 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEKILA: Synthetic Media Provenance and Attribution for Generative Art
Apr 10, 2023



We present EKILA; a decentralized framework that enables creatives to receive recognition and reward for their contributions to generative AI (GenAI). EKILA proposes a robust visual attribution technique and combines this with an emerging content provenance standard (C2PA) to address the problem of synthetic image provenance -- determining the generative model and training data responsible for an AI-generated image. Furthermore, EKILA extends the non-fungible token (NFT) ecosystem to introduce a tokenized representation for rights, enabling a triangular relationship between the asset's Ownership, Rights, and Attribution (ORA). Leveraging the ORA relationship enables creators to express agency over training consent and, through our attribution model, to receive apportioned credit, including royalty payments for the use of their assets in GenAI.
VADER: Video Alignment Differencing and Retrieval
Mar 25, 2023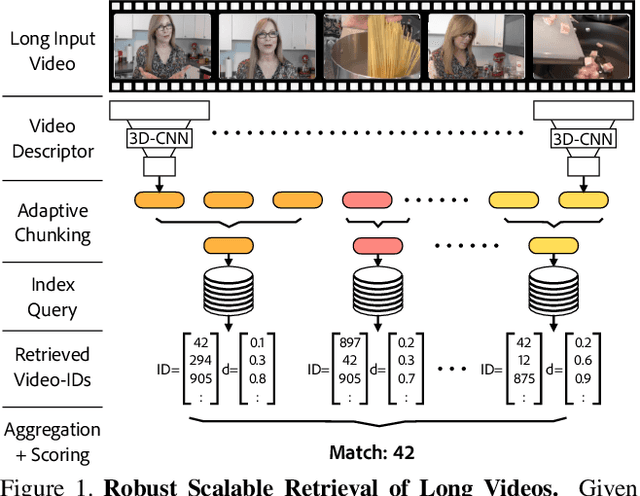
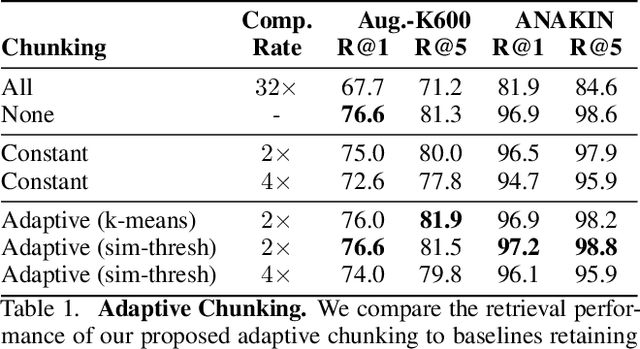

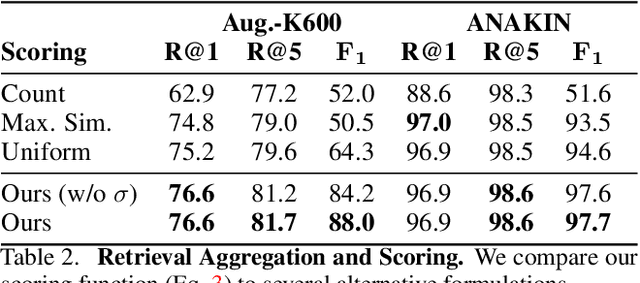
We propose VADER, a spatio-temporal matching, alignment, and change summarization method to help fight misinformation spread via manipulated videos. VADER matches and coarsely aligns partial video fragments to candidate videos using a robust visual descriptor and scalable search over adaptively chunked video content. A transformer-based alignment module then refines the temporal localization of the query fragment within the matched video. A space-time comparator module identifies regions of manipulation between aligned content, invariant to any changes due to any residual temporal misalignments or artifacts arising from non-editorial changes of the content. Robustly matching video to a trusted source enables conclusions to be drawn on video provenance, enabling informed trust decisions on content encountered.
Audio-Visual Contrastive Learning with Temporal Self-Supervision
Feb 15, 2023



