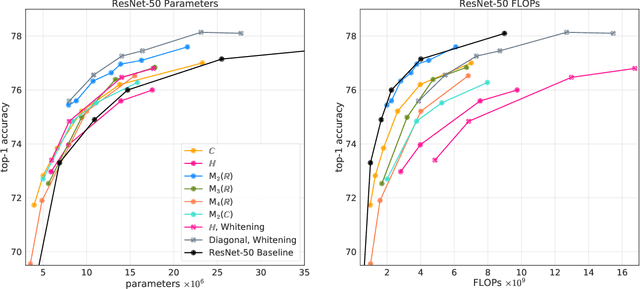
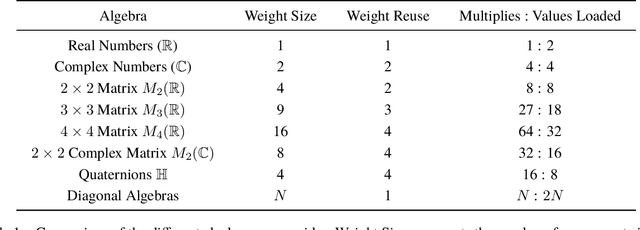
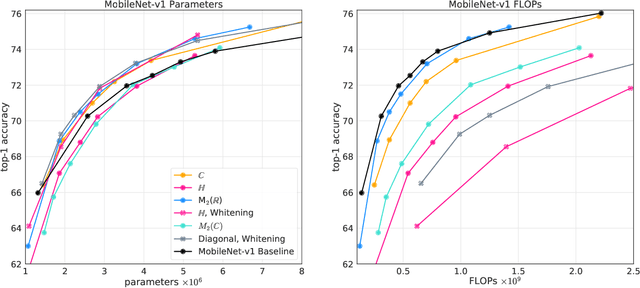

Neural networks have historically been built layerwise from the set of functions in ${f: \mathbb{R}^n \to \mathbb{R}^m }$, i.e. with activations and weights/parameters represented by real numbers, $\mathbb{R}$. Our work considers a richer set of objects for activations and weights, and undertakes a comprehensive study of alternative algebras as number representations by studying their performance on two challenging problems: large-scale image classification using the ImageNet dataset and language modeling using the enwiki8 and WikiText-103 datasets. We denote this broader class of models as AlgebraNets. Our findings indicate that the conclusions of prior work, which explored neural networks constructed from $\mathbb{C}$ (complex numbers) and $\mathbb{H}$ (quaternions) on smaller datasets, do not always transfer to these challenging settings. However, our results demonstrate that there are alternative algebras which deliver better parameter and computational efficiency compared with $\mathbb{R}$. We consider $\mathbb{C}$, $\mathbb{H}$, $M_{2}(\mathbb{R})$ (the set of $2\times2$ real-valued matrices), $M_{2}(\mathbb{C})$, $M_{3}(\mathbb{R})$ and $M_{4}(\mathbb{R})$. Additionally, we note that multiplication in these algebras has higher compute density than real multiplication, a useful property in situations with inherently limited parameter reuse such as auto-regressive inference and sparse neural networks. We therefore investigate how to induce sparsity within AlgebraNets. We hope that our strong results on large-scale, practical benchmarks will spur further exploration of these unconventional architectures which challenge the default choice of using real numbers for neural network weights and activations.
