 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergies Between Disentanglement and Sparsity: a Multi-Task Learning Perspective
Nov 26, 2022Although disentangled representations are often said to be beneficial for downstream tasks, current empirical and theoretical understanding is limited. In this work, we provide evidence that disentangled representations coupled with sparse base-predictors improve generalization. In the context of multi-task learning, we prove a new identifiability result that provides conditions under which maximally sparse base-predictors yield disentangled representations. Motivated by this theoretical result, we propose a practical approach to learn disentangled representations based on a sparsity-promoting bi-level optimization problem. Finally, we explore a meta-learning version of this algorithm based on group Lasso multiclass SVM base-predictors, for which we derive a tractable dual formulation. It obtains competitive results on standard few-shot classification benchmarks, while each task is using only a fraction of the learned representations.
Controlled Sparsity via Constrained Optimization or: How I Learned to Stop Tuning Penalties and Love Constraints
Aug 08, 2022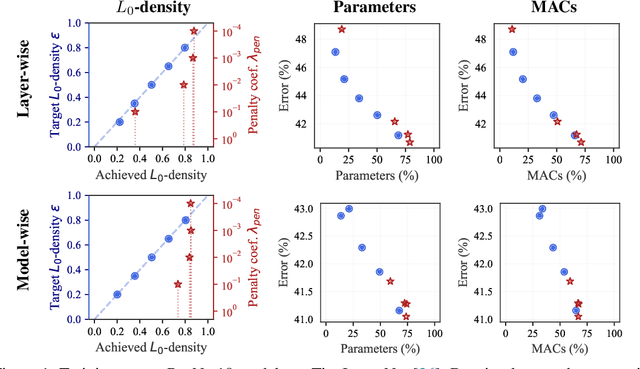

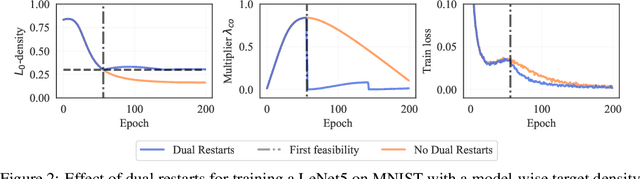
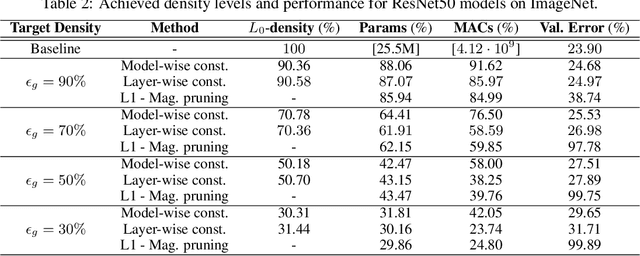
The performance of trained neural networks is robust to harsh levels of pruning. Coupled with the ever-growing size of deep learning models, this observation has motivated extensive research on learning sparse models. In this work, we focus on the task of controlling the level of sparsity when performing sparse learning. Existing methods based on sparsity-inducing penalties involve expensive trial-and-error tuning of the penalty factor, thus lacking direct control of the resulting model sparsity. In response, we adopt a constrained formulation: using the gate mechanism proposed by Louizos et al. (2018), we formulate a constrained optimization problem where sparsification is guided by the training objective and the desired sparsity target in an end-to-end fashion. Experiments on CIFAR-10/100, TinyImageNet, and ImageNet using WideResNet and ResNet{18, 50} models validate the effectiveness of our proposal and demonstrate that we can reliably achieve pre-determined sparsity targets without compromising on predictive performance.
