 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolden Layers and Where to Find Them: Improved Knowledge Editing for Large Language Models Via Layer Gradient Analysis
Feb 22, 2026Knowledge editing in Large Language Models (LLMs) aims to update the model's prediction for a specific query to a desired target while preserving its behavior on all other inputs. This process typically involves two stages: identifying the layer to edit and performing the parameter update. Intuitively, different queries may localize knowledge at different depths of the model, resulting in different sample-wise editing performance for a fixed editing layer. In this work, we hypothesize the existence of fixed golden layers that can achieve near-optimal editing performance similar to sample-wise optimal layers. To validate this hypothesis, we provide empirical evidence by comparing golden layers against ground-truth sample-wise optimal layers. Furthermore, we show that golden layers can be reliably identified using a proxy dataset and generalize effectively to unseen test set queries across datasets. Finally, we propose a novel method, namely Layer Gradient Analysis (LGA) that estimates golden layers efficiently via gradient-attribution, avoiding extensive trial-and-error across multiple editing runs. Extensive experiments on several benchmark datasets demonstrate the effectiveness and robustness of our LGA approach across different LLM types and various knowledge editing methods.
BanglaIPA: Towards Robust Text-to-IPA Transcription with Contextual Rewriting in Bengali
Jan 05, 2026Despite its widespread use, Bengali lacks a robust automated International Phonetic Alphabet (IPA) transcription system that effectively supports both standard language and regional dialectal texts. Existing approaches struggle to handle regional variations, numerical expressions, and generalize poorly to previously unseen words. To address these limitations, we propose BanglaIPA, a novel IPA generation system that integrates a character-based vocabulary with word-level alignment. The proposed system accurately handles Bengali numerals and demonstrates strong performance across regional dialects. BanglaIPA improves inference efficiency by leveraging a precomputed word-to-IPA mapping dictionary for previously observed words. The system is evaluated on the standard Bengali and six regional variations of the DUAL-IPA dataset. Experimental results show that BanglaIPA outperforms baseline IPA transcription models by 58.4-78.7% and achieves an overall mean word error rate of 11.4%, highlighting its robustness in phonetic transcription generation for the Bengali language.
From Scarcity to Capability: Empowering Fake News Detection in Low-Resource Languages with LLMs
Jan 16, 2025
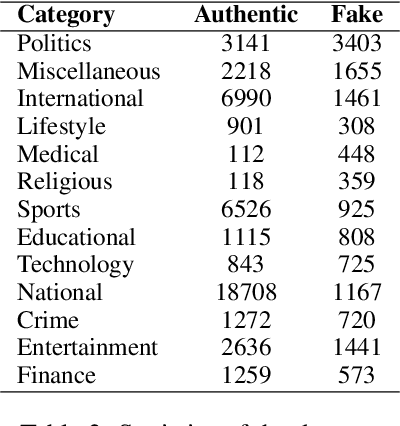

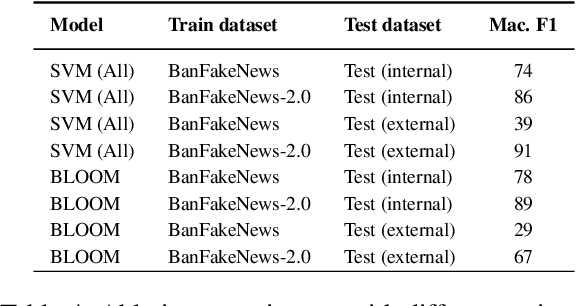
The rapid spread of fake news presents a significant global challenge, particularly in low-resource languages like Bangla, which lack adequate datasets and detection tools. Although manual fact-checking is accurate, it is expensive and slow to prevent the dissemination of fake news. Addressing this gap, we introduce BanFakeNews-2.0, a robust dataset to enhance Bangla fake news detection. This version includes 11,700 additional, meticulously curated fake news articles validated from credible sources, creating a proportional dataset of 47,000 authentic and 13,000 fake news items across 13 categories. In addition, we created a manually curated independent test set of 460 fake and 540 authentic news items for rigorous evaluation. We invest efforts in collecting fake news from credible sources and manually verified while preserving the linguistic richness. We develop a benchmark system utilizing transformer-based architectures, including fine-tuned Bidirectional Encoder Representations from Transformers variants (F1-87\%) and Large Language Models with Quantized Low-Rank Approximation (F1-89\%), that significantly outperforms traditional methods. BanFakeNews-2.0 offers a valuable resource to advance research and application in fake news detection for low-resourced languages. We publicly release our dataset and model on Github to foster research in this direction.
Character-Level Bangla Text-to-IPA Transcription Using Transformer Architecture with Sequence Alignment
Nov 07, 2023The International Phonetic Alphabet (IPA) is indispensable in language learning and understanding, aiding users in accurate pronunciation and comprehension. Additionally, it plays a pivotal role in speech therapy, linguistic research, accurate transliteration, and the development of text-to-speech systems, making it an essential tool across diverse fields. Bangla being 7th as one of the widely used languages, gives rise to the need for IPA in its domain. Its IPA mapping is too diverse to be captured manually giving the need for Artificial Intelligence and Machine Learning in this field. In this study, we have utilized a transformer-based sequence-to-sequence model at the letter and symbol level to get the IPA of each Bangla word as the variation of IPA in association of different words is almost null. Our transformer model only consisted of 8.5 million parameters with only a single decoder and encoder layer. Additionally, to handle the punctuation marks and the occurrence of foreign languages in the text, we have utilized manual mapping as the model won't be able to learn to separate them from Bangla words while decreasing our required computational resources. Finally, maintaining the relative position of the sentence component IPAs and generation of the combined IPA has led us to achieve the top position with a word error rate of 0.10582 in the public ranking of DataVerse Challenge - ITVerse 2023 (https://www.kaggle.com/competitions/dataverse_2023/).
Performance Enhancement Leveraging Mask-RCNN on Bengali Document Layout Analysis
Aug 22, 2023Understanding digital documents is like solving a puzzle, especially historical ones. Document Layout Analysis (DLA) helps with this puzzle by dividing documents into sections like paragraphs, images, and tables. This is crucial for machines to read and understand these documents. In the DL Sprint 2.0 competition, we worked on understanding Bangla documents. We used a dataset called BaDLAD with lots of examples. We trained a special model called Mask R-CNN to help with this understanding. We made this model better by step-by-step hyperparameter tuning, and we achieved a good dice score of 0.889. However, not everything went perfectly. We tried using a model trained for English documents, but it didn't fit well with Bangla. This showed us that each language has its own challenges. Our solution for the DL Sprint 2.0 is publicly available at https://www.kaggle.com/competitions/dlsprint2/discussion/432201 along with notebooks, weights, and inference notebook.