We propose a self-supervised learning approach for videos that learns representations of both the RGB frames and the accompanying audio without human supervision. In contrast to images that capture the static scene appearance, videos also contain sound and temporal scene dynamics. To leverage the temporal and aural dimension inherent to videos, our method extends temporal self-supervision to the audio-visual setting and integrates it with multi-modal contrastive objectives. As temporal self-supervision, we pose playback speed and direction recognition in both modalities and propose intra- and inter-modal temporal ordering tasks. Furthermore, we design a novel contrastive objective in which the usual pairs are supplemented with additional sample-dependent positives and negatives sampled from the evolving feature space. In our model, we apply such losses among video clips and between videos and their temporally corresponding audio clips. We verify our model design in extensive ablation experiments and evaluate the video and audio representations in transfer experiments to action recognition and retrieval on UCF101 and HMBD51, audio classification on ESC50, and robust video fingerprinting on VGG-Sound, with state-of-the-art results.
Spatio-Temporal Crop Aggregation for Video Representation Learning
Nov 30, 2022



We propose Spatio-temporal Crop Aggregation for video representation LEarning (SCALE), a novel method that enjoys high scalability at both training and inference time. Our model builds long-range video features by learning from sets of video clip-level features extracted with a pre-trained backbone. To train the model, we propose a self-supervised objective consisting of masked clip feature prediction. We apply sparsity to both the input, by extracting a random set of video clips, and to the loss function, by only reconstructing the sparse inputs. Moreover, we use dimensionality reduction by working in the latent space of a pre-trained backbone applied to single video clips. The video representation is then obtained by taking the ensemble of the concatenation of embeddings of separate video clips with a video clip set summarization token. These techniques make our method not only extremely efficient to train, but also highly effective in transfer learning. We demonstrate that our video representation yields state-of-the-art performance with linear, non-linear, and $k$-NN probing on common action classification datasets.
SImProv: Scalable Image Provenance Framework for Robust Content Attribution
Jun 28, 2022

