 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
Mar 19, 2020
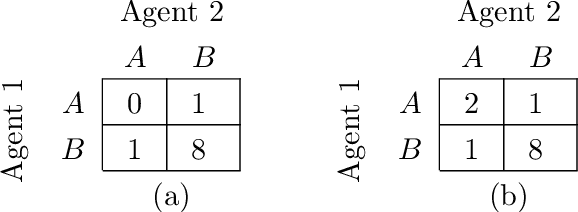
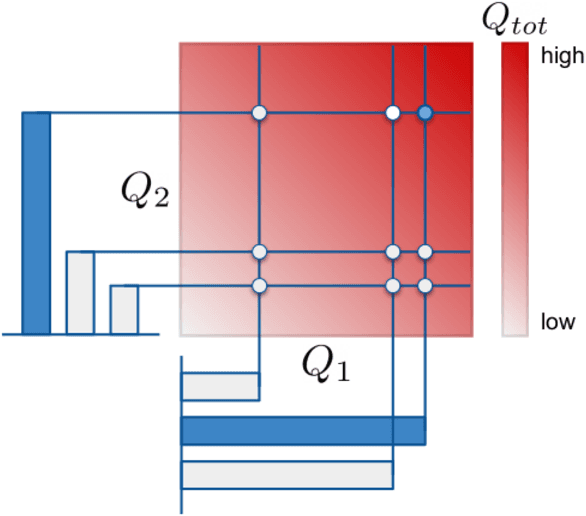
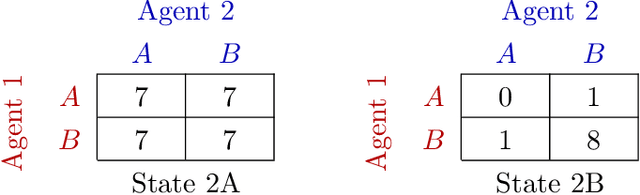
In many real-world settings, a team of agents must coordinate its behaviour while acting in a decentralised fashion. At the same time, it is often possible to train the agents in a centralised fashion where global state information is available and communication constraints are lifted. Learning joint action-values conditioned on extra state information is an attractive way to exploit centralised learning, but the best strategy for then extracting decentralised policies is unclear. Our solution is QMIX, a novel value-based method that can train decentralised policies in a centralised end-to-end fashion. QMIX employs a mixing network that estimates joint action-values as a monotonic combination of per-agent values. We structurally enforce that the joint-action value is monotonic in the per-agent values, through the use of non-negative weights in the mixing network, which guarantees consistency between the centralised and decentralised policies. To evaluate the performance of QMIX, we propose the StarCraft Multi-Agent Challenge (SMAC) as a new benchmark for deep multi-agent reinforcement learning. We evaluate QMIX on a challenging set of SMAC scenarios and show that it significantly outperforms existing multi-agent reinforcement learning methods.
Deep Multi-Agent Reinforcement Learning for Decentralized Continuous Cooperative Control
Mar 18, 2020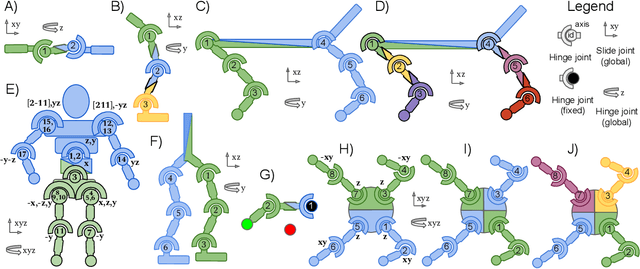
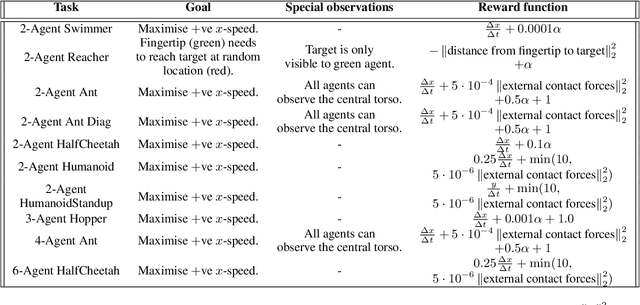
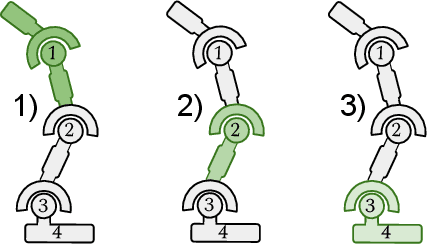
Deep multi-agent reinforcement learning (MARL) holds the promise of automating many real-world cooperative robotic manipulation and transportation tasks. Nevertheless, decentralised cooperative robotic control has received less attention from the deep reinforcement learning community, as compared to single-agent robotics and multi-agent games with discrete actions. To address this gap, this paper introduces Multi-Agent Mujoco, an easily extensible multi-agent benchmark suite for robotic control in continuous action spaces. The benchmark tasks are diverse and admit easily configurable partially observable settings. Inspired by the success of single-agent continuous