 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix-Guided On-Policy Distillation: Mining Golden Trajectories from Rollouts
Jun 20, 2026On-policy distillation (OPD) improves reasoning models by applying dense teacher supervision on student-sampled trajectories. However, scaling OPD to long-horizon mathematical reasoning exposes a reliability and efficiency problem: standard OPD assigns every sampled candidate the same long rollout budget, even though some trajectories may quickly become weakly aligned with the teacher and provide less useful supervision. Prior analyses suggest that successful OPD depends on local teacher-student compatibility, which can be measured by top-k overlap on student-visited prefixes. When this overlap is low, continuing to generate or train on long suffixes may waste computation and introduce noisy learning signal. To address this, we introduce Prefix-Guided On-Policy Distillation (PG-OPD), a simple rollout-allocation framework that uses fixed-length prefixes to estimate trajectory value before expensive long-horizon generation. PG-OPD first decodes every sampled candidate to the same prefix length, computes teacher-student top-k overlap within an early probe window of that prefix, and selectively continues high-overlap candidates to a fixed long length. Low-overlap candidates stop at the fixed prefix, avoiding unnecessary suffix generation. Across diverse teacher-student combinations on AMC, AIME, and HMMT benchmarks, PG-OPD improves average accuracy by up to 4.80 points while reducing training time by up to 2.46x. These results suggest that prefix-level compatibility provides a practical signal for directing OPD computation toward trajectories that remain learnable from the teacher.
BPPO: Binary Prefix Policy Optimization for Efficient GRPO-Style Reasoning RL with Concise Responses
May 27, 2026Group Relative Policy Optimization (GRPO) is widely used for training reasoning models, but updating all sampled completions in each group incurs substantial cost and can reinforce verbose reasoning trajectories. In this paper, we study whether all completions provide equally useful update signals in GRPO-style reasoning RL. Our gradient-similarity analysis shows that, within the same prompt group, same-class completions often induce highly similar update directions, whereas correct-incorrect pairs provide more distinct contrastive signals. Motivated by this observation, we propose Binary Prefix Policy Optimization (BPPO), which uses the shortest correct completion and the shortest incorrect completion as a compact update unit while preserving full-group advantage normalization. BPPO further improves efficiency with adaptive completion scheduling and prefix-focused optimization; by updating only response prefixes, it avoids reinforcing redundant suffixes and encourages more concise responses. Experiments on GSM8K, MATH, and Geo3K show that BPPO achieves up to 6.08x speedup over GRPO while maintaining competitive accuracy, and reduces mean response length by approximately 30-50% without modifying the reward with an explicit length penalty.
Ruyi2.5 Technical Report
Mar 18, 2026We present Ruyi2.5, a multimodal familial model built on the AI Flow framework. Extending Ruyi2's "Train Once, Deploy Many" paradigm to the multimodal domain, Ruyi2.5 constructs a shared-backbone architecture that co-trains models of varying scales within a single unified pipeline, ensuring semantic consistency across all deployment tiers. Built upon Ruyi2.5, Ruyi2.5-Camera model is developed as a privacy-preserving camera service system, which instantiates Ruyi2.5-Camera into a two-stage recognition pipeline: an edge model applies information-bottleneck-guided irreversible feature mapping to de-identify raw frames at the source, while a cloud model performs deep behavior reasoning. To accelerate reinforcement learning fine-tuning, we further propose Binary Prefix Policy Optimization (BPPO), which reduces sample redundancy via binary response selection and focuses gradient updates on response prefixes, achieving a 2 to 3 times training speedup over GRPO. Experiments show Ruyi2.5 matches Qwen3-VL on the general multimodal benchmarks, while Ruyi2.5-Camera substantially outperforms Qwen3-VL on privacy-constrained surveillance tasks.
Privacy-Aware Camera 2.0 Technical Report
Mar 05, 2026With the increasing deployment of intelligent sensing technologies in highly sensitive environments such as restrooms and locker rooms, visual surveillance systems face a profound privacy-security paradox. Existing privacy-preserving approaches, including physical desensitization, encryption, and obfuscation, often compromise semantic understanding or fail to ensure mathematically provable irreversibility. Although Privacy Camera 1.0 eliminated visual data at the source to prevent leakage, it provided only textual judgments, leading to evidentiary blind spots in disputes. To address these limitations, this paper proposes a novel privacy-preserving perception framework based on the AI Flow paradigm and a collaborative edge-cloud architecture. By deploying a visual desensitizer at the edge, raw images are transformed in real time into abstract feature vectors through nonlinear mapping and stochastic noise injection under the Information Bottleneck principle, ensuring identity-sensitive information is stripped and original images are mathematically unreconstructable. The abstract representations are transmitted to the cloud for behavior recognition and semantic reconstruction via a "dynamic contour" visual language, achieving a critical balance between perception and privacy while enabling illustrative visual reference without exposing raw images.