Partial Disentanglement via Mechanism Sparsity
Jul 15, 2022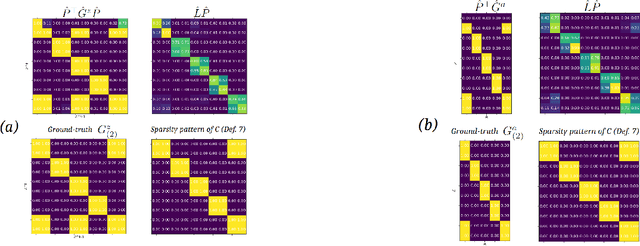

Disentanglement via mechanism sparsity was introduced recently as a principled approach to extract latent factors without supervision when the causal graph relating them in time is sparse, and/or when actions are observed and affect them sparsely. However, this theory applies only to ground-truth graphs satisfying a specific criterion. In this work, we introduce a generalization of this theory which applies to any ground-truth graph and specifies qualitatively how disentangled the learned representation is expected to be, via a new equivalence relation over models we call consistency. This equivalence captures which factors are expected to remain entangled and which are not based on the specific form of the ground-truth graph. We call this weaker form of identifiability partial disentanglement. The graphical criterion that allows complete disentanglement, proposed in an earlier work, can be derived as a special case of our theory. Finally, we enforce graph sparsity with constrained optimization and illustrate our theory and algorithm in simulations.
Data-Efficient Structured Pruning via Submodular Optimization
Mar 09, 2022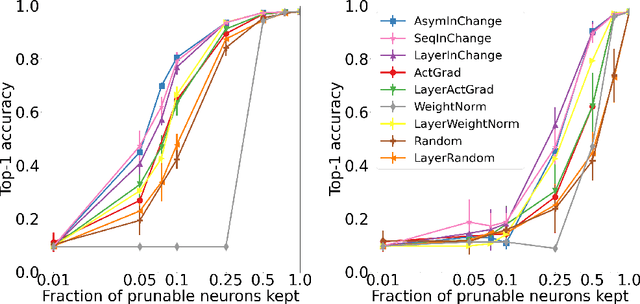
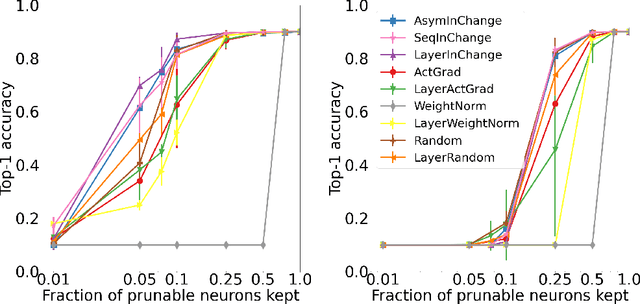
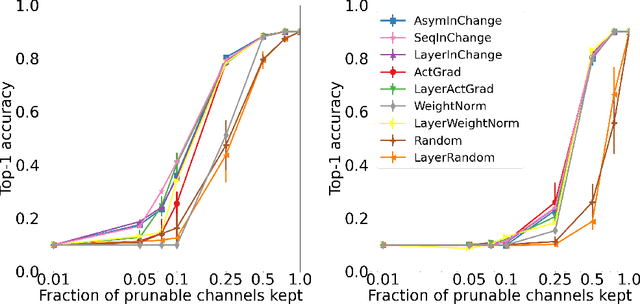
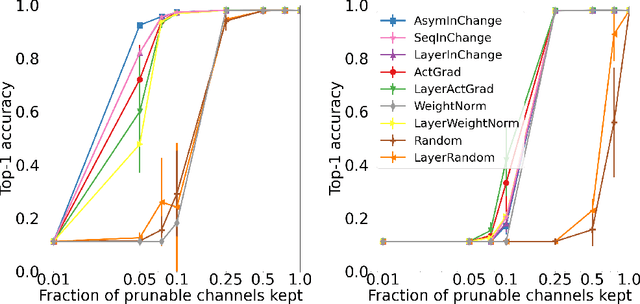
Structured pruning is an effective approach for compressing large pre-trained neural networks without significantly affecting their performance, which involves removing redundant regular regions of weights. However, current structured pruning methods are highly empirical in nature, do not provide any theoretical guarantees, and often require fine-tuning, which makes them inapplicable in the limited-data regime. We propose a principled data-efficient structured pruning method based on submodular optimization. In particular, for a given layer, we select neurons/channels to prune and corresponding new weights for the next layer, that minimize the change in the next layer's input induced by pruning. We show that this selection problem is a weakly submodular maximization problem, thus it can be provably approximated using an efficient greedy algorithm. Our method is one of the few in the literature that uses only a limited-number of training data and no labels. Our experimental results demonstrate that our method outperforms popular baseline methods in various one-shot pruning settings.