value-based algorithms in robotic control, we also introduce COMIX, a novel extension to a common discrete action multi-agent $Q$-learning algorithm. We show that COMIX significantly outperforms state-of-the-art MADDPG on a partially observable variant of a popular particle environment and matches or surpasses it on Multi-Agent Mujoco. Thanks to this new benchmark suite and method, we can now pose an interesting question: what is the key to performance in such settings, the use of value-based methods instead of policy gradients, or the factorisation of the joint $Q$-function? To answer this question, we propose a second new method, FacMADDPG, which factors MADDPG's critic. Experimental results on Multi-Agent Mujoco suggest that factorisation is the key to performance.
Optimistic Exploration even with a Pessimistic Initialisation
Feb 26, 2020
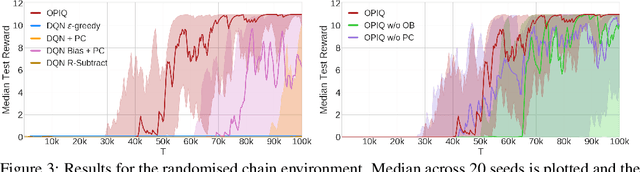
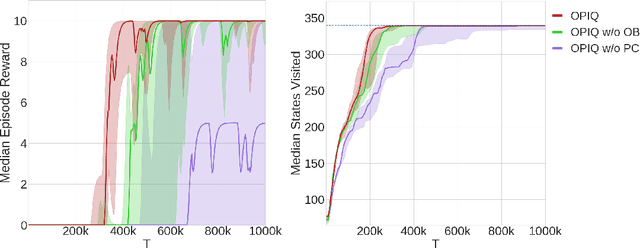

Optimistic initialisation is an effective strategy for efficient exploration in reinforcement learning (RL). In the tabular case, all provably efficient model-free algorithms rely on it. However, model-free deep RL algorithms do not use optimistic initialisation despite taking inspiration from these provably efficient tabular algorithms. In particular, in scenarios with only positive rewards, Q-values are initialised at their lowest possible values due to commonly used network initialisation schemes, a pessimistic initialisation. Merely initialising the network to output optimistic Q-values is not enough, since we cannot ensure that they remain optimistic for novel state-action pairs, which is crucial for exploration. We propose a simple count-based augmentation to pessimistically initialised Q-values that separates the source of optimism from the neural network. We show that this scheme is provably efficient in the tabular setting and extend it to the deep RL setting. Our algorithm, Optimistic Pessimistically Initialised Q-Learning (OPIQ), augments the Q-value estimates of a DQN-based agent with count-derived bonuses to ensure optimism during both action selection and bootstrapping. We show that OPIQ outperforms non-optimistic DQN variants that utilise a pseudocount-based intrinsic motivation in hard exploration tasks, and that it predicts optimistic estimates for novel state-action pairs.