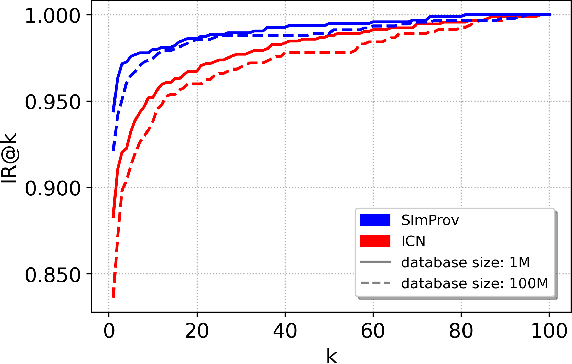

We present SImProv - a scalable image provenance framework to match a query image back to a trusted database of originals and identify possible manipulations on the query. SImProv consists of three stages: a scalable search stage for retrieving top-k most similar images; a re-ranking and near-duplicated detection stage for identifying the original among the candidates; and finally a manipulation detection and visualization stage for localizing regions within the query that may have been manipulated to differ from the original. SImProv is robust to benign image transformations that commonly occur during online redistribution, such as artifacts due to noise and recompression degradation, as well as out-of-place transformations due to image padding, warping, and changes in size and shape. Robustness towards out-of-place transformations is achieved via the end-to-end training of a differentiable warping module within the comparator architecture. We demonstrate effective retrieval and manipulation detection over a dataset of 100 million images.
Video-ReTime: Learning Temporally Varying Speediness for Time Remapping
May 11, 2022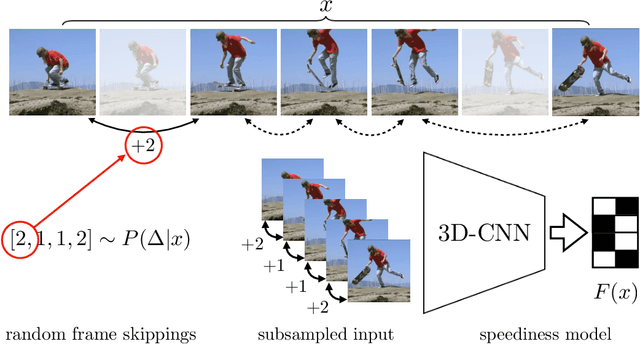
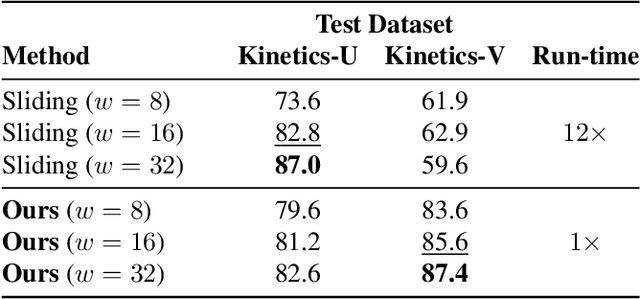
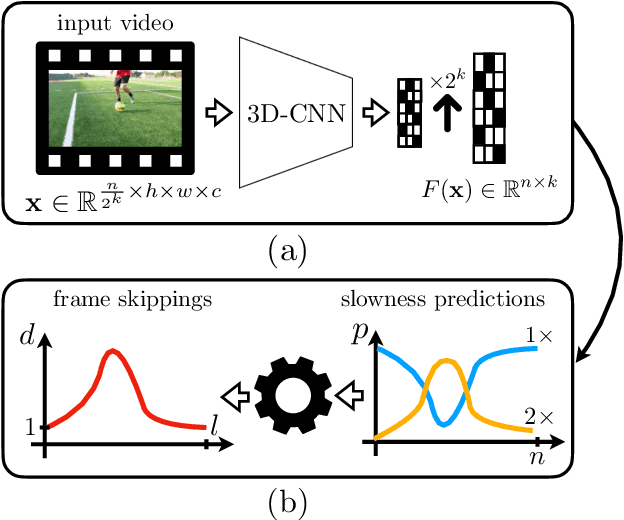
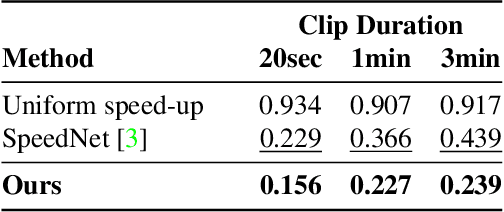
We propose a method for generating a temporally remapped video that matches the desired target duration while maximally preserving natural video dynamics. Our approach trains a neural network through self-supervision to recognize and accurately localize temporally varying changes in the video playback speed. To re-time videos, we 1. use the model to infer the slowness of individual video frames, and 2. optimize the temporal frame sub-sampling to be consistent with the model's slowness predictions. We demonstrate that this model can detect playback speed variations more accurately while also being orders of magnitude more efficient than prior approaches. Furthermore, we propose an optimization for video re-timing that enables precise control over the target duration and performs more robustly on longer videos than prior methods. We evaluate the model quantitatively on artificially speed-up videos, through transfer to action recognition, and qualitatively through user studies.
DILEMMA: Self-Supervised Shape and Texture Learning with Transformers
Apr 10, 2022

