 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Machine-Generated Texts: Not Just "AI vs Humans" and Explainability is Complicated
Jun 26, 2024



As LLMs rapidly advance, increasing concerns arise regarding risks about actual authorship of texts we see online and in real world. The task of distinguishing LLM-authored texts is complicated by the nuanced and overlapping behaviors of both machines and humans. In this paper, we challenge the current practice of considering LLM-generated text detection a binary classification task of differentiating human from AI. Instead, we introduce a novel ternary text classification scheme, adding an "undecided" category for texts that could be attributed to either source, and we show that this new category is crucial to understand how to make the detection result more explainable to lay users. This research shifts the paradigm from merely classifying to explaining machine-generated texts, emphasizing need for detectors to provide clear and understandable explanations to users. Our study involves creating four new datasets comprised of texts from various LLMs and human authors. Based on new datasets, we performed binary classification tests to ascertain the most effective SOTA detection methods and identified SOTA LLMs capable of producing harder-to-detect texts. We constructed a new dataset of texts generated by two top-performing LLMs and human authors, and asked three human annotators to produce ternary labels with explanation notes. This dataset was used to investigate how three top-performing SOTA detectors behave in new ternary classification context. Our results highlight why "undecided" category is much needed from the viewpoint of explainability. Additionally, we conducted an analysis of explainability of the three best-performing detectors and the explanation notes of the human annotators, revealing insights about the complexity of explainable detection of machine-generated texts. Finally, we propose guidelines for developing future detection systems with improved explanatory power.
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
Nov 16, 2023



Mis- and disinformation online have become a major societal problem as major sources of online harms of different kinds. One common form of mis- and disinformation is out-of-context (OOC) information, where different pieces of information are falsely associated, e.g., a real image combined with a false textual caption or a misleading textual description. Although some past studies have attempted to defend against OOC mis- and disinformation through external evidence, they tend to disregard the role of different pieces of evidence with different stances. Motivated by the intuition that the stance of evidence represents a bias towards different detection results, we propose a stance extraction network (SEN) that can extract the stances of different pieces of multi-modal evidence in a unified framework. Moreover, we introduce a support-refutation score calculated based on the co-occurrence relations of named entities into the textual SEN. Extensive experiments on a public large-scale dataset demonstrated that our proposed method outperformed the state-of-the-art baselines, with the best model achieving a performance gain of 3.2% in accuracy.
SE#PCFG: Semantically Enhanced PCFG for Password Analysis and Cracking
Jun 12, 2023



Much research has been done on user-generated textual passwords. Surprisingly, semantic information in such passwords remain underinvestigated, with passwords created by English- and/or Chinese-speaking users being more studied with limited semantics. This paper fills this gap by proposing a general framework based on semantically enhanced PCFG (probabilistic context-free grammars) named SE#PCFG. It allowed us to consider 43 types of semantic information, the richest set considered so far, for semantic password analysis. Applying SE#PCFG to 17 large leaked password databases of user speaking four languages (English, Chinese, German and French), we demonstrate its usefulness and report a wide range of new insights about password semantics at different levels such as cross-website password correlations. Furthermore, based on SE#PCFG and a new systematic smoothing method, we proposed the Semantically Enhanced Password Cracking Architecture (SEPCA). To compare the performance of SEPCA against three state-of-the-art (SOTA) benchmarks in terms of the password coverage rate: two other PCFG variants and FLA. Our experimental results showed that SEPCA outperformed all the three benchmarks consistently and significantly across 52 test cases, by up to 21.53%, 52.55% and 7.86%, respectively, at the user level (with duplicate passwords). At the level of unique passwords, SEPCA also beats the three benchmarks by up to 33.32%, 86.19% and 10.46%, respectively. The results demonstrated the power of SEPCA as a new password cracking framework.