Reinforcement Learning Enhanced Quantum-inspired Algorithm for Combinatorial Optimization
Feb 14, 2020
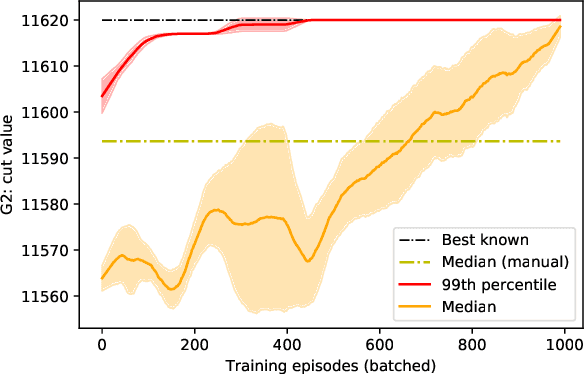

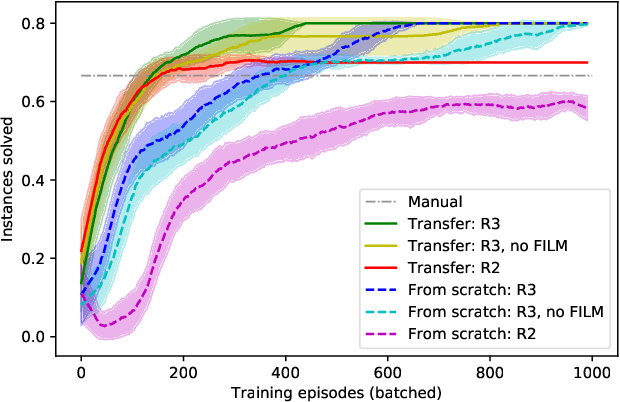
Quantum hardware and quantum-inspired algorithms are becoming increasingly popular for combinatorial optimization. However, these algorithms may require careful hyperparameter tuning for each problem instance. We use a reinforcement learning agent in conjunction with a quantum-inspired algorithm to solve the Ising energy minimization problem, which is equivalent to the Maximum Cut problem. The agent controls the algorithm by tuning one of its parameters with the goal of improving recently seen solutions. We propose a new Rescaled Ranked Reward (R3) method that enables stable single-player version of self-play training that helps the agent to escape local optima. The training on any problem instance can be accelerated by applying transfer learning from an agent trained on randomly generated problems. Our approach allows sampling high-quality solutions to the Ising problem with high probability and outperforms both baseline heuristics and a black-box hyperparameter optimization approach.
GradientDICE: Rethinking Generalized Offline Estimation of Stationary Values
Feb 07, 2020

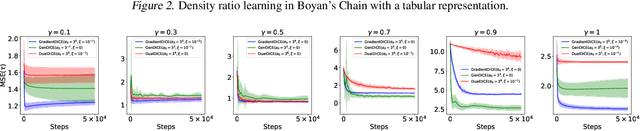

We present GradientDICE for estimating the density ratio between the state distribution of the target policy and the sampling distribution in off-policy reinforcement learning. GradientDICE fixes several problems of GenDICE (Zhang et al., 2020), the state-of-the-art for estimating such density ratios. Namely, the optimization problem in GenDICE is not a convex-concave saddle-point problem once nonlinearity in optimization variable parameterization is introduced to ensure positivity, so any primal-dual algorithm is not guaranteed to converge or find the desired solution. However, such nonlinearity is essential to ensure the consistency of GenDICE even with a tabular representation. This is a fundamental contradiction, resulting from GenDICE's original formulation of the optimization problem. In GradientDICE, we optimize a different objective from GenDICE by using the Perron-Frobenius theorem and eliminating GenDICE's use of divergence. Consequently, nonlinearity in parameterization is not necessary for GradientDICE, which is provably convergent under linear function approximation.