Ruyi2 Technical Report
Feb 26, 2026Large Language Models (LLMs) face significant challenges regarding deployment costs and latency, necessitating adaptive computing strategies. Building upon the AI Flow framework, we introduce Ruyi2 as an evolution of our adaptive model series designed for efficient variable-depth computation. While early-exit architectures offer a viable efficiency-performance balance, the Ruyi model and existing methods often struggle with optimization complexity and compatibility with large-scale distributed training. To bridge this gap, Ruyi2 introduces a stable "Familial Model" based on Megatron-LM. By using 3D parallel training, it achieves a 2-3 times speedup over Ruyi, while performing comparably to same-sized Qwen3 models. These results confirm that family-based parameter sharing is a highly effective strategy, establishing a new "Train Once, Deploy Many" paradigm and providing a key reference for balancing architectural efficiency with high-performance capabilities.
A Real-Time Privacy-Preserving Behavior Recognition System via Edge-Cloud Collaboration
Jan 30, 2026As intelligent sensing expands into high-privacy environments such as restrooms and changing rooms, the field faces a critical privacy-security paradox. Traditional RGB surveillance raises significant concerns regarding visual recording and storage, while existing privacy-preserving methods-ranging from physical desensitization to traditional cryptographic or obfuscation techniques-often compromise semantic understanding capabilities or fail to guarantee mathematical irreversibility against reconstruction attacks. To address these challenges, this study presents a novel privacy-preserving perception technology based on the AI Flow theoretical framework and an edge-cloud collaborative architecture. The proposed methodology integrates source desensitization with irreversible feature mapping. Leveraging Information Bottleneck theory, the edge device performs millisecond-level processing to transform raw imagery into abstract feature vectors via non-linear mapping and stochastic noise injection. This process constructs a unidirectional information flow that strips identity-sensitive attributes, rendering the reconstruction of original images impossible. Subsequently, the cloud platform utilizes multimodal family models to perform joint inference solely on these abstract vectors to detect abnormal behaviors. This approach fundamentally severs the path to privacy leakage at the architectural level, achieving a breakthrough from video surveillance to de-identified behavior perception and offering a robust solution for risk management in high-sensitivity public spaces.
Theoretical Foundations of Scaling Law in Familial Models
Dec 29, 2025Neural scaling laws have become foundational for optimizing large language model (LLM) training, yet they typically assume a single dense model output. This limitation effectively overlooks "Familial models, a transformative paradigm essential for realizing ubiquitous intelligence across heterogeneous device-edge-cloud hierarchies. Transcending static architectures, familial models integrate early exits with relay-style inference to spawn G deployable sub-models from a single shared backbone. In this work, we theoretically and empirically extend the scaling law to capture this "one-run, many-models" paradigm by introducing Granularity (G) as a fundamental scaling variable alongside model size (N) and training tokens (D). To rigorously quantify this relationship, we propose a unified functional form L(N, D, G) and parameterize it using large-scale empirical runs. Specifically, we employ a rigorous IsoFLOP experimental design to strictly isolate architectural impact from computational scale. Across fixed budgets, we systematically sweep model sizes (N) and granularities (G) while dynamically adjusting tokens (D). This approach effectively decouples the marginal cost of granularity from the benefits of scale, ensuring high-fidelity parameterization of our unified scaling law. Our results reveal that the granularity penalty follows a multiplicative power law with an extremely small exponent. Theoretically, this bridges fixed-compute training with dynamic architectures. Practically, it validates the "train once, deploy many" paradigm, demonstrating that deployment flexibility is achievable without compromising the compute-optimality of dense baselines.
