 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIEG-Youpu Solution for NeurIPS 2022 WikiKG90Mv2-LSC
Mar 30, 2026WikiKG90Mv2 in NeurIPS 2022 is a large encyclopedic knowledge graph. Embedding knowledge graphs into continuous vector spaces is important for many practical applications, such as knowledge acquisition, question answering, and recommendation systems. Compared to existing knowledge graphs, WikiKG90Mv2 is a large scale knowledge graph, which is composed of more than 90 millions of entities. Both efficiency and accuracy should be considered when building graph embedding models for knowledge graph at scale. To this end, we follow the retrieve then re-rank pipeline, and make novel modifications in both retrieval and re-ranking stage. Specifically, we propose a priority infilling retrieval model to obtain candidates that are structurally and semantically similar. Then we propose an ensemble based re-ranking model with neighbor enhanced representations to produce final link prediction results among retrieved candidates. Experimental results show that our proposed method outperforms existing baseline methods and improves MRR of validation set from 0.2342 to 0.2839.
Learning High-order Structural and Attribute information by Knowledge Graph Attention Networks for Enhancing Knowledge Graph Embedding
Oct 10, 2019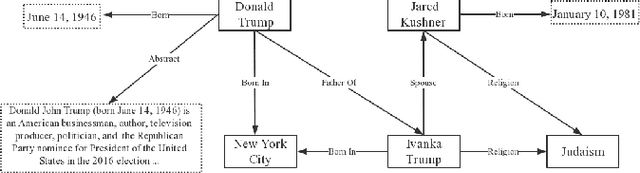
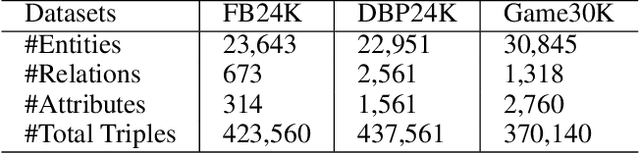
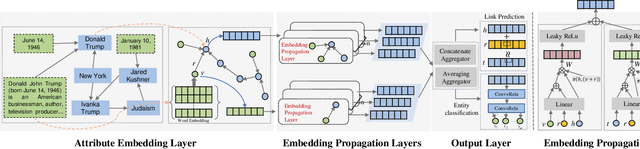
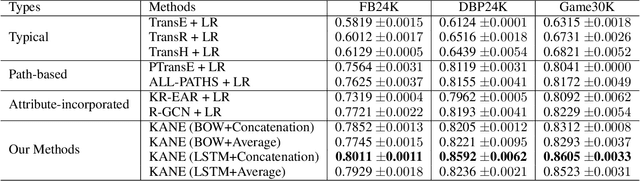
The goal of representation learning of knowledge graph is to encode both entities and relations into a low-dimensional embedding spaces. Many recent works have demonstrated the benefits of knowledge graph embedding on knowledge graph completion task, such as relation extraction. However, we observe that: 1) existing method just take direct relations between entities into consideration and fails to express high-order structural relationship between entities; 2) these methods just leverage relation triples of KGs while ignoring a large number of attribute triples that encoding rich semantic information. To overcome these limitations, this paper propose a novel knowledge graph embedding method, named KANE, which is inspired by the recent developments of graph convolutional networks (GCN). KANE can capture both high-order structural and attribute information of KGs in an efficient, explicit and unified manner under the graph convolutional networks framework. Empirical results on three datasets show that KANE significantly outperforms seven state-of-arts methods. Further analysis verify the efficiency of our method and the benefits brought by the attention mechanism.