Facial Feedback for Reinforcement Learning: A Case Study and Offline Analysis Using the TAMER Framework
Jan 23, 2020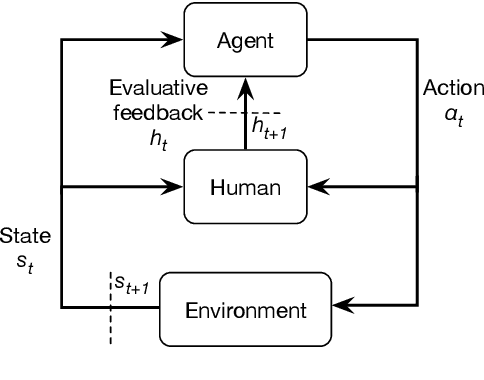
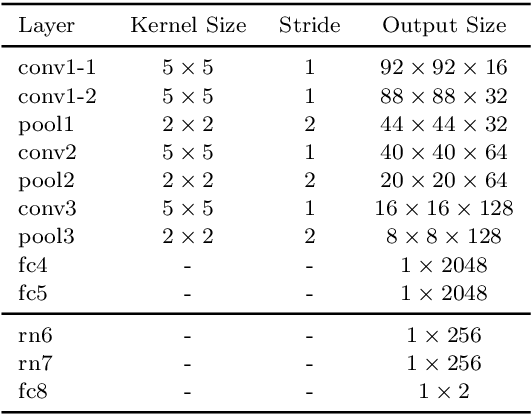
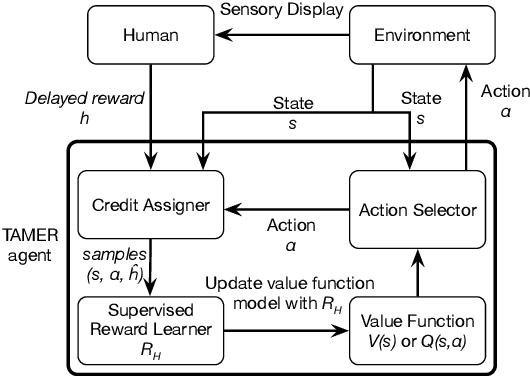
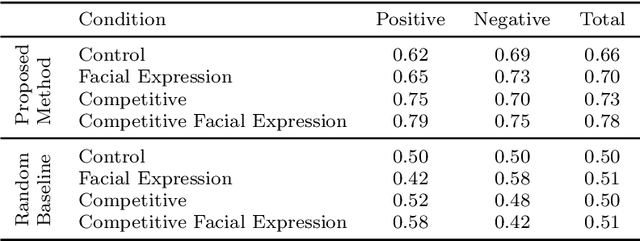
Interactive reinforcement learning provides a way for agents to learn to solve tasks from evaluative feedback provided by a human user. Previous research showed that humans give copious feedback early in training but very sparsely thereafter. In this article, we investigate the potential of agent learning from trainers' facial expressions via interpreting them as evaluative feedback. To do so, we implemented TAMER which is a popular interactive reinforcement learning method in a reinforcement-learning benchmark problem --- Infinite Mario, and conducted the first large-scale study of TAMER involving 561 participants. With designed CNN-RNN model, our analysis shows that telling trainers to use facial expressions and competition can improve the accuracies for estimating positive and negative feedback using facial expressions. In addition, our results with a simulation experiment show that learning solely from predicted feedback based on facial expressions is possible and using strong/effective prediction models or a regression method, facial responses would significantly improve the performance of agents. Furthermore, our experiment supports previous studies demonstrating the importance of bi-directional feedback and competitive elements in the training interface.
VIABLE: Fast Adaptation via Backpropagating Learned Loss
Nov 29, 2019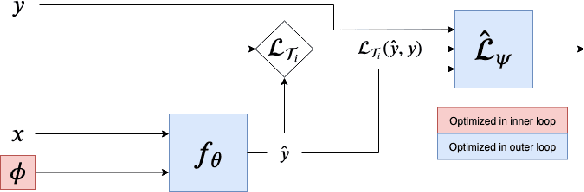
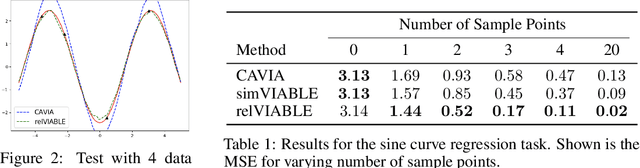
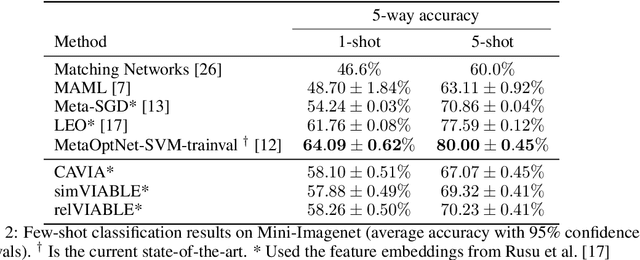
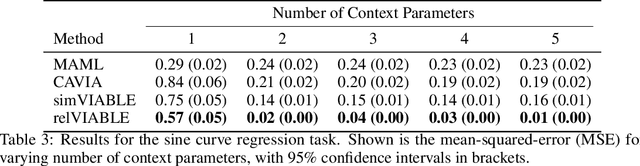
In few-shot learning, typically, the loss function which is applied at test time is the one we are ultimately interested in minimising, such as the mean-squared-error loss for a regression problem. However, given that we have few samples at test time, we argue that the loss function that we are interested in minimising is not necessarily the loss function most suitable for computing gradients in a few-shot setting. We propose VIABLE, a generic meta-learning extension that builds on existing meta-gradient-based methods by learning a differentiable loss function, replacing the pre-defined inner-loop loss function in performing task-specific updates. We show that learning a loss function capable of leveraging relational information between samples reduces underfitting, and significantly improves performance and sample efficiency on a simple regression task. Furthermore, we show VIABLE is scalable by evaluating on the Mini-Imagenet dataset.