aedFaCT: Scientific Fact-Checking Made Easier via Semi-Automatic Discovery of Relevant Expert Opinions
May 12, 2023



In this highly digitised world, fake news is a challenging problem that can cause serious harm to society. Considering how fast fake news can spread, automated methods, tools and services for assisting users to do fact-checking (i.e., fake news detection) become necessary and helpful, for both professionals, such as journalists and researchers, and the general public such as news readers. Experts, especially researchers, play an essential role in informing people about truth and facts, which makes them a good proxy for non-experts to detect fake news by checking relevant expert opinions and comments. Therefore, in this paper, we present aedFaCT, a web browser extension that can help professionals and news readers perform fact-checking via the automatic discovery of expert opinions relevant to the news of concern via shared keywords. Our initial evaluation with three independent testers (who did not participate in the development of the extension) indicated that aedFaCT can provide a faster experience to its users compared with traditional fact-checking practices based on manual online searches, without degrading the quality of retrieved evidence for fact-checking. The source code of aedFaCT is publicly available at https://github.com/altuncu/aedFaCT.
Visualising Personal Data Flows: Insights from a Case Study of Booking.com
Apr 20, 2023Commercial organisations are holding and processing an ever-increasing amount of personal data. Policies and laws are continually changing to require these companies to be more transparent regarding collection, storage, processing and sharing of this data. This paper reports our work of taking 'Booking.com' as a case study to visualise personal data flows extracted from their privacy policy. By showcasing how the company shares its consumers' personal data, we raise questions and extend discussions on the challenges and limitations of using privacy policy to inform customers the true scale and landscape of personal data flows. More importantly, this case study can inform us about future research on more data flow-oriented privacy policy analysis and on the construction of a more comprehensive ontology on personal data flows in complicated business ecosystems.
Proof of Swarm Based Ensemble Learning for Federated Learning Applications
Jan 02, 2023Ensemble learning combines results from multiple machine learning models in order to provide a better and optimised predictive model with reduced bias, variance and improved predictions. However, in federated learning it is not feasible to apply centralised ensemble learning directly due to privacy concerns. Hence, a mechanism is required to combine results of local models to produce a global model. Most distributed consensus algorithms, such as Byzantine fault tolerance (BFT), do not normally perform well in such applications. This is because, in such methods predictions of some of the peers are disregarded, so a majority of peers can win without even considering other peers' decisions. Additionally, the confidence score of the result of each peer is not normally taken into account, although it is an important feature to consider for ensemble learning. Moreover, the problem of a tie event is often left un-addressed by methods such as BFT. To fill these research gaps, we propose PoSw (Proof of Swarm), a novel distributed consensus algorithm for ensemble learning in a federated setting, which was inspired by particle swarm based algorithms for solving optimisation problems. The proposed algorithm is theoretically proved to always converge in a relatively small number of steps and has mechanisms to resolve tie events while trying to achieve sub-optimum solutions. We experimentally validated the performance of the proposed algorithm using ECG classification as an example application in healthcare, showing that the ensemble learning model outperformed all local models and even the FL-based global model. To the best of our knowledge, the proposed algorithm is the first attempt to make consensus over the output results of distributed models trained using federated learning.
Improving Performance of Automatic Keyword Extraction (AKE) Methods Using PoS-Tagging and Enhanced Semantic-Awareness
Nov 09, 2022



Automatic keyword extraction (AKE) has gained more importance with the increasing amount of digital textual data that modern computing systems process. It has various applications in information retrieval (IR) and natural language processing (NLP), including text summarisation, topic analysis and document indexing. This paper proposes a simple but effective post-processing-based universal approach to improve the performance of any AKE methods, via an enhanced level of semantic-awareness supported by PoS-tagging. To demonstrate the performance of the proposed approach, we considered word types retrieved from a PoS-tagging step and two representative sources of semantic information -- specialised terms defined in one or more context-dependent thesauri, and named entities in Wikipedia. The above three steps can be simply added to the end of any AKE methods as part of a post-processor, which simply re-evaluate all candidate keywords following some context-specific and semantic-aware criteria. For five state-of-the-art (SOTA) AKE methods, our experimental results with 17 selected datasets showed that the proposed approach improved their performances both consistently (up to 100\% in terms of improved cases) and significantly (between 10.2\% and 53.8\%, with an average of 25.8\%, in terms of F1-score and across all five methods), especially when all the three enhancement steps are used. Our results have profound implications considering the ease to apply our proposed approach to any AKE methods and to further extend it.
