 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Spatially Grounded 2D Vision-Language Models for Radiology
Jun 18, 2026We study how to train visually grounded vision-language models (VLMs) for radiology without manual spatial annotations. We introduce RefRad2D, a large-scale bilingual (German/English) dataset of 1.2M CT and MR image-text pairs derived from clinical practice, with task-specific VQA and spatial grounding subsets generated automatically via LLM-based curation and automated segmentation. Trained on this data, our model RadGrounder jointly performs report generation, visual question answering, and spatial grounding via bounding-box detection or segmentation. On external VQA benchmarks (Slake, VQA-RAD), RadGrounder achieves competitive results with specialized medical VLMs. Adding our clinical data to the training mixture improves open-ended VQA over fine-tuning on the downstream datasets alone, showing the transferability of our dataset. Crucially, adding grounding supervision does not degrade language quality, enabling spatially verifiable outputs at no cost to VQA performance.
Learning to Read Where to Look: Disease-Aware Vision-Language Pretraining for 3D CT
Mar 02, 2026Recent 3D CT vision-language models align volumes with reports via contrastive pretraining, but typically rely on limited public data and provide only coarse global supervision. We train a 3D CT vision-language model on 98k report-volume pairs (50k patients) collected at a single hospital, combined with public datasets, using SigLIP-style contrastive pretraining together with prompt-based disease supervision in the shared vision-text embedding space. On CT-RATE, our model achieves state-of-the-art text-to-image retrieval (R@10 31.5 vs. 22.2) and competitive disease classification (AUC 83.8 vs. 83.8), with consistent results on Rad-ChestCT (AUC 77.0 vs. 77.3). We further observe that radiologists routinely reference specific images within their reports (e.g., ``series X, image Y''), linking textual descriptions to precise axial locations. We automatically mine 262k such snippet-slice pairs and introduce the task of intra-scan snippet localization -- predicting the axial depth referred to by a text snippet -- reducing mean absolute error to 36.3 mm at 12 mm feature resolution, compared with 67.0 mm for the best baseline. Adding this localization objective leaves retrieval and classification broadly unchanged within confidence bounds, yielding a single unified model for retrieval, classification, and intra-scan grounding.
Using Knowledge Graphs to harvest datasets for efficient CLIP model training
May 05, 2025Training high-quality CLIP models typically requires enormous datasets, which limits the development of domain-specific models -- especially in areas that even the largest CLIP models do not cover well -- and drives up training costs. This poses challenges for scientific research that needs fine-grained control over the training procedure of CLIP models. In this work, we show that by employing smart web search strategies enhanced with knowledge graphs, a robust CLIP model can be trained from scratch with considerably less data. Specifically, we demonstrate that an expert foundation model for living organisms can be built using just 10M images. Moreover, we introduce EntityNet, a dataset comprising 33M images paired with 46M text descriptions, which enables the training of a generic CLIP model in significantly reduced time.
Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
Feb 11, 2024



The evaluation of text-generative vision-language models is a challenging yet crucial endeavor. By addressing the limitations of existing Visual Question Answering (VQA) benchmarks and proposing innovative evaluation methodologies, our research seeks to advance our understanding of these models' capabilities. We propose a novel VQA benchmark based on well-known visual classification datasets which allows a granular evaluation of text-generative vision-language models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, we suggest using the semantic hierarchy of the label space to ask automatically generated follow-up questions about the ground-truth category. Finally, we compare traditional NLP and LLM-based metrics for the problem of evaluating model predictions given ground-truth answers. We perform a human evaluation study upon which we base our decision on the final metric. We apply our benchmark to a suite of vision-language models and show a detailed comparison of their abilities on object, action, and attribute classification. Our contributions aim to lay the foundation for more precise and meaningful assessments, facilitating targeted progress in the exciting field of vision-language modeling.
Open-vocabulary Attribute Detection
Nov 23, 2022Vision-language modeling has enabled open-vocabulary tasks where predictions can be queried using any text prompt in a zero-shot manner. Existing open-vocabulary tasks focus on object classes, whereas research on object attributes is limited due to the lack of a reliable attribute-focused evaluation benchmark. This paper introduces the Open-Vocabulary Attribute Detection (OVAD) task and the corresponding OVAD benchmark. The objective of the novel task and benchmark is to probe object-level attribute information learned by vision-language models. To this end, we created a clean and densely annotated test set covering 117 attribute classes on the 80 object classes of MS COCO. It includes positive and negative annotations, which enables open-vocabulary evaluation. Overall, the benchmark consists of 1.4 million annotations. For reference, we provide a first baseline method for open-vocabulary attribute detection. Moreover, we demonstrate the benchmark's value by studying the attribute detection performance of several foundation models. Project page https://ovad-benchmark.github.io/
COOT: Cooperative Hierarchical Transformer for Video-Text Representation Learning
Nov 01, 2020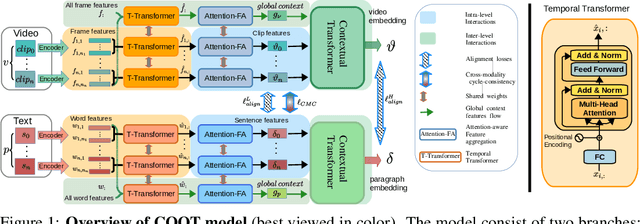
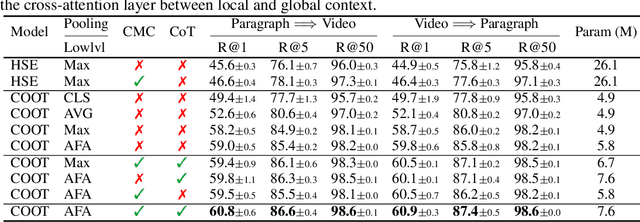
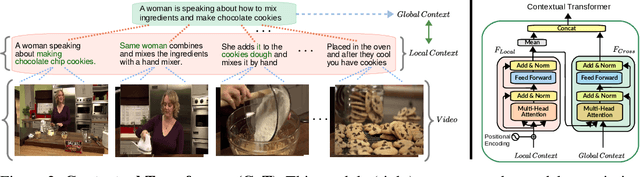
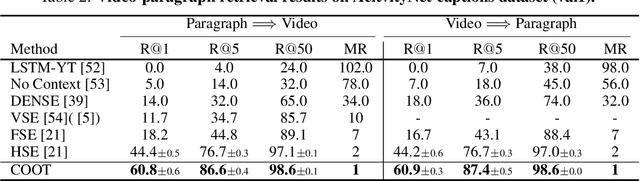
Many real-world video-text tasks involve different levels of granularity, such as frames and words, clip and sentences or videos and paragraphs, each with distinct semantics. In this paper, we propose a Cooperative hierarchical Transformer (COOT) to leverage this hierarchy information and model the interactions between different levels of granularity and different modalities. The method consists of three major components: an attention-aware feature aggregation layer, which leverages the local temporal context (intra-level, e.g., within a clip), a contextual transformer to learn the interactions between low-level and high-level semantics (inter-level, e.g. clip-video, sentence-paragraph), and a cross-modal cycle-consistency loss to connect video and text. The resulting method compares favorably to the state of the art on several benchmarks while having few parameters. All code is available open-source at https://github.com/gingsi/coot-videotext