Bayesian Structure Learning with Generative Flow Networks
Feb 28, 2022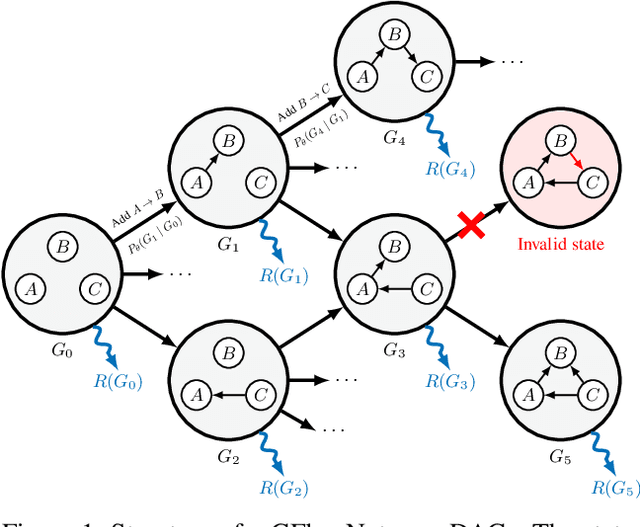
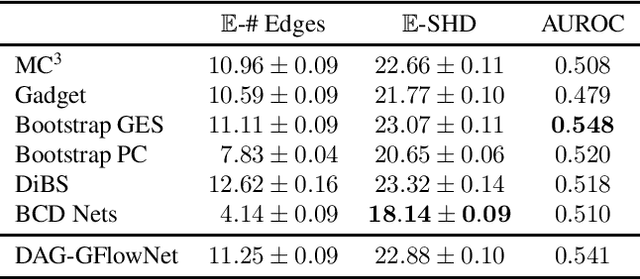
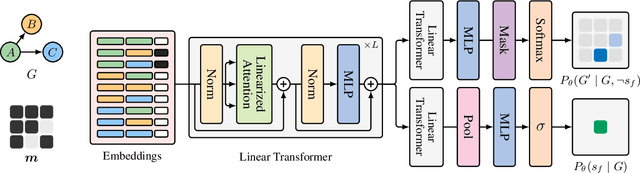
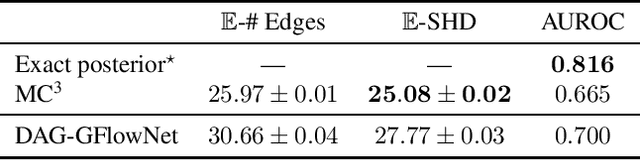
In Bayesian structure learning, we are interested in inferring a distribution over the directed acyclic graph (DAG) structure of Bayesian networks, from data. Defining such a distribution is very challenging, due to the combinatorially large sample space, and approximations based on MCMC are often required. Recently, a novel class of probabilistic models, called Generative Flow Networks (GFlowNets), have been introduced as a general framework for generative modeling of discrete and composite objects, such as graphs. In this work, we propose to use a GFlowNet as an alternative to MCMC for approximating the posterior distribution over the structure of Bayesian networks, given a dataset of observations. Generating a sample DAG from this approximate distribution is viewed as a sequential decision problem, where the graph is constructed one edge at a time, based on learned transition probabilities. Through evaluation on both simulated and real data, we show that our approach, called DAG-GFlowNet, provides an accurate approximation of the posterior over DAGs, and it compares favorably against other methods based on MCMC or variational inference.