Recovering Sign Bits of DCT Coefficients in Digital Images as an Optimization Problem
Nov 02, 2022Recovering unknown, missing, damaged, distorted or lost information in DCT coefficients is a common task in multiple applications of digital image processing, including image compression, selective image encryption, and image communications. This paper investigates recovery of a special type of information in DCT coefficients of digital images: sign bits. This problem can be modelled as a mixed integer linear programming (MILP) problem, which is NP-hard in general. To efficiently solve the problem, we propose two approximation methods: 1) a relaxation-based method that convert the MILP problem to a linear programming (LP) problem; 2) a divide-and-conquer method which splits the target image into sufficiently small regions, each of which can be more efficiently solved as an MILP problem, and then conducts a global optimization phase as a smaller MILP problem or an LP problem to maximize smoothness across different regions. To the best of our knowledge, we are the first who considered how to use global optimization to recover sign bits of DCT coefficients. We considered how the proposed methods can be applied to JPEG-encoded images and conducted extensive experiments to validate the performances of our proposed methods. The experimental results showed that the proposed methods worked well, especially when the number of unknown sign bits per DCT block is not too large. Compared with other existing methods, which are all based on simple error-concealment strategies, our proposed methods outperformed them with a substantial margin, both according to objective quality metrics (PSNR and SSIM) and also our subjective evaluation. Our work has a number of profound implications, e.g., more sign bits can be discarded to develop more efficient image compression methods, and image encryption methods based on sign bit encryption can be less secure than we previously understood.
Graphical Models of False Information and Fact Checking Ecosystems
Aug 24, 2022
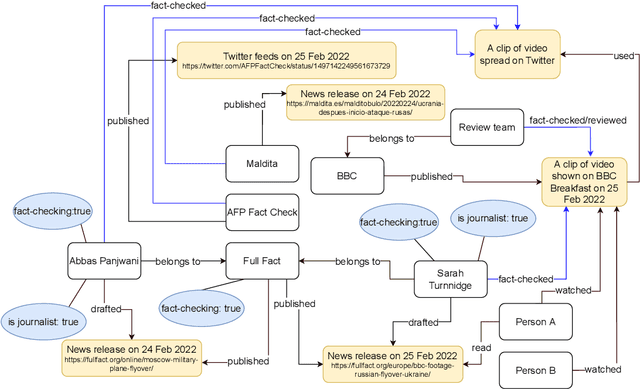
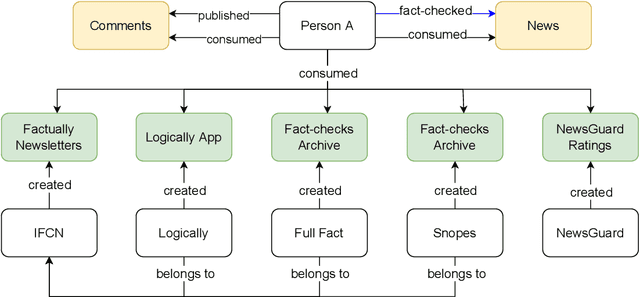
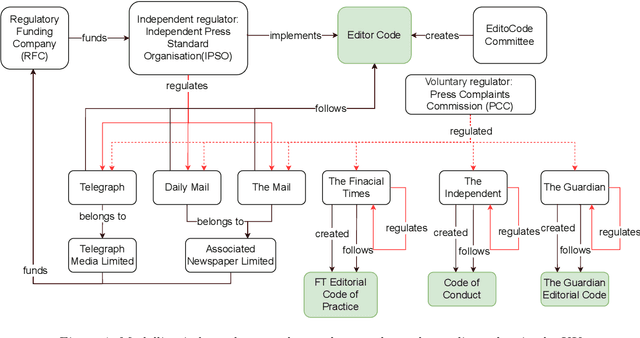
The wide spread of false information online including misinformation and disinformation has become a major problem for our highly digitised and globalised society. A lot of research has been done to better understand different aspects of false information online such as behaviours of different actors and patterns of spreading, and also on better detection and prevention of such information using technical and socio-technical means. One major approach to detect and debunk false information online is to use human fact-checkers, who can be helped by automated tools. Despite a lot of research done, we noticed a significant gap on the lack of conceptual models describing the complicated ecosystems of false information and fact checking. In this paper, we report the first graphical models of such ecosystems, focusing on false information online in multiple contexts, including traditional media outlets and user-generated content. The proposed models cover a wide range of entity types and relationships, and can be a new useful tool for researchers and practitioners to study false information online and the effects of fact checking.