A Practical Sparse Approximation for Real Time Recurrent Learning
Jun 12, 2020
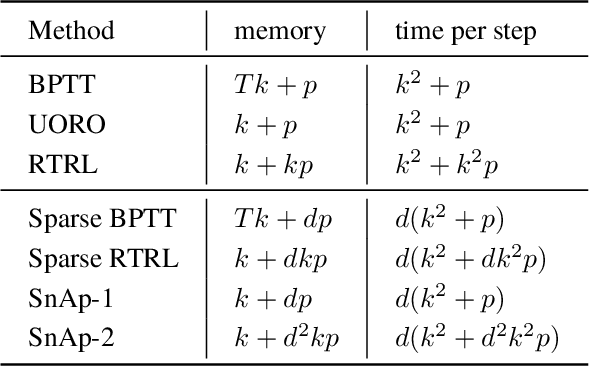
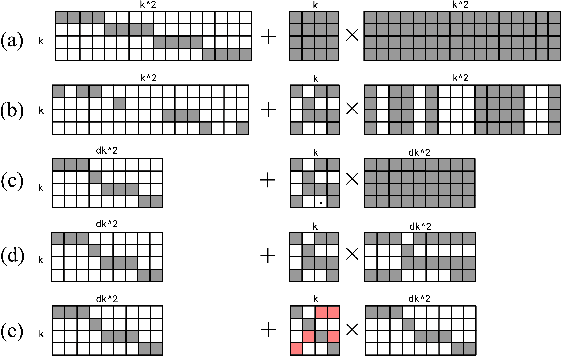
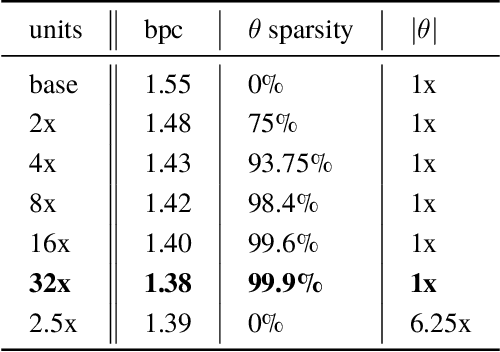
Current methods for training recurrent neural networks are based on backpropagation through time, which requires storing a complete history of network states, and prohibits updating the weights `online' (after every timestep). Real Time Recurrent Learning (RTRL) eliminates the need for history storage and allows for online weight updates, but does so at the expense of computational costs that are quartic in the state size. This renders RTRL training intractable for all but the smallest networks, even ones that are made highly sparse. We introduce the Sparse n-step Approximation (SnAp) to the RTRL influence matrix, which only keeps entries that are nonzero within n steps of the recurrent core. SnAp with n=1 is no more expensive than backpropagation, and we find that it substantially outperforms other RTRL approximations with comparable costs such as Unbiased Online Recurrent Optimization. For highly sparse networks, SnAp with n=2 remains tractable and can outperform backpropagation through time in terms of learning speed when updates are done online. SnAp becomes equivalent to RTRL when n is large.
A Deep Neural Network's Loss Surface Contains Every Low-dimensional Pattern
Jan 02, 2020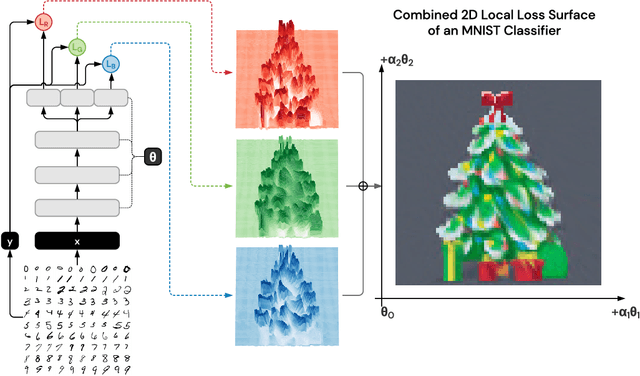
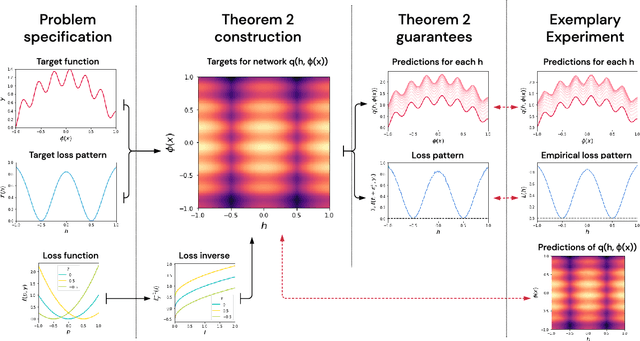
The work "Loss Landscape Sightseeing with Multi-Point Optimization" (Skorokhodov and Burtsev, 2019) demonstrated that one can empirically find arbitrary 2D binary patterns inside loss surfaces of popular neural networks. In this paper we prove that: (i) this is a general property of deep universal approximators; and (ii) this property holds for arbitrary smooth patterns, for other dimensionalities, for every dataset, and any neural network that is sufficiently deep and wide. Our analysis predicts not only the existence of all such low-dimensional patterns, but also two other properties that were observed empirically: (i) that it is easy to find these patterns; and (ii) that they transfer to other data-sets (e.g. a test-set).