Multiset-Equivariant Set Prediction with Approximate Implicit Differentiation
Nov 23, 2021

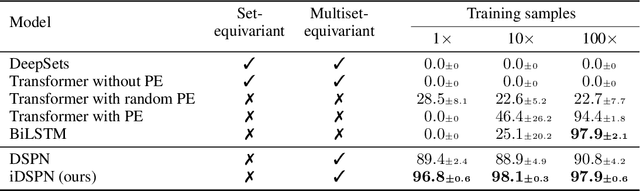
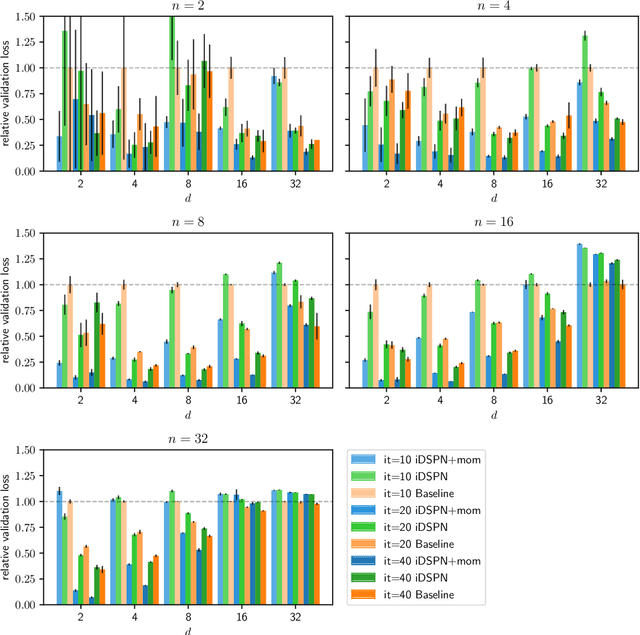
Most set prediction models in deep learning use set-equivariant operations, but they actually operate on multisets. We show that set-equivariant functions cannot represent certain functions on multisets, so we introduce the more appropriate notion of multiset-equivariance. We identify that the existing Deep Set Prediction Network (DSPN) can be multiset-equivariant without being hindered by set-equivariance and improve it with approximate implicit differentiation, allowing for better optimization while being faster and saving memory. In a range of toy experiments, we show that the perspective of multiset-equivariance is beneficial and that our changes to DSPN achieve better results in most cases. On CLEVR object property prediction, we substantially improve over the state-of-the-art Slot Attention from 8% to 77% in one of the strictest evaluation metrics because of the benefits made possible by implicit differentiation.
Convergence Rates for the MAP of an Exponential Family and Stochastic Mirror Descent -- an Open Problem
Nov 12, 2021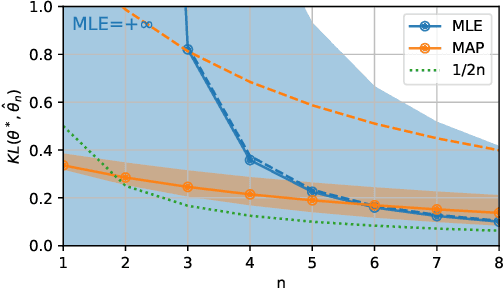
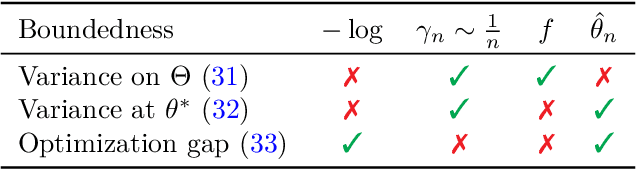
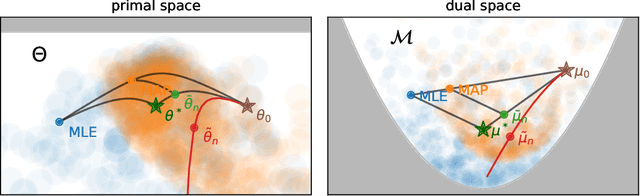
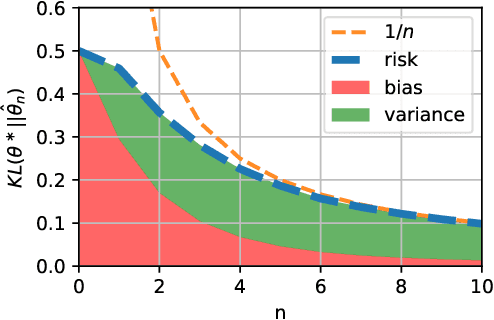
We consider the problem of upper bounding the expected log-likelihood sub-optimality of the maximum likelihood estimate (MLE), or a conjugate maximum a posteriori (MAP) for an exponential family, in a non-asymptotic way. Surprisingly, we found no general solution to this problem in the literature. In particular, current theories do not hold for a Gaussian or in the interesting few samples regime. After exhibiting various facets of the problem, we show we can interpret the MAP as running stochastic mirror descent (SMD) on the log-likelihood. However, modern convergence results do not apply for standard examples of the exponential family, highlighting holes in the convergence literature. We believe solving this very fundamental problem may bring progress to both the statistics and optimization communities.