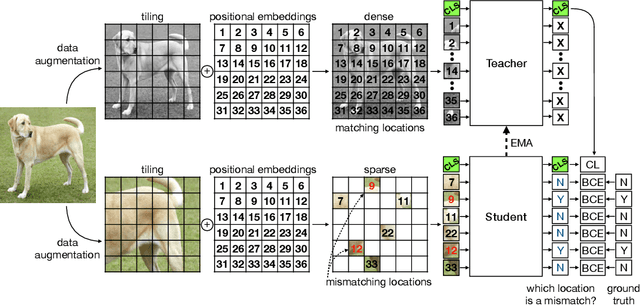

There is a growing belief that deep neural networks with a shape bias may exhibit better generalization capabilities than models with a texture bias, because shape is a more reliable indicator of the object category. However, we show experimentally that existing measures of shape bias are not stable predictors of generalization and argue that shape discrimination should not come at the expense of texture discrimination. Thus, we propose a pseudo-task to explicitly boost both shape and texture discriminability in models trained via self-supervised learning. For this purpose, we train a ViT to detect which input token has been combined with an incorrect positional embedding. To retain texture discrimination, the ViT is also trained as in MoCo with a student-teacher architecture and a contrastive loss over an extra learnable class token. We call our method DILEMMA, which stands for Detection of Incorrect Location EMbeddings with MAsked inputs. We evaluate our method through fine-tuning on several datasets and show that it outperforms MoCoV3 and DINO. Moreover, we show that when downstream tasks are strongly reliant on shape (such as in the YOGA-82 pose dataset), our pre-trained features yield a significant gain over prior work. Code will be released upon publication.
Learning to Deblur and Rotate Motion-Blurred Faces
Dec 14, 2021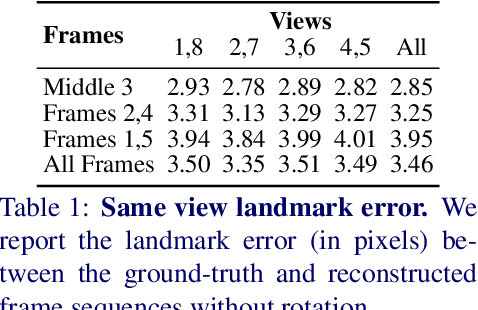
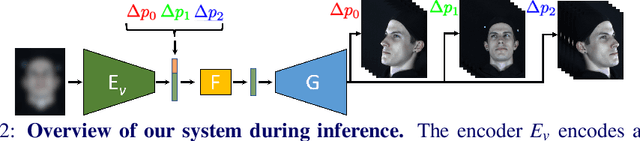
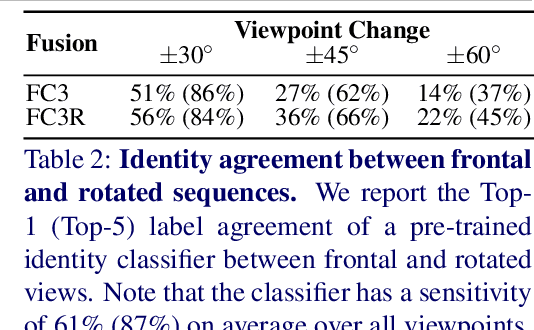
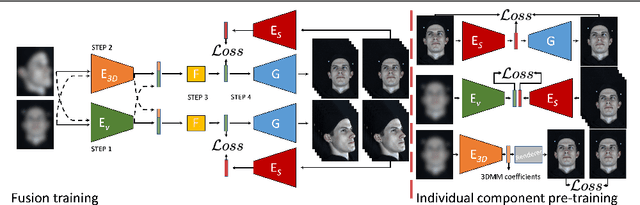
We propose a solution to the novel task of rendering sharp videos from new viewpoints from a single motion-blurred image of a face. Our method handles the complexity of face blur by implicitly learning the geometry and motion of faces through the joint training on three large datasets: FFHQ and 300VW, which are publicly available, and a new Bern Multi-View Face Dataset (BMFD) that we built. The first two datasets provide a large variety of faces and allow our model to generalize better. BMFD instead allows us to introduce multi-view constraints, which are crucial to synthesizing sharp videos from a new camera view. It consists of high frame rate synchronized videos from multiple views of several subjects displaying a wide range of facial expressions. We use the high frame rate videos to simulate realistic motion blur through averaging. Thanks to this dataset, we train a neural network to reconstruct a 3D video representation from a single image and the corresponding face gaze. We then provide a camera viewpoint relative to the estimated gaze and the blurry image as input to an encoder-decoder network to generate a video of sharp frames with a novel camera viewpoint. We demonstrate our approach on test subjects of our multi-view dataset and VIDTIMIT.