DS@GT at CheckThat! 2025: Exploring Retrieval and Reranking Pipelines for Scientific Claim Source Retrieval on Social Media Discourse
Jul 09, 2025Social media users often make scientific claims without citing where these claims come from, generating a need to verify these claims. This paper details work done by the DS@GT team for CLEF 2025 CheckThat! Lab Task 4b Scientific Claim Source Retrieval which seeks to find relevant scientific papers based on implicit references in tweets. Our team explored 6 different data augmentation techniques, 7 different retrieval and reranking pipelines, and finetuned a bi-encoder. Achieving an MRR@5 of 0.58, our team ranked 16th out of 30 teams for the CLEF 2025 CheckThat! Lab Task 4b, and improvement of 0.15 over the BM25 baseline of 0.43. Our code is available on Github at https://github.com/dsgt-arc/checkthat-2025-swd/tree/main/subtask-4b.
Causality-aware Concept Extraction based on Knowledge-guided Prompting
May 10, 2023Concepts benefit natural language understanding but are far from complete in existing knowledge graphs (KGs). Recently, pre-trained language models (PLMs) have been widely used in text-based concept extraction (CE). However, PLMs tend to mine the co-occurrence associations from massive corpus as pre-trained knowledge rather than the real causal effect between tokens. As a result, the pre-trained knowledge confounds PLMs to extract biased concepts based on spurious co-occurrence correlations, inevitably resulting in low precision. In this paper, through the lens of a Structural Causal Model (SCM), we propose equipping the PLM-based extractor with a knowledge-guided prompt as an intervention to alleviate concept bias. The prompt adopts the topic of the given entity from the existing knowledge in KGs to mitigate the spurious co-occurrence correlations between entities and biased concepts. Our extensive experiments on representative multilingual KG datasets justify that our proposed prompt can effectively alleviate concept bias and improve the performance of PLM-based CE models.The code has been released on https://github.com/siyuyuan/KPCE.
Relation-Specific Attentions over Entity Mentions for Enhanced Document-Level Relation Extraction
May 28, 2022
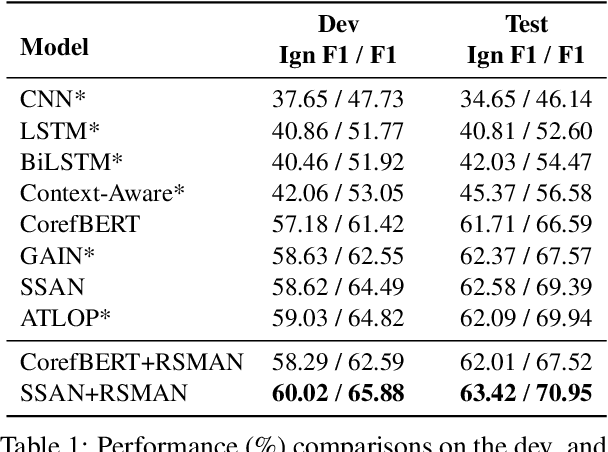
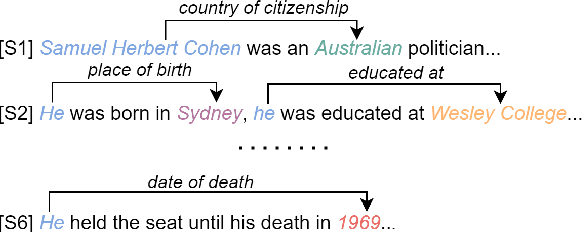
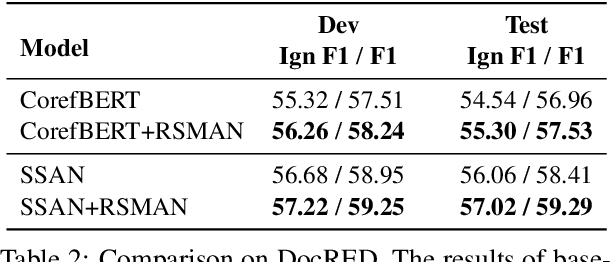
Compared with traditional sentence-level relation extraction, document-level relation extraction is a more challenging task where an entity in a document may be mentioned multiple times and associated with multiple relations. However, most methods of document-level relation extraction do not distinguish between mention-level features and entity-level features, and just apply simple pooling operation for aggregating mention-level features into entity-level features. As a result, the distinct semantics between the different mentions of an entity are overlooked. To address this problem, we propose RSMAN in this paper which performs selective attentions over different entity mentions with respect to candidate relations. In this manner, the flexible and relation-specific representations of entities are obtained which indeed benefit relation classification. Our extensive experiments upon two benchmark datasets show that our RSMAN can bring significant improvements for some backbone models to achieve state-of-the-art performance, especially when an entity have multiple mentions in the document.