A Survey of Self-Supervised and Few-Shot Object Detection
Nov 08, 2021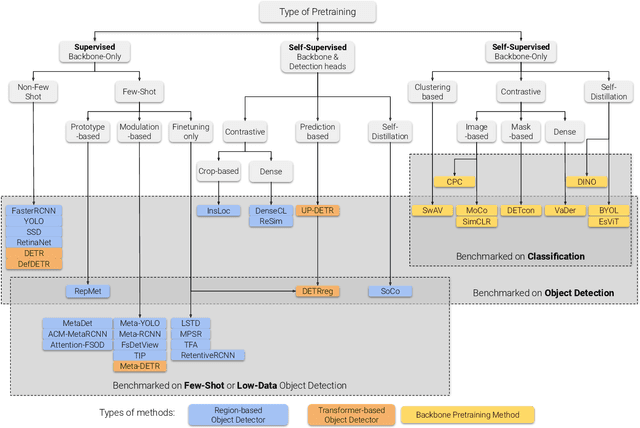

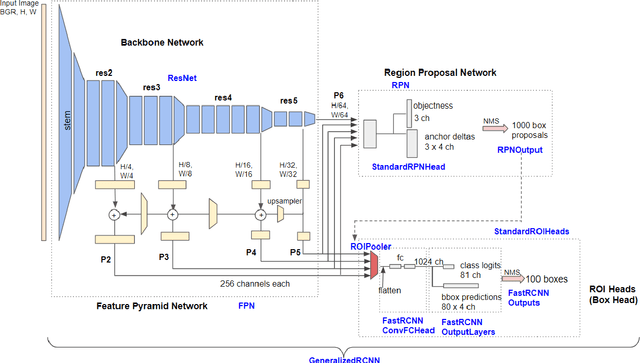
Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions. Project page at https://gabrielhuang.github.io/fsod-survey/
Discovering Latent Causal Variables via Mechanism Sparsity: A New Principle for Nonlinear ICA
Jul 21, 2021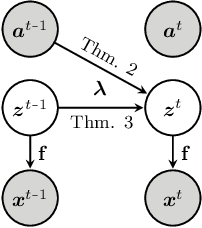
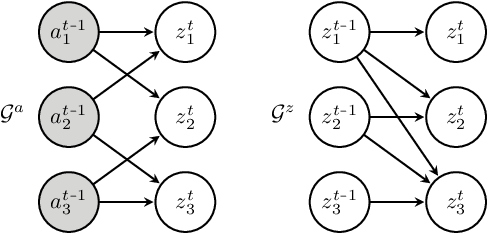
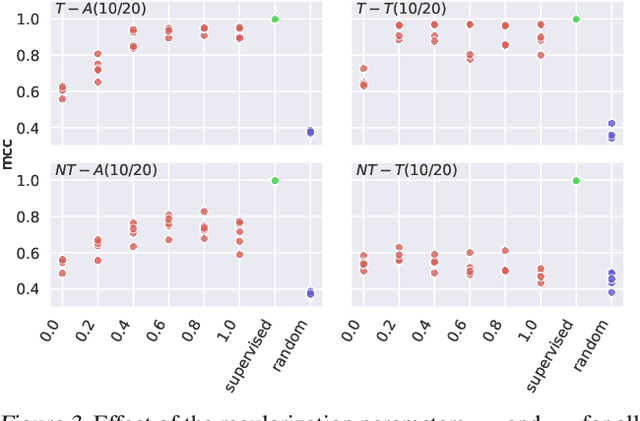
It can be argued that finding an interpretable low-dimensional representation of a potentially high-dimensional phenomenon is central to the scientific enterprise. Independent component analysis (ICA) refers to an ensemble of methods which formalize this goal and provide estimation procedure for practical application. This work proposes mechanism sparsity regularization as a new principle to achieve nonlinear ICA when latent factors depend sparsely on observed auxiliary variables and/or past latent factors. We show that the latent variables can be recovered up to a permutation if one regularizes the latent mechanisms to be sparse and if some graphical criterion is satisfied by the data generating process. As a special case, our framework shows how one can leverage unknown-target interventions on the latent factors to disentangle them, thus drawing further connections between ICA and causality. We validate our theoretical results with toy experiments.
Stochastic Gradient Descent-Ascent and Consensus Optimization for Smooth Games: Convergence Analysis under Expected Co-coercivity
Jun 30, 2021
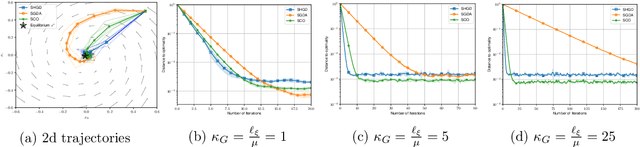
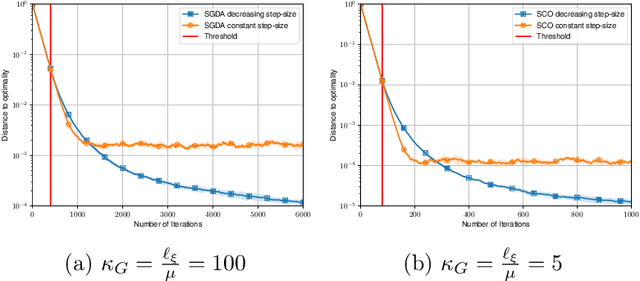
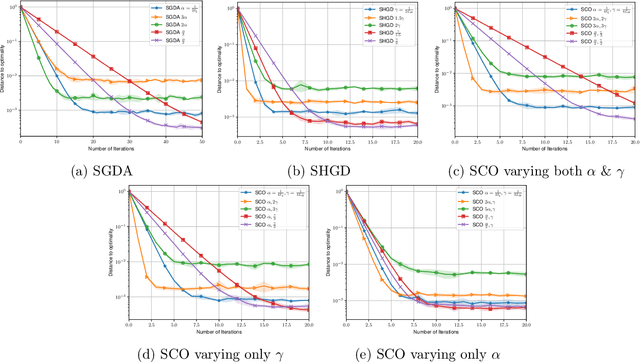
Two of the most prominent algorithms for solving unconstrained smooth games are the classical stochastic gradient descent-ascent (SGDA) and the recently introduced stochastic consensus optimization (SCO) (Mescheder et al., 2017). SGDA is known to converge to a stationary point for specific classes of games, but current convergence analyses require a bounded variance assumption. SCO is used successfully for solving large-scale adversarial problems, but its convergence guarantees are limited to its deterministic variant. In this work, we introduce the expected co-coercivity condition, explain its benefits, and provide the first last-iterate convergence guarantees of SGDA and SCO under this condition for solving a class of stochastic variational inequality problems that are potentially non-monotone. We prove linear convergence of both methods to a neighborhood of the solution when they use constant step-size, and we propose insightful stepsize-switching rules to guarantee convergence to the exact solution. In addition, our convergence guarantees hold under the arbitrary sampling paradigm, and as such, we give insights into the complexity of minibatching.