Provably Convergent Off-Policy Actor-Critic with Function Approximation
Nov 11, 2019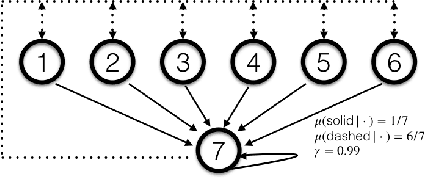
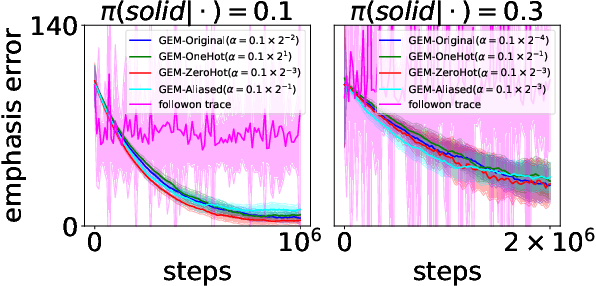
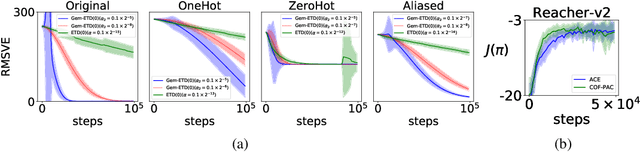
We present the first provably convergent off-policy actor-critic algorithm (COF-PAC) with function approximation in a two-timescale form. Key to COF-PAC is the introduction of a new critic, the emphasis critic, which is trained via Gradient Emphasis Learning (GEM), a novel combination of the key ideas of Gradient Temporal Difference Learning and Emphatic Temporal Difference Learning. With the help of the emphasis critic and the canonical value function critic, we show convergence for COF-PAC, where the critics are linear and the actor can be nonlinear.
VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning
Oct 18, 2019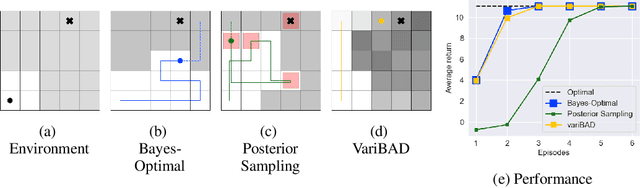
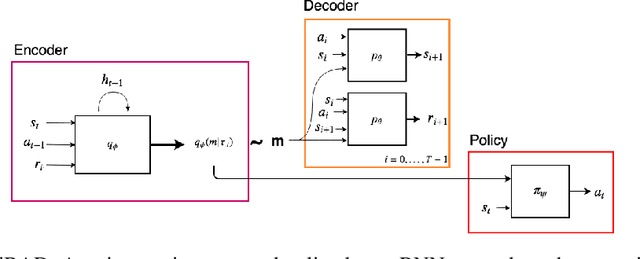
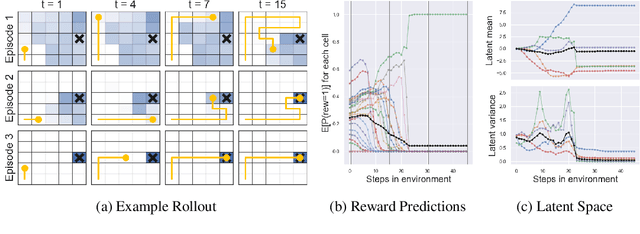
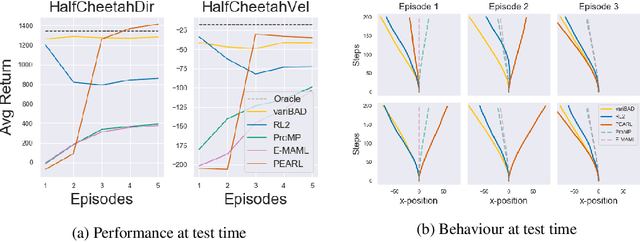
Trading off exploration and exploitation in an unknown environment is key to maximising expected return during learning. A Bayes-optimal policy, which does so optimally, conditions its actions not only on the environment state but on the agent's uncertainty about the environment. Computing a Bayes-optimal policy is however intractable for all but the smallest tasks. In this paper, we introduce variational Bayes-Adaptive Deep RL (variBAD), a way to meta-learn to perform approximate inference in an unknown environment, and incorporate task uncertainty directly during action selection. In a grid-world domain, we illustrate how variBAD performs structured online exploration as a function of task uncertainty. We also evaluate variBAD on MuJoCo domains widely used in meta-RL and show that it achieves higher return during training than existing methods.
MAVEN: Multi-Agent Variational Exploration
Oct 16, 2019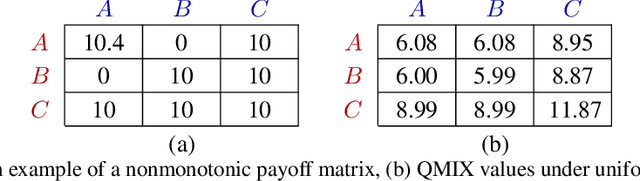
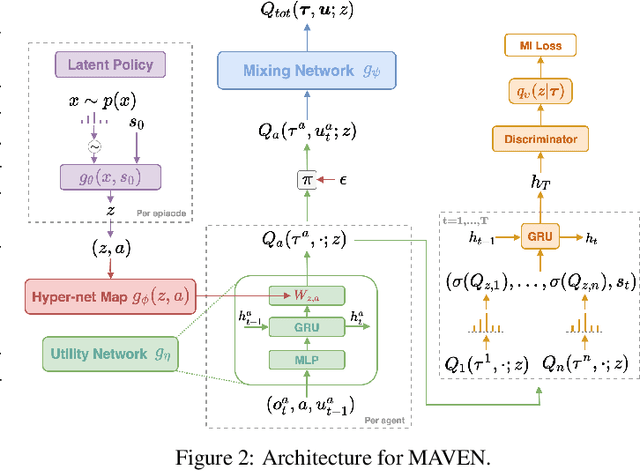
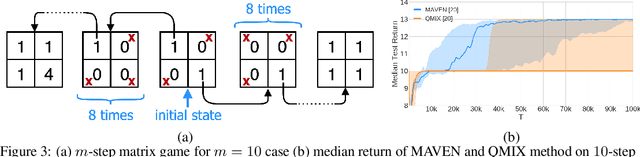

Centralised training with decentralised execution is an important setting for cooperative deep multi-agent reinforcement learning due to communication constraints during execution and computational tractability in training. In this paper, we analyse value-based methods that are known to have superior performance in complex environments [43]. We specifically focus on QMIX [40], the current state-of-the-art in this domain. We show that the representational constraints on the joint action-values introduced by QMIX and similar methods lead to provably poor exploration and suboptimality. Furthermore, we propose a novel approach called MAVEN that hybridises value and policy-based methods by introducing a latent space for hierarchical control. The value-based agents condition their behaviour on the shared latent variable controlled by a hierarchical policy. This allows MAVEN to achieve committed, temporally extended exploration, which is key to solving complex multi-agent tasks. Our experimental results show that MAVEN achieves significant performance improvements on the challenging SMAC domain [43].