Deepfake: Definitions, Performance Metrics and Standards, Datasets and Benchmarks, and a Meta-Review
Aug 21, 2022
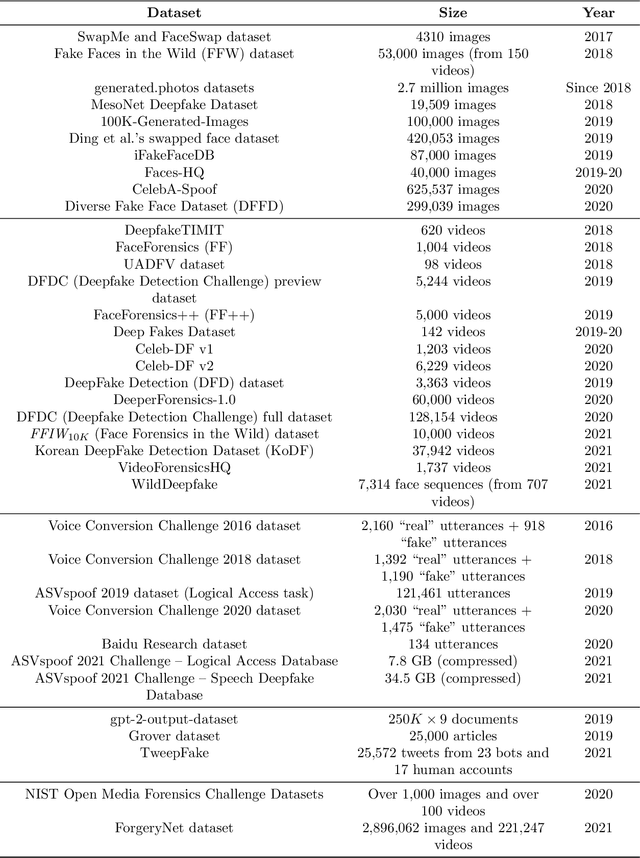
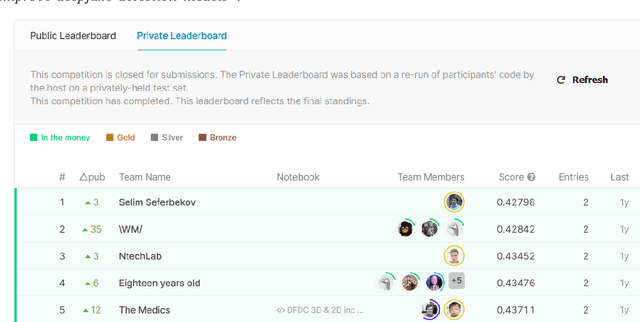
Recent advancements in AI, especially deep learning, have contributed to a significant increase in the creation of new realistic-looking synthetic media (video, image, and audio) and manipulation of existing media, which has led to the creation of the new term ``deepfake''. Based on both the research literature and resources in English and in Chinese, this paper gives a comprehensive overview of deepfake, covering multiple important aspects of this emerging concept, including 1) different definitions, 2) commonly used performance metrics and standards, and 3) deepfake-related datasets, challenges, competitions and benchmarks. In addition, the paper also reports a meta-review of 12 selected deepfake-related survey papers published in 2020 and 2021, focusing not only on the mentioned aspects, but also on the analysis of key challenges and recommendations. We believe that this paper is the most comprehensive review of deepfake in terms of aspects covered, and the first one covering both the English and Chinese literature and sources.