Time-Equivariant Contrastive Video Representation Learning
Dec 07, 2021
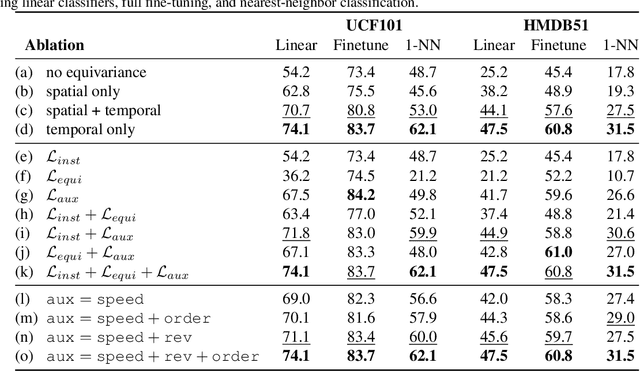
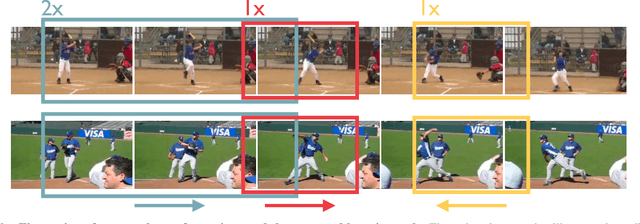
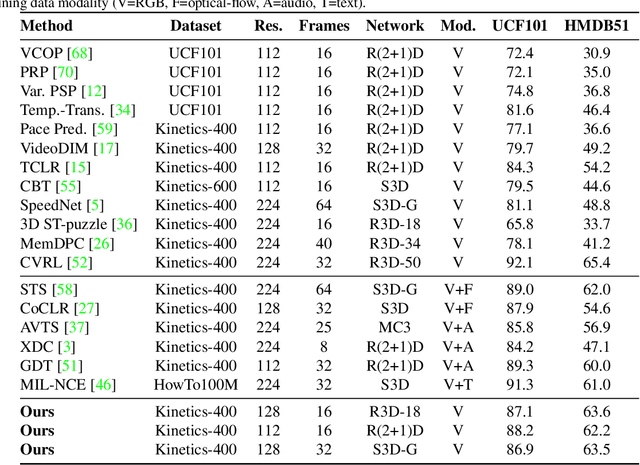
We introduce a novel self-supervised contrastive learning method to learn representations from unlabelled videos. Existing approaches ignore the specifics of input distortions, e.g., by learning invariance to temporal transformations. Instead, we argue that video representation should preserve video dynamics and reflect temporal manipulations of the input. Therefore, we exploit novel constraints to build representations that are equivariant to temporal transformations and better capture video dynamics. In our method, relative temporal transformations between augmented clips of a video are encoded in a vector and contrasted with other transformation vectors. To support temporal equivariance learning, we additionally propose the self-supervised classification of two clips of a video into 1. overlapping 2. ordered, or 3. unordered. Our experiments show that time-equivariant representations achieve state-of-the-art results in video retrieval and action recognition benchmarks on UCF101, HMDB51, and Diving48.
VPN: Video Provenance Network for Robust Content Attribution
Sep 21, 2021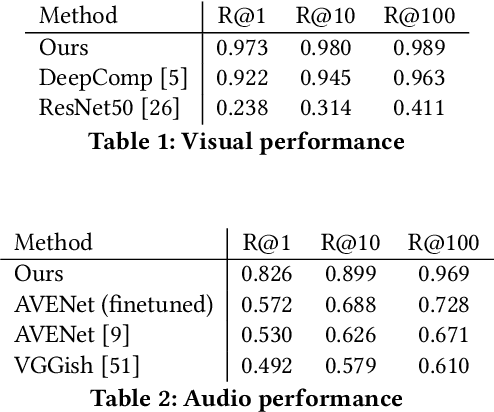
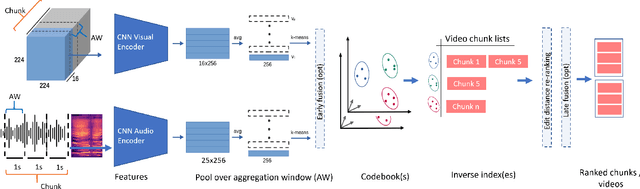
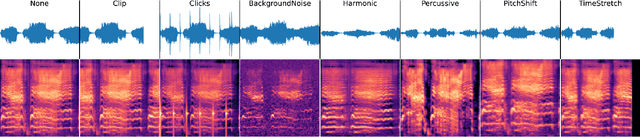

We present VPN - a content attribution method for recovering provenance information from videos shared online. Platforms, and users, often transform video into different quality, codecs, sizes, shapes, etc. or slightly edit its content such as adding text or emoji, as they are redistributed online. We learn a robust search embedding for matching such video, invariant to these transformations, using full-length or truncated video queries. Once matched against a trusted database of video clips, associated information on the provenance of the clip is presented to the user. We use an inverted index to match temporal chunks of video using late-fusion to combine both visual and audio features. In both cases, features are extracted via a deep neural network trained using contrastive learning on a dataset of original and augmented video clips. We demonstrate high accuracy recall over a corpus of 100,000 videos.