 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: The Systemic Lack of Agency in Visual Reasoning
Jun 11, 2026This paper argues that a systemic lack of Agency constrains the implicit reasoning capabilities of current Vision-Language Models (VLMs). Implicit reasoning refers to the ability to autonomously discover and utilize hidden visual evidence to bridge information gaps, rather than merely relying on explicitly specified targets. This capacity underlies human visual understanding and everyday reasoning. We argue that this limitation arises from a tendency to approach visual reasoning primarily as passive semantic retrieval, rather than as active, situated reasoning that depends on autonomous visual exploration. As a result, most existing benchmarks primarily assess Passive Capacity, leaving this aspect of reasoning largely unmeasured. To address this gap, we introduce the Visual Implicit Reasoning Diagnosing Benchmark (V-IRD), which targets this missing quadrant by requiring models to derive answers strictly through autonomous visual analysis. Our results show that, despite strong retrieval abilities, prominent VLMs struggle to utilize reference objects and to attend to visual evidence that requires self-directed inquiry. Simply put, strong semantic recognition does not equate to active visual exploration, revealing a critical gap in current VLMs. More information can be found at https://haoychen.github.io/Implicit-Reasoning/
Heuristic Self-Paced Learning for Domain Adaptive Semantic Segmentation under Adverse Conditions
Mar 25, 2026The learning order of semantic classes significantly impacts unsupervised domain adaptation for semantic segmentation, especially under adverse weather conditions. Most existing curricula rely on handcrafted heuristics (e.g., fixed uncertainty metrics) and follow a static schedule, which fails to adapt to a model's evolving, high-dimensional training dynamics, leading to category bias. Inspired by Reinforcement Learning, we cast curriculum learning as a sequential decision problem and propose an autonomous class scheduler. This scheduler consists of two components: (i) a high-dimensional state encoder that maps the model's training status into a latent space and distills key features indicative of progress, and (ii) a category-fair policy-gradient objective that ensures balanced improvement across classes. Coupled with mixed source-target supervision, the learned class rankings direct the network's focus to the most informative classes at each stage, enabling more adaptive and dynamic learning. It is worth noting that our method achieves state-of-the-art performance on three widely used benchmarks (e.g., ACDC, Dark Zurich, and Nighttime Driving) and shows generalization ability in synthetic-to-real semantic segmentation.
Any2Any: Unified Arbitrary Modality Translation for Remote Sensing
Mar 04, 2026Multi-modal remote sensing imagery provides complementary observations of the same geographic scene, yet such observations are frequently incomplete in practice. Existing cross-modal translation methods treat each modality pair as an independent task, resulting in quadratic complexity and limited generalization to unseen modality combinations. We formulate Any-to-Any translation as inference over a shared latent representation of the scene, where different modalities correspond to partial observations of the same underlying semantics. Based on this formulation, we propose Any2Any, a unified latent diffusion framework that projects heterogeneous inputs into a geometrically aligned latent space. Such structure performs anchored latent regression with a shared backbone, decoupling modality-specific representation learning from semantic mapping. Moreover, lightweight target-specific residual adapters are used to correct systematic latent mismatches without increasing inference complexity. To support learning under sparse but connected supervision, we introduce RST-1M, the first million-scale remote sensing dataset with paired observations across five sensing modalities, providing supervision anchors for any-to-any translation. Experiments across 14 translation tasks show that Any2Any consistently outperforms pairwise translation methods and exhibits strong zero-shot generalization to unseen modality pairs. Code and models will be available at https://github.com/MiliLab/Any2Any.
Shapley-Coop: Credit Assignment for Emergent Cooperation in Self-Interested LLM Agents
Jun 09, 2025



Large Language Models (LLMs) show strong collaborative performance in multi-agent systems with predefined roles and workflows. However, in open-ended environments lacking coordination rules, agents tend to act in self-interested ways. The central challenge in achieving coordination lies in credit assignment -- fairly evaluating each agent's contribution and designing pricing mechanisms that align their heterogeneous goals. This problem is critical as LLMs increasingly participate in complex human-AI collaborations, where fair compensation and accountability rely on effective pricing mechanisms. Inspired by how human societies address similar coordination challenges (e.g., through temporary collaborations such as employment or subcontracting), we propose a cooperative workflow, Shapley-Coop. Shapley-Coop integrates Shapley Chain-of-Thought -- leveraging marginal contributions as a principled basis for pricing -- with structured negotiation protocols for effective price matching, enabling LLM agents to coordinate through rational task-time pricing and post-task reward redistribution. This approach aligns agent incentives, fosters cooperation, and maintains autonomy. We evaluate Shapley-Coop across two multi-agent games and a software engineering simulation, demonstrating that it consistently enhances LLM agent collaboration and facilitates equitable credit assignment. These results highlight the effectiveness of Shapley-Coop's pricing mechanisms in accurately reflecting individual contributions during task execution.
Exploring Image Enhancement for Salient Object Detection in Low Light Images
Jul 31, 2020
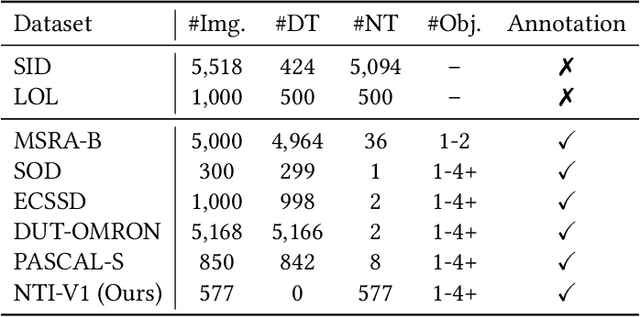
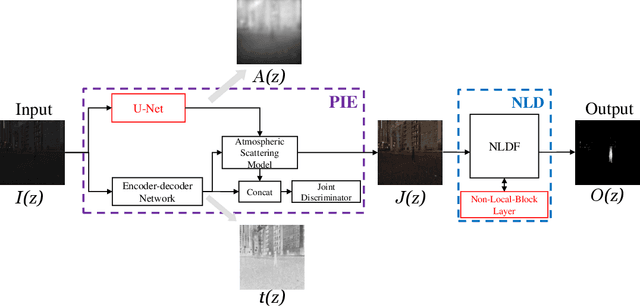
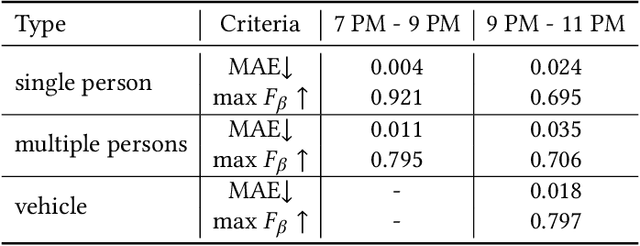
Low light images captured in a non-uniform illumination environment usually are degraded with the scene depth and the corresponding environment lights. This degradation results in severe object information loss in the degraded image modality, which makes the salient object detection more challenging due to low contrast property and artificial light influence. However, existing salient object detection models are developed based on the assumption that the images are captured under a sufficient brightness environment, which is impractical in real-world scenarios. In this work, we propose an image enhancement approach to facilitate the salient object detection in low light images. The proposed model directly embeds the physical lighting model into the deep neural network to describe the degradation of low light images, in which the environment light is treated as a point-wise variate and changes with local content. Moreover, a Non-Local-Block Layer is utilized to capture the difference of local content of an object against its local neighborhood favoring regions. To quantitative evaluation, we construct a low light Images dataset with pixel-level human-labeled ground-truth annotations and report promising results on four public datasets and our benchmark dataset.