Adapting Behaviour for Learning Progress
Dec 14, 2019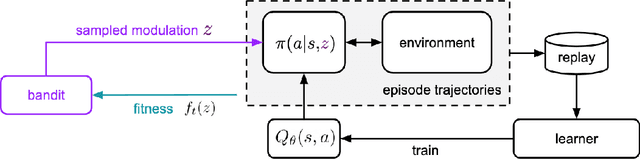

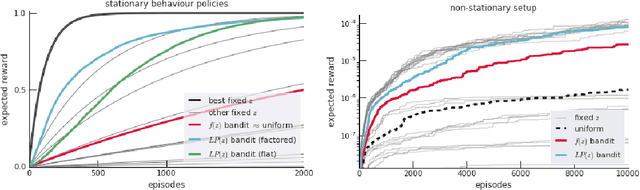
Determining what experience to generate to best facilitate learning (i.e. exploration) is one of the distinguishing features and open challenges in reinforcement learning. The advent of distributed agents that interact with parallel instances of the environment has enabled larger scales and greater flexibility, but has not removed the need to tune exploration to the task, because the ideal data for the learning algorithm necessarily depends on its process of learning. We propose to dynamically adapt the data generation by using a non-stationary multi-armed bandit to optimize a proxy of the learning progress. The data distribution is controlled by modulating multiple parameters of the policy (such as stochasticity, consistency or optimism) without significant overhead. The adaptation speed of the bandit can be increased by exploiting the factored modulation structure. We demonstrate on a suite of Atari 2600 games how this unified approach produces results comparable to per-task tuning at a fraction of the cost.
Meta-Learning Deep Energy-Based Memory Models
Oct 07, 2019

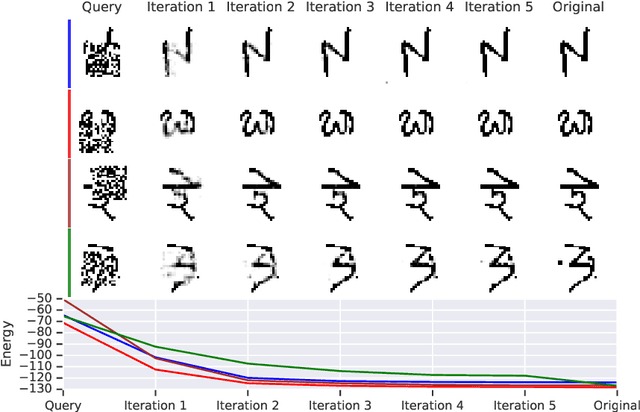

We study the problem of learning associative memory -- a system which is able to retrieve a remembered pattern based on its distorted or incomplete version. Attractor networks provide a sound model of associative memory: patterns are stored as attractors of the network dynamics and associative retrieval is performed by running the dynamics starting from a query pattern until it converges to an attractor. In such models the dynamics are often implemented as an optimization procedure that minimizes an energy function, such as in the classical Hopfield network. In general it is difficult to derive a writing rule for a given dynamics and energy that is both compressive and fast. Thus, most research in energy-based memory has been limited either to tractable energy models not expressive enough to handle complex high-dimensional objects such as natural images, or to models that do not offer fast writing. We present a novel meta-learning approach to energy-based memory models (EBMM) that allows one to use an arbitrary neural architecture as an energy model and quickly store patterns in its weights. We demonstrate experimentally that our EBMM approach can build compressed memories for synthetic and natural data, and is capable of associative retrieval that outperforms existing memory systems in terms of the reconstruction error and compression rate.