 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend and Select: A Segment Attention based Selection Mechanism for Microblog Hashtag Generation
Jun 06, 2021

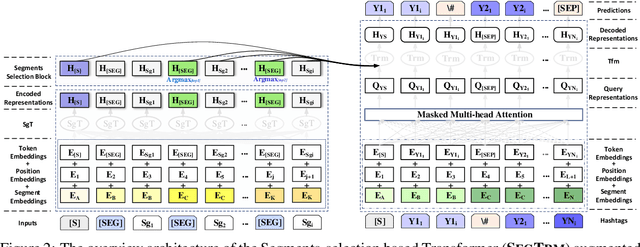
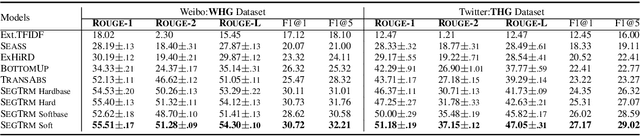
Automatic microblog hashtag generation can help us better and faster understand or process the critical content of microblog posts. Conventional sequence-to-sequence generation methods can produce phrase-level hashtags and have achieved remarkable performance on this task. However, they are incapable of filtering out secondary information and not good at capturing the discontinuous semantics among crucial tokens. A hashtag is formed by tokens or phrases that may originate from various fragmentary segments of the original text. In this work, we propose an end-to-end Transformer-based generation model which consists of three phases: encoding, segments-selection, and decoding. The model transforms discontinuous semantic segments from the source text into a sequence of hashtags. Specifically, we introduce a novel Segments Selection Mechanism (SSM) for Transformer to obtain segmental representations tailored to phrase-level hashtag generation. Besides, we introduce two large-scale hashtag generation datasets, which are newly collected from Chinese Weibo and English Twitter. Extensive evaluations on the two datasets reveal our approach's superiority with significant improvements to extraction and generation baselines. The code and datasets are available at \url{https://github.com/OpenSUM/HashtagGen}.
Bipartite Graph Embedding via Mutual Information Maximization
Dec 10, 2020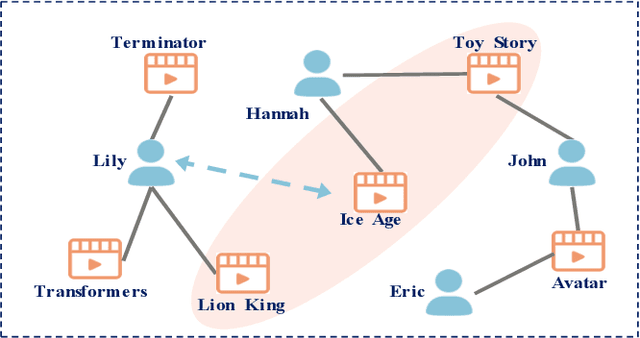
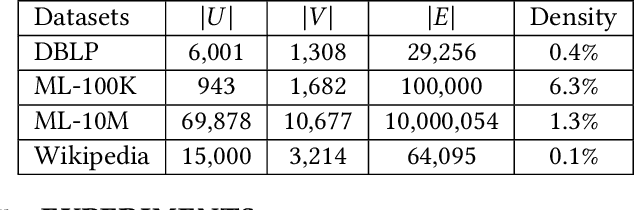
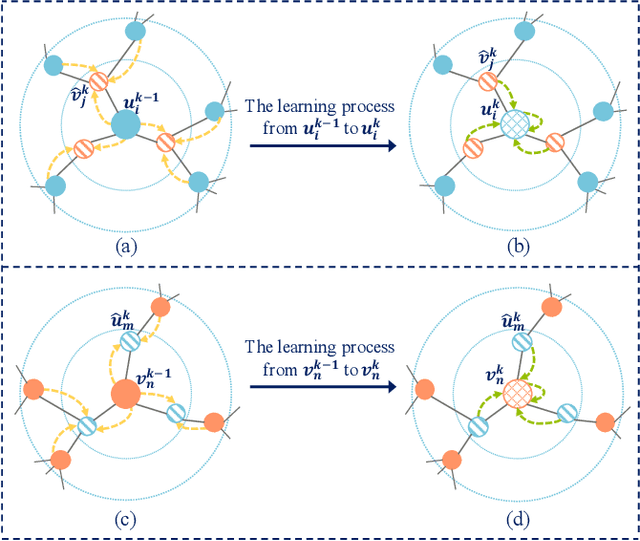
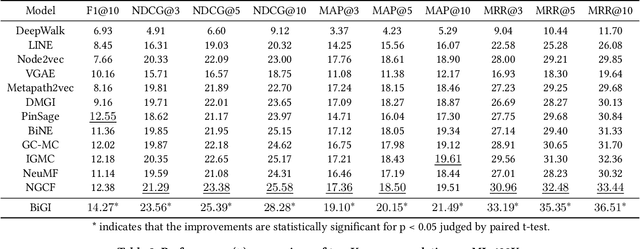
Bipartite graph embedding has recently attracted much attention due to the fact that bipartite graphs are widely used in various application domains. Most previous methods, which adopt random walk-based or reconstruction-based objectives, are typically effective to learn local graph structures. However, the global properties of bipartite graph, including community structures of homogeneous nodes and long-range dependencies of heterogeneous nodes, are not well preserved. In this paper, we propose a bipartite graph embedding called BiGI to capture such global properties by introducing a novel local-global infomax objective. Specifically, BiGI first generates a global representation which is composed of two prototype representations. BiGI then encodes sampled edges as local representations via the proposed subgraph-level attention mechanism. Through maximizing the mutual information between local and global representations, BiGI enables nodes in bipartite graph to be globally relevant. Our model is evaluated on various benchmark datasets for the tasks of top-K recommendation and link prediction. Extensive experiments demonstrate that BiGI achieves consistent and significant improvements over state-of-the-art baselines. Detailed analyses verify the high effectiveness of modeling the global properties of bipartite graph.
Adaptive Attentional Network for Few-Shot Knowledge Graph Completion
Oct 19, 2020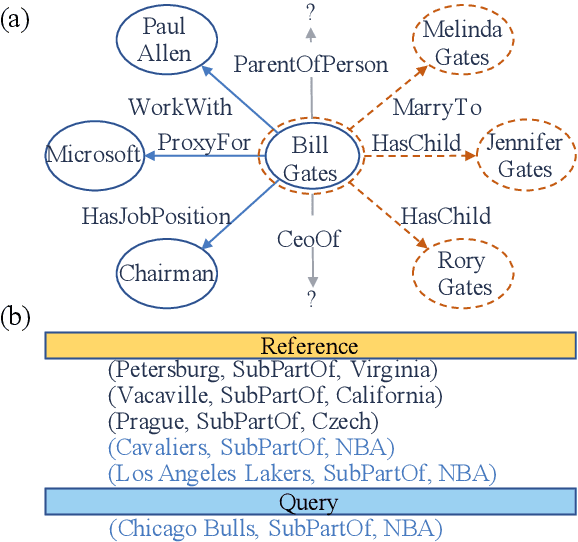

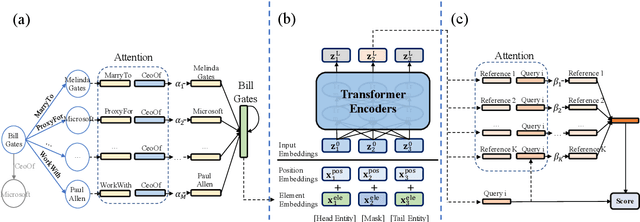
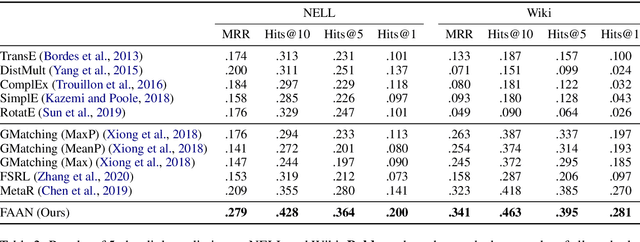
Few-shot Knowledge Graph (KG) completion is a focus of current research, where each task aims at querying unseen facts of a relation given its few-shot reference entity pairs. Recent attempts solve this problem by learning static representations of entities and references, ignoring their dynamic properties, i.e., entities may exhibit diverse roles within task relations, and references may make different contributions to queries. This work proposes an adaptive attentional network for few-shot KG completion by learning adaptive entity and reference representations. Specifically, entities are modeled by an adaptive neighbor encoder to discern their task-oriented roles, while references are modeled by an adaptive query-aware aggregator to differentiate their contributions. Through the attention mechanism, both entities and references can capture their fine-grained semantic meanings, and thus render more expressive representations. This will be more predictive for knowledge acquisition in the few-shot scenario. Evaluation in link prediction on two public datasets shows that our approach achieves new state-of-the-art results with different few-shot sizes.
Knowledge Graph Embedding with Iterative Guidance from Soft Rules
Nov 30, 2017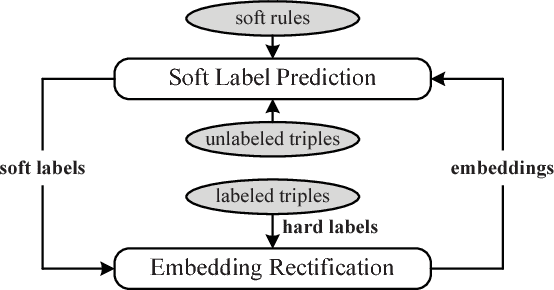

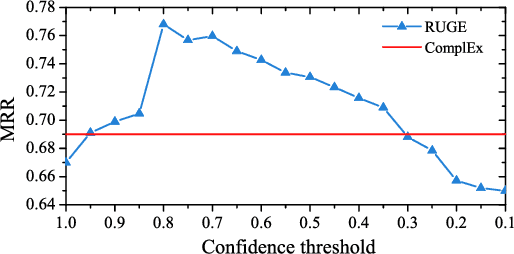
Embedding knowledge graphs (KGs) into continuous vector spaces is a focus of current research. Combining such an embedding model with logic rules has recently attracted increasing attention. Most previous attempts made a one-time injection of logic rules, ignoring the interactive nature between embedding learning and logical inference. And they focused only on hard rules, which always hold with no exception and usually require extensive manual effort to create or validate. In this paper, we propose Rule-Guided Embedding (RUGE), a novel paradigm of KG embedding with iterative guidance from soft rules. RUGE enables an embedding model to learn simultaneously from 1) labeled triples that have been directly observed in a given KG, 2) unlabeled triples whose labels are going to be predicted iteratively, and 3) soft rules with various confidence levels extracted automatically from the KG. In the learning process, RUGE iteratively queries rules to obtain soft labels for unlabeled triples, and integrates such newly labeled triples to update the embedding model. Through this iterative procedure, knowledge embodied in logic rules may be better transferred into the learned embeddings. We evaluate RUGE in link prediction on Freebase and YAGO. Experimental results show that: 1) with rule knowledge injected iteratively, RUGE achieves significant and consistent improvements over state-of-the-art baselines; and 2) despite their uncertainties, automatically extracted soft rules are highly beneficial to KG embedding, even those with moderate confidence levels. The code and data used for this paper can be obtained from https://github.com/iieir